Introduction pratique à l'apprentissage renforcé
Je me souviens de ma première rencontre avec le renforcement de l'apprentissage. C'était comme débloquer un nouveau niveau dans un jeu, où les algorithmes apprennent par essai et erreur, tout comme nous. Contrairement à l'apprentissage supervisé, le RL ne s'appuie pas sur des jeux de données étiquetés. Il apprend des conséquences de ses actions. D'abord, on compare le RL à l'apprentissage supervisé, puis on plonge dans ses applications réelles, notamment dans les jeux. Je vous guiderai à travers les méthodes basées sur la valeur, comme le Q-learning, et les méthodes basées sur la politique, en montrant comment ces approches transforment des modèles de langage massif. En fin de compte, vous verrez comment trois manières clés d'utiliser le RL pour affiner les grands modèles de langage offrent des résultats impressionnants.
La première fois que je suis tombé sur le renforcement de l'apprentissage, c'était un peu comme entrer dans un nouveau niveau d'un jeu vidéo. Les algorithmes qui apprennent par essais et erreurs, c'est fascinant, non ? Ce qui distingue vraiment le RL de l'apprentissage supervisé, c'est son indépendance des jeux de données étiquetés. Je connecte d'abord cette notion à l'apprentissage supervisé pour établir une base. Ensuite, je te montre les applications du RL dans le monde réel, où il brille particulièrement dans les jeux. Je te guiderai à travers les méthodes basées sur la valeur, comme le Q-learning, et les méthodes basées sur la politique. Et attention, j'ai moi-même dû réajuster mes attentes en travaillant avec ces méthodes sur de grands modèles de langage. Trois approches clés se dégagent pour affiner ces modèles massifs avec le RL, et les résultats sont souvent bluffants. Alors, prêt à plonger dans ce monde passionnant ?
Comprendre l'Apprentissage par Renforcement
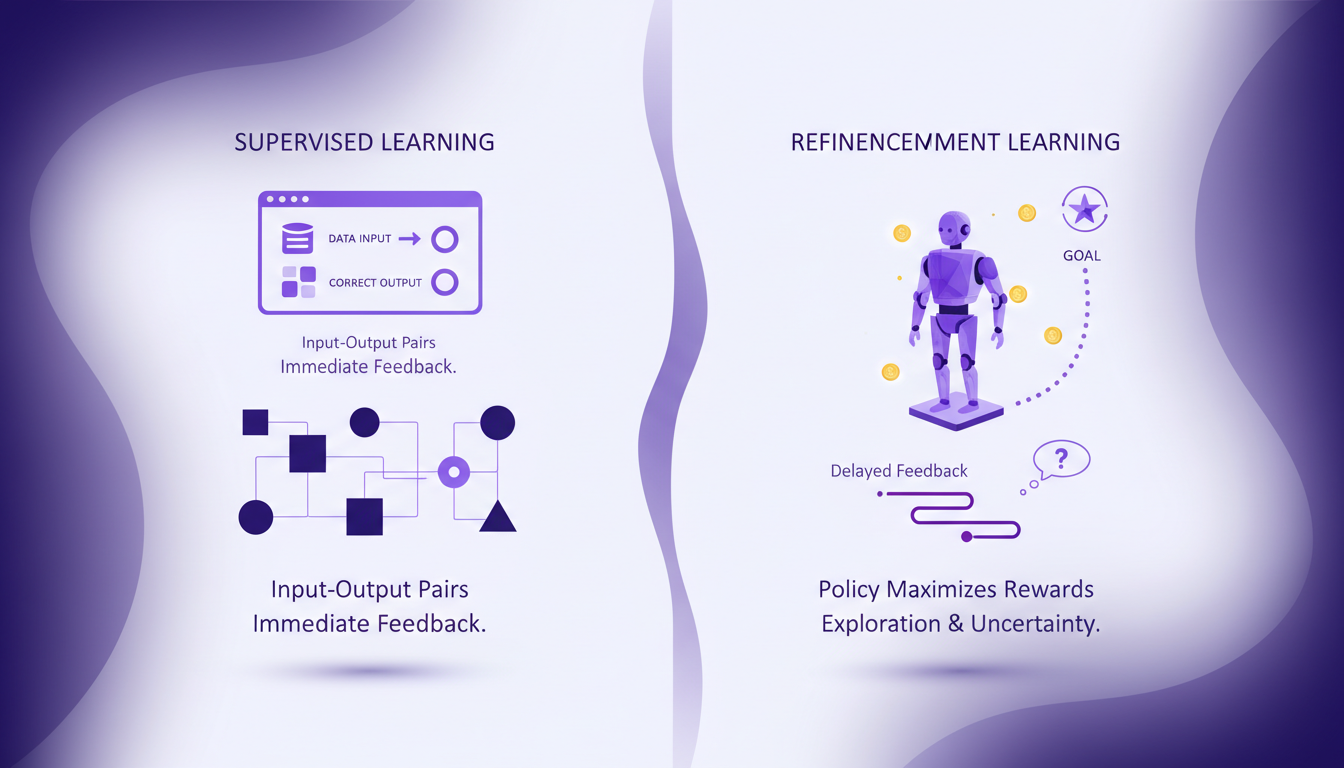
Alors voilà, l'apprentissage par renforcement (AR), c'est un autre monde comparé à l'apprentissage supervisé. On parle d'agents, d'environnements, d'actions et de récompenses. Contrairement à l'apprentissage supervisé qui s'appuie sur des étiquettes, l'AR apprend de l'environnement par l'interaction directe. Imaginez un agent dans un jeu vidéo qui essaie différentes stratégies pour obtenir le meilleur score possible. C'est ça l'AR : essayer, échouer, ajuster, et réessayer.
Les composants clés ici sont l'agent (le décideur), l'environnement (le monde autour de l'agent), la politique (la stratégie de l'agent), le signal de récompense (ce qui motive l'agent) et la fonction de valeur (évaluation des actions futures). C'est un processus itératif où l'agent apprend par essais et erreurs. J'ai souvent vu des projets échouer simplement parce que les équipes sous-estimaient le temps nécessaire pour que l'agent affine réellement sa stratégie.
Apprentissage par Renforcement vs Apprentissage Supervisé
Quand je compare l'AR à l'apprentissage supervisé, la différence la plus flagrante, c'est la dépendance aux données. L'apprentissage supervisé a besoin de tonnes de données étiquetées, des paires entrée-sortie, pour fonctionner. L'AR, lui, se concentre sur l'élaboration d'une politique qui maximise les récompenses cumulées. Mais attention, c'est un processus gourmand en ressources. J'ai souvent vu des projets AR consommer plus de puissance de calcul que prévu, surtout parce que les retours sont souvent différés, ce qui complexifie l'apprentissage.
En termes de compromis, l'AR est indéniablement plus flexible. Mais cette flexibilité a un coût : plus de ressources computationnelles et de temps. Pour choisir entre les deux, il faut vraiment peser le besoin de flexibilité contre les contraintes de ressources. Pour plus de détails, consultez cette comparaison approfondie.
Applications dans les Jeux et au-delà
Là où l'AR brille vraiment, c'est dans les environnements dynamiques comme les jeux. Prenez AlphaGo qui a surpassé le niveau Grand Maître. Mais ce n'est pas tout. L'AR trouve aussi sa place dans la robotique, les véhicules autonomes ou encore les recommandations personnalisées. Il optimise les processus décisionnels complexes de manière impressionnante. Cependant, attention aux coûts computationnels élevés et aux exigences en termes de données. J'ai vu de nombreux projets échouer à cause de ces coûts cachés.
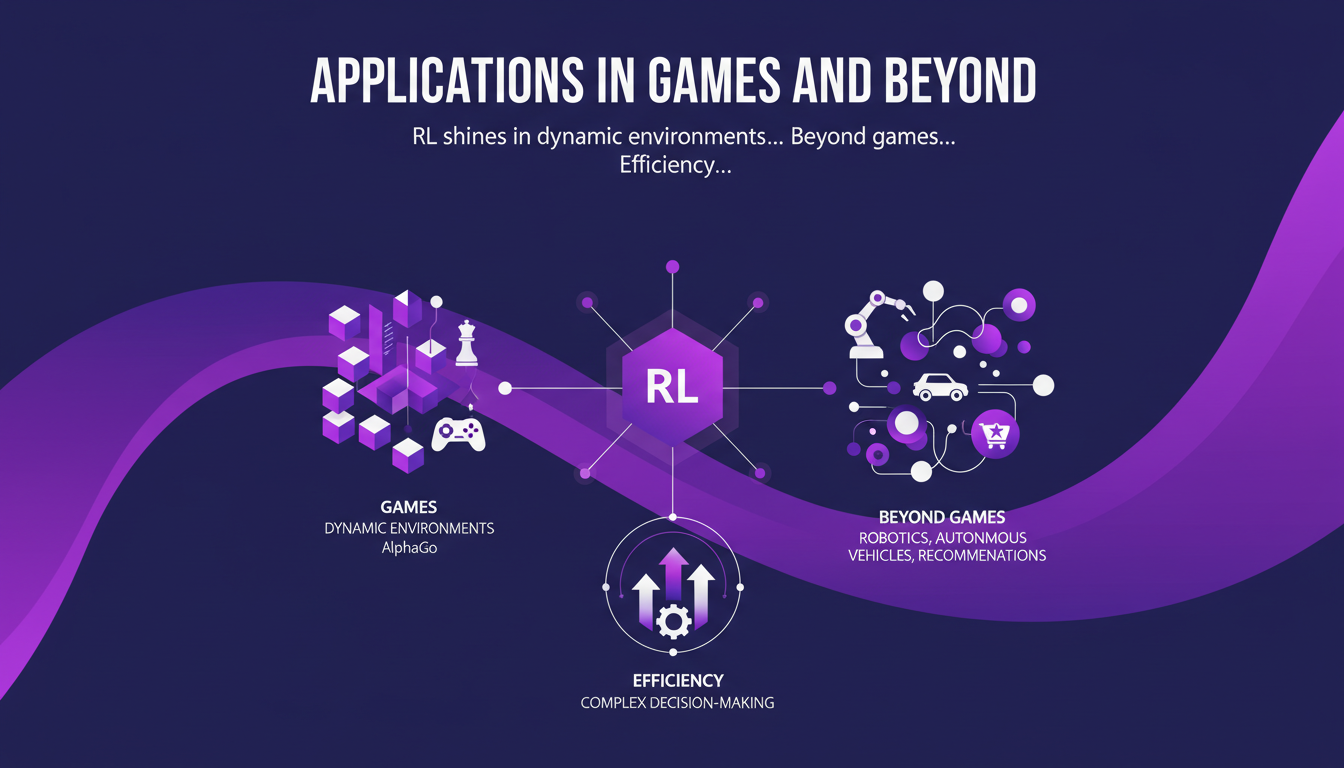
Donc, que ce soit pour des jeux comme le Go ou pour des tâches plus pratiques comme la gestion de stocks, l'AR a vraiment un impact concret. Quelques exemples notables incluent AlphaGo et le bot Dota 2 d'OpenAI. Pour des applications plus pratiques, lisez notre guide sur l'exploitation des capacités multimodales.
Méthodes Basées sur la Valeur vs Méthodes Basées sur la Politique
Les méthodes basées sur la valeur, comme le Q-learning, se concentrent sur l'évaluation des valeurs des actions possibles. En parallèle, les méthodes basées sur la politique, comme REINFORCE, optimisent directement la politique. L'approche Actor-Critic combine ces deux méthodes pour une meilleure stabilité et performance. Le choix de la méthode dépend du problème à résoudre et des ressources disponibles.

J'ai souvent vu des projets adopter une méthode sans comprendre les compromis. Par exemple, le Q-learning est puissant mais peut être lourd en calcul. Le REINFORCE, bien que plus direct, peut nécessiter de nombreux essais pour converger. Pour explorer ces méthodes, jetez un œil à notre guide pratique sur la diffusion en ML.
Apprentissage par Renforcement avec des Modèles de Langage de Grande Taille
Les modèles de langage de grande taille (LLM) utilisent l'AR pour le fine-tuning, améliorant les réponses et l'efficacité. Les trois façons clés d'y parvenir sont le façonnage des récompenses, l'optimisation des politiques, et la simulation d'environnements. Mais attention, gérer l'utilisation des tokens et la surcharge computationnelle est un vrai défi. Pourtant, les bénéfices sont clairs : des modèles de langage plus adaptatifs et contextuellement conscients.
Quand j'ai commencé à travailler avec ces modèles, j'ai souvent sous-estimé la consommation de ressources. Avec plus de 100 000 tokens dans le vocabulaire des modèles modernes, il est crucial de bien gérer les ressources. Pour découvrir comment ces techniques s'appliquent au clonage vocal, consultez notre article sur Qwen TTS.
Alors, voilà ce que j'ai vraiment appris sur l'apprentissage par renforcement (RL) :
- Premier point, le RL est vraiment un game changer pour résoudre des problèmes complexes, surtout quand tu compares ça à l'apprentissage supervisé. Mais attention, il y a des défis, notamment quand tu passes à l'échelle.
- Ensuite, pense à Q-learning. C'est un exemple concret de méthode basée sur la valeur qui peut transformer la façon dont on entraîne les modèles de langage, même ceux avec 100 000 tokens.
- Enfin, RL ne se limite pas aux jeux. Ses applications s'étendent bien au-delà, et avec les bonnes méthodes (basées sur la valeur ou la politique), tu peux vraiment faire une différence.
En regardant vers l'avenir, je suis convaincu que ces outils de RL vont continuer à évoluer et à transformer nos projets d'IA. Mais, n'oublie pas les limites : l'optimisation et le temps de calcul peuvent devenir un casse-tête.
Prêt à plonger plus profondément ? Je te conseille vraiment de commencer à expérimenter avec des frameworks RL. Partage tes expériences, et ensemble, construisons des solutions plus intelligentes. Regarde la vidéo "Reinforcement Learning: A (practical) introduction" sur YouTube pour explorer encore plus ce sujet fascinant : https://www.youtube.com/watch?v=3vFISl7qMFI.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Translate Gemma: Capacités Multimodales en Action
J'ai plongé dans Translate Gemma et, franchement, c'est un vrai game changer pour les projets multilingues. D'abord, je l'ai intégré dans mon infrastructure existante, et puis j'ai exploré ses capacités multimodales. Avec un modèle qui supporte 55 langues et des données d'entraînement couvrant 500 autres, ce n'est pas juste une question de langue—c'est une question de déploiement et d'optimisation pour vos besoins. Je vous montre comment j'ai fait pour que ça fonctionne efficacement, en passant par la comparaison des variantes de modèles, le processus d'entraînement et les options de déploiement. Attention aux tailles des modèles : 4 milliards, 12 milliards, jusqu'à 27 milliards de paramètres—c'est du lourd. Alors, prêt à voir comment je l'ai utilisé avec Kaggle et Hugging Face ?
Cloner des Voix Gratuitement : Qwen TTS Révolutionne
Je me souviens de la première fois où j'ai cloné une voix avec Qwen TTS — c'était comme entrer dans le futur. Imaginez avoir un outil aussi puissant, et en plus open source, à portée de main. Ce n'est pas juste de la théorie; c'est l'application concrète de cette technologie aujourd'hui. En juin dernier, Qwen a dévoilé ses modèles TTS, et d'ici septembre, le Quen 3 TTS Flash avec support multilingue était prêt. Pour quiconque s'intéresse au clonage de voix et à la génération de discours multilingues, c'est un véritable game changer. Avec des modèles allant de 0,6 milliard à 1,7 milliard de paramètres, les possibilités sont énormes. Mais attention, il y a des limites techniques à garder à l'esprit. Dans cet article, je vais vous guider à travers les capacités multilingues, la libération open-source, et la synthèse émotionnelle. Préparez-vous à explorer comment vous pouvez exploiter cette technologie dès aujourd'hui.

Optimisez les agents profonds avec /remember
J'ai passé d'innombrables heures à peaufiner les configurations des agents profonds, et je peux vous dire que la commande /remember est un véritable changement de jeu. C'est comme donner à votre agent un cerveau qui retient vraiment les informations utiles. Laissez-moi vous montrer comment je l'utilise pour rationaliser les processus et améliorer l'efficacité. Avec la commande /remember dans le CLI des agents profonds, vous pouvez enseigner aux agents à apprendre de l'expérience. On va plonger dans le fonctionnement de tout ça et pourquoi c'est un indispensable dans votre arsenal.
Techniques Diffusion ML: Appliquées et Optimisées
Depuis que je suis plongé dans le machine learning en 2012, j'ai vu des techniques venir et partir, mais les modèles de diffusion sont un vrai changement de jeu. Et ce n'est pas juste pour les académiciens—je parle d'applications concrètes qui peuvent transformer votre flux de travail. La diffusion en ML n'est pas un simple mot à la mode. C'est un cadre fondamental qui redéfinit notre approche de l'IA, de la modélisation d'images au traitement de données complexes. Pour les fondateurs et les praticiens, comprendre et appliquer ces techniques peut vous faire gagner du temps et augmenter votre efficacité. Avec seulement 15 lignes de code, vous pouvez mettre en place un processus de machine learning puissant. Si vous êtes prêt à explorer l'avenir de l'IA, c'est le moment de maîtriser la diffusion.
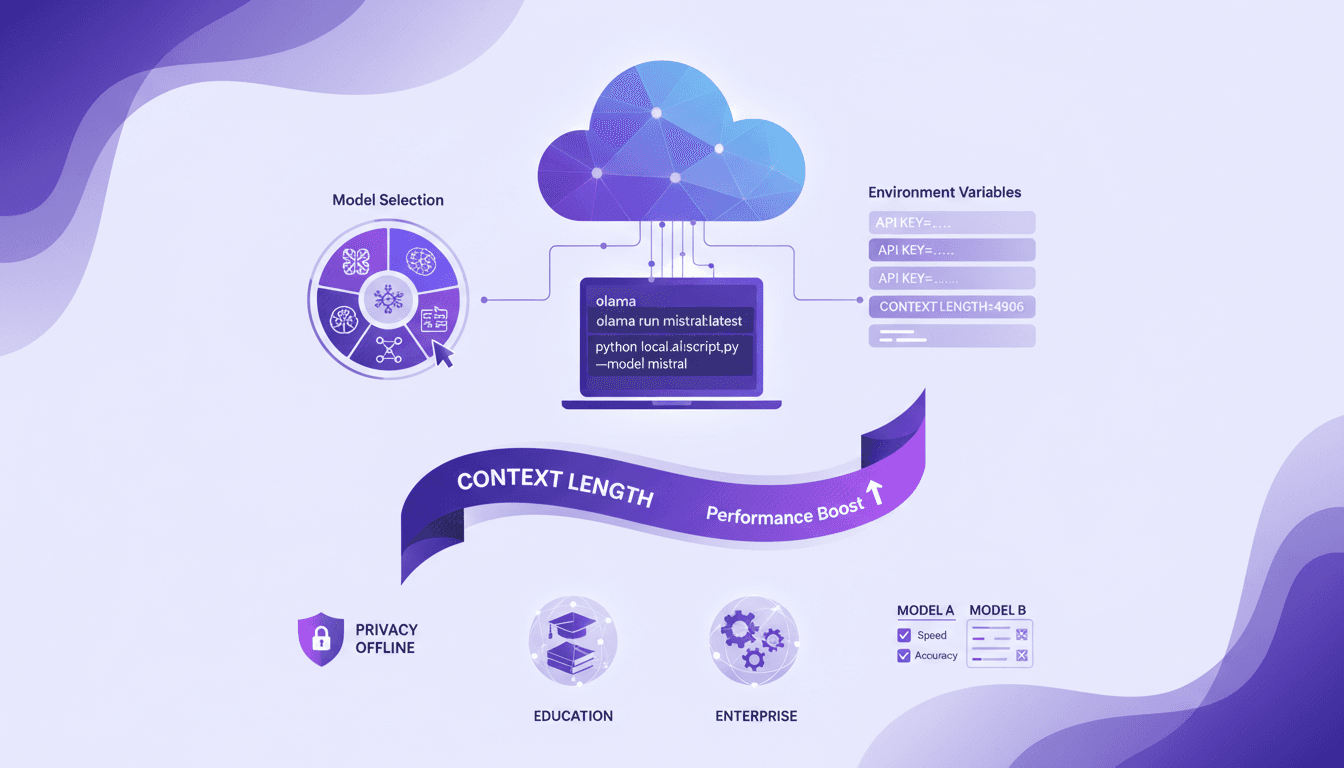
Exécuter du Code Cloud avec Olama: Tutoriel
J'ai commencé à exécuter du code cloud en local pour booster l'efficacité et la confidentialité, et Olama a été un véritable game changer. Imaginez pouvoir manipuler des modèles IA avec 4 milliards de paramètres, le tout sans quitter votre bureau. Je vais vous montrer comment j'ai configuré tout ça, de la sélection des modèles à l'ajustement des variables d'environnement, et pourquoi ça change la donne pour l'éducation et les entreprises. Mais attention aux limites de contexte : au-delà de 100K tokens, ça se complique. En utilisant Olama, on peut comparer différents modèles IA pour une utilisation locale tout en assurant une confidentialité renforcée et des capacités hors ligne. L'idée ici, c'est de vous donner un aperçu pratique et direct de la façon dont je pilote ces technologies dans mon quotidien professionnel.