Optimisez les agents profonds avec /remember
J'ai passé d'innombrables heures à peaufiner les configurations des agents profonds, et je peux vous dire que la commande /remember est un véritable changement de jeu. C'est comme donner à votre agent un cerveau qui retient vraiment les informations utiles. Laissez-moi vous montrer comment je l'utilise pour rationaliser les processus et améliorer l'efficacité. Avec la commande /remember dans le CLI des agents profonds, vous pouvez enseigner aux agents à apprendre de l'expérience. On va plonger dans le fonctionnement de tout ça et pourquoi c'est un indispensable dans votre arsenal.

J'ai passé des heures interminables à peaufiner les configurations des agents profonds, et croyez-moi, la commande /remember a changé la donne. C'est presque comme doter votre agent d'un cerveau qui retient vraiment les informations utiles. Je vais vous montrer comment je l'utilise pour rationaliser les tâches et booster l'efficacité. Comprendre comment les agents apprennent et stockent des informations peut être un vrai casse-tête. Mais avec la commande /remember dans le CLI des agents profonds, on peut enseigner aux agents à apprendre de l'expérience. C'est comme leur donner une mémoire automatique qui se met à jour sans cesse. Vous allez voir, en trois étapes simples, on peut capturer et stocker des connaissances, créer des compétences et mettre à jour la mémoire grâce au CLI. Je vais même vous montrer la commande en action, et vous verrez pourquoi elle est indispensable dans votre arsenal. Alors, prêt à transformer la façon dont vos agents apprennent ?
Comprendre la Commande /remember
Je me souviens de la première fois où j'ai vraiment compris l'importance de la deep agent CLI pour améliorer les capacités des agents. La commande /remember agit comme un outil de mémoire, permettant aux agents d'apprendre de leurs interactions passées. Quand on parle de système de fichiers mémoire pour agents, c'est là que le agents.md entre en jeu. Il sert de stockage persistant, crucial pour l'apprentissage continu des agents. Si on veut que nos agents soient plus qu'une simple interface, il faut leur donner la capacité de retenir l'information et de s'en servir plus tard.

Le stockage persistant n'est pas qu'un luxe, c'est une nécessité. Sans lui, l'agent ne peut pas vraiment évoluer ou s'améliorer. J'ai vu des configurations où l'absence de mémoire persistante limitait sévèrement l'efficacité de l'agent. C'est un peu comme un humain qui n'aurait pas de mémoire à long terme. Ça ne fonctionne pas.
Le Processus en Trois Étapes de /remember
Le processus /remember en trois étapes est simple mais puissant. D'abord, on initie la commande avec des paramètres précis. Il faut savoir exactement ce qu'on veut que l'agent retienne. Ensuite, on capture les données pertinentes et on les stocke. La magie opère quand l'agent s'approprie ces informations et les utilise pour améliorer ses réponses futures.
Enfin, les mises à jour et la récupération de la mémoire stockée se font automatiquement. Mais attention, il y a des considérations clés à prendre en compte à chaque étape. Par exemple, une mauvaise configuration initiale peut entraîner des erreurs de mémoire, et croyez-moi, ça peut vite devenir un casse-tête.
Les Mises à Jour Automatiques de la Mémoire : Un Regard Approfondi
Les mises à jour automatiques de la mémoire sont un atout pour améliorer les performances des agents. Toutefois, il y a des limites et des compromis à prendre en compte. Par exemple, l'agent peut ne pas toujours interpréter correctement ce qui doit être retenu. Pour gérer cela efficacement, j'ai mis en place des stratégies spécifiques.
Dans le monde réel, utiliser ces mises à jour automatiques a eu un impact direct sur l'efficacité de mes agents, surtout dans des tâches répétitives où l'apprentissage continu est crucial.
Créer des Compétences et Mettre à Jour la Mémoire
Utiliser la CLI pour créer de nouvelles compétences pour les agents est un jeu d'enfant avec la commande /remember. Mais attention, il y a des défis à relever. J'ai souvent dû jongler entre la création de nouvelles compétences et la capacité mémoire limitée des agents.
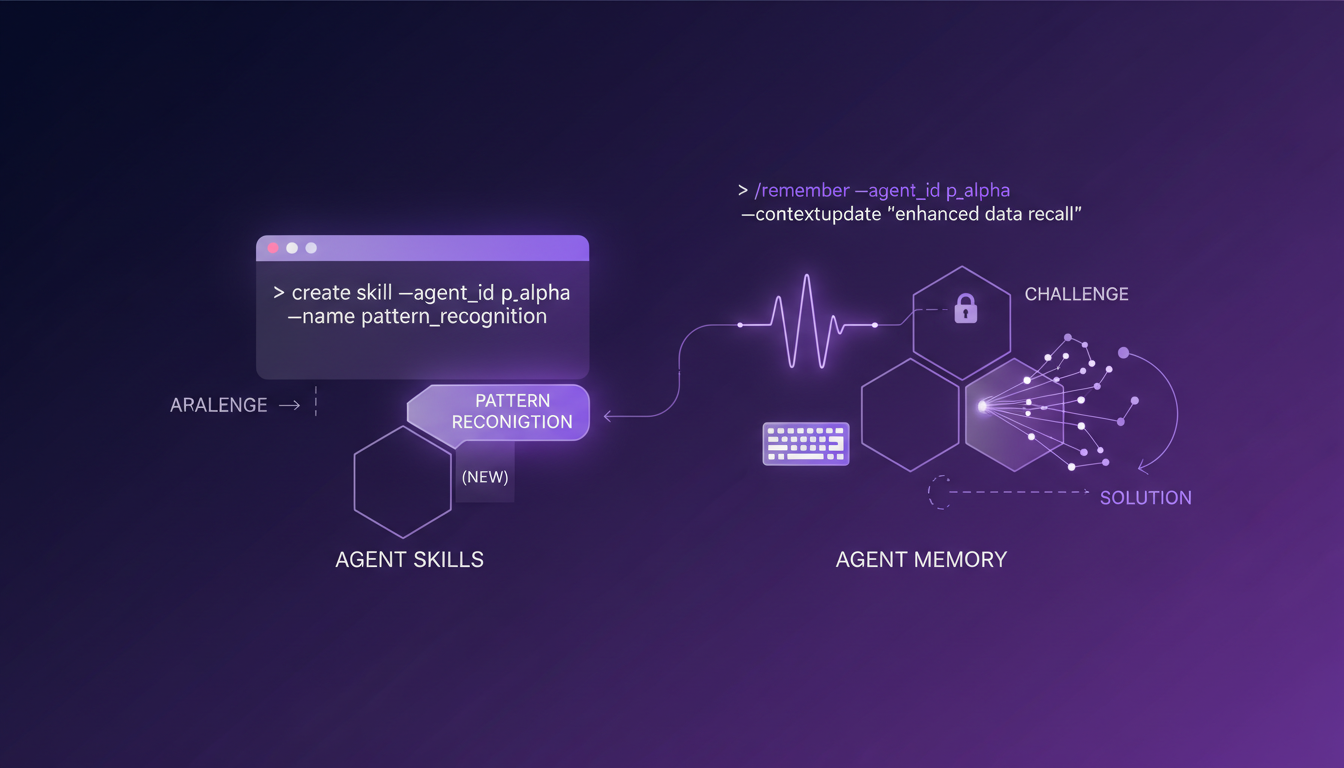
Pour équilibrer cela, je m'assure de bien prioriser quelles compétences sont essentielles et doivent être mises à jour en priorité. Cela m'a évité bien des migraines et a permis de garder mes agents performants et réactifs.
Démonstration : La Commande /remember en Action
Voyons maintenant un exemple concret de la mise en place et de l'utilisation de la commande /remember. Lors d'une mise en œuvre, j'ai appris à éviter certains pièges courants, comme la surcharge d'informations non pertinentes. C'est essentiel pour mesurer l'impact sur l'efficacité de l'agent.

Les résultats ont été immédiats : une amélioration notable de la réactivité de l'agent et une réduction du temps passé à réexpliquer les préférences. Voilà le pouvoir de la mémoire bien utilisée.
Alors là, si tu ne vois pas encore comment la commande /remember peut transformer tes workflows d'agent, il est temps de te lancer vraiment. Je l'ai intégrée en trois étapes simples et l'impact est direct. C'est comme donner une vraie mémoire à tes agents, qui se mettent à jour automatiquement. Attention quand même, il ne faut pas surcharger la mémoire avec des infos inutiles, sinon tu perds en efficacité.
- Mets en place la commande /remember en trois étapes simples.
- Observe comment tes agents peuvent apprendre et stocker des connaissances automatiquement.
- Ne surcharge pas la mémoire de l'agent avec des données superflues.
En avant, une fois que tu l'as configurée, tu verras rapidement une différence dans la performance de tes agents. C'est un vrai game changer pour l'efficacité, mais reste vigilant sur la gestion des données.
Si tu veux vraiment comprendre comment ça marche et l'intégrer au mieux, je te conseille de regarder la vidéo complète. C'est comme un manuel pratique qui t'évite les erreurs de débutant. Regarde la vidéo ici.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Techniques Diffusion ML: Appliquées et Optimisées
Depuis que je suis plongé dans le machine learning en 2012, j'ai vu des techniques venir et partir, mais les modèles de diffusion sont un vrai changement de jeu. Et ce n'est pas juste pour les académiciens—je parle d'applications concrètes qui peuvent transformer votre flux de travail. La diffusion en ML n'est pas un simple mot à la mode. C'est un cadre fondamental qui redéfinit notre approche de l'IA, de la modélisation d'images au traitement de données complexes. Pour les fondateurs et les praticiens, comprendre et appliquer ces techniques peut vous faire gagner du temps et augmenter votre efficacité. Avec seulement 15 lignes de code, vous pouvez mettre en place un processus de machine learning puissant. Si vous êtes prêt à explorer l'avenir de l'IA, c'est le moment de maîtriser la diffusion.
Créer des Agents Sans Code: LangSmith Agent Builder
Je me suis plongé dans le LangSmith Agent Builder en m'attendant à une configuration complexe. Finalement, j'ai trouvé une approche simplifiée pour créer des agents prêts pour la production sans écrire une seule ligne de code. Cette nouvelle formation de LangChain Academy, Agent Builder Essentials, est un véritable game changer pour quiconque cherche à automatiser des tâches efficacement. On parle ici de raisonnement en temps réel et de prise de décision avec des agents no-code. Je vais vous expliquer comment ça fonctionne et comment cela peut booster votre productivité.

Construire avec LangSmith : Points Techniques Clés
Je me suis plongé dans le LangSmith Agent Builder, et immédiatement, le terme 'Heat' est revenu encore et encore. Ce n'était pas juste du bruit de fond; c'était un véritable game changer. Je vais vous montrer comment j'ai utilisé 'Heat' pour rationaliser mes flux de travail. Comprendre cette fonctionnalité est crucial pour tirer le meilleur parti de LangSmith. Mon approche, ce qui a marché et ce qui n'a pas marché, tout est là. Si, comme moi, vous êtes toujours à la recherche d'efficacité et de gains de temps, cette exploration pratique du 'Heat' pourrait bien changer la donne pour vous aussi.
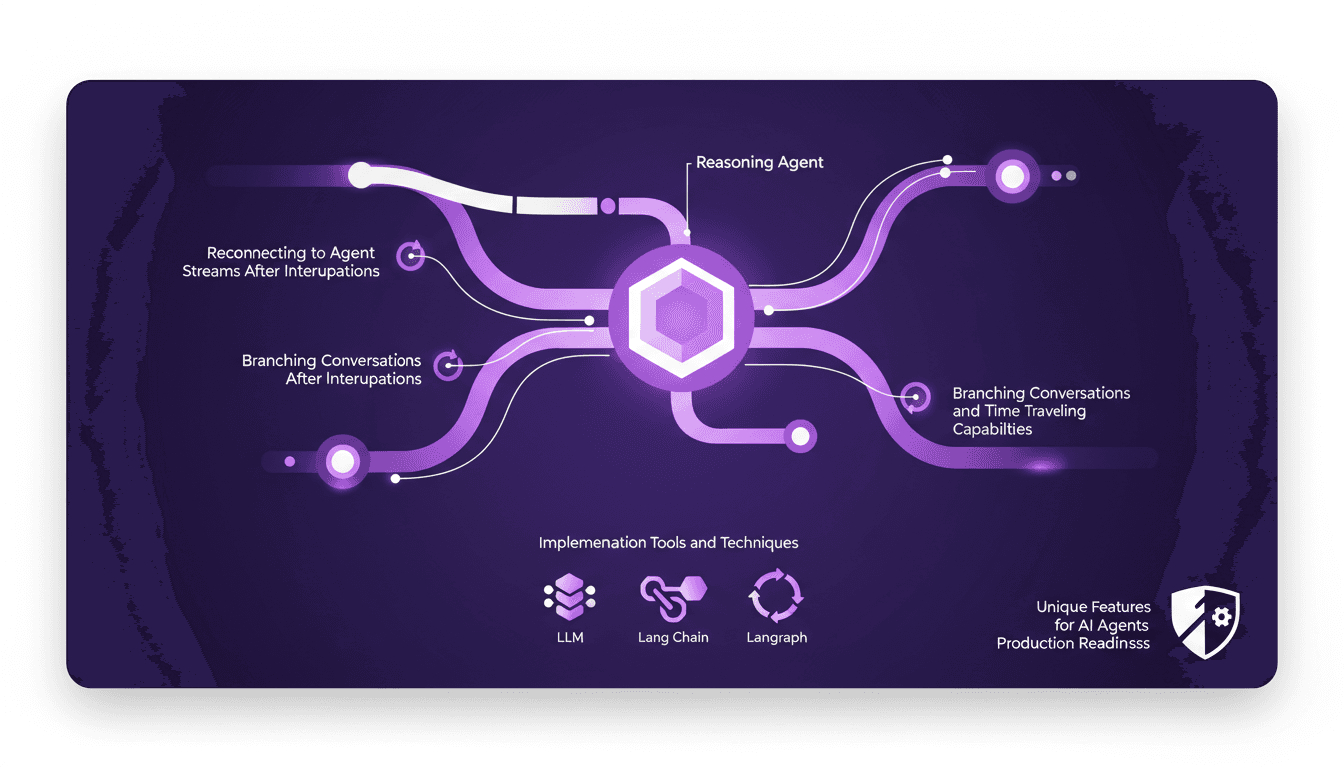
Fonctionnalités cachées pour agents IA prêts
J'ai passé d'innombrables heures sur le terrain à peaufiner des agents IA qui ne se contentent pas d'être intelligents, mais qui sont vraiment prêts pour la production. Plongeons dans trois fonctionnalités cachées qui ont réellement changé la donne dans mon workflow. Vous savez, les agents IA évoluent rapidement, mais les rendre robustes pour des applications réelles nécessite de creuser plus profondément dans des fonctionnalités moins connues. Voici comment j'exploite ces capacités pour améliorer l'efficacité et la fiabilité. On parle ici de la manière dont j'utilise les agents de raisonnement et les processus de pensée en streaming, la reconnexion aux flux d'agents après des interruptions, et les conversations à embranchements avec des capacités de voyage dans le temps. Si vous cherchez à rendre vos agents IA prêts pour la production, ces fonctionnalités uniques sont indispensables.
Apple abandonne OpenAI : Collaboration avec Google
J'ai plongé dans l'univers de l'IA, et la dernière manœuvre d'Apple a fait grand bruit. Imaginez : Apple délaisse OpenAI pour collaborer avec Google sur leurs modèles d'IA. C'est un virage qui pourrait bouleverser le jeu, et je vous explique pourquoi. D'abord, comprendre la stratégie d'Apple : pourquoi s'éloigner d'OpenAI ? La clé réside dans l'intégration des modèles de Google comme Gemini 3 Pro et VO 3.0. J'ai moi-même expérimenté les frameworks comme MLX d'Apple, et la différence est frappante. On va aussi regarder l'historique des alliances d'Apple avec Google, et ce que cela implique pour l'avenir du développement de l'IA, notamment les enjeux de confidentialité. Bref, un vrai tournant stratégique, et je vous embarque dans l'analyse.