Exécuter du Code Cloud avec Olama: Tutoriel
J'ai commencé à exécuter du code cloud en local pour booster l'efficacité et la confidentialité, et Olama a été un véritable game changer. Imaginez pouvoir manipuler des modèles IA avec 4 milliards de paramètres, le tout sans quitter votre bureau. Je vais vous montrer comment j'ai configuré tout ça, de la sélection des modèles à l'ajustement des variables d'environnement, et pourquoi ça change la donne pour l'éducation et les entreprises. Mais attention aux limites de contexte : au-delà de 100K tokens, ça se complique. En utilisant Olama, on peut comparer différents modèles IA pour une utilisation locale tout en assurant une confidentialité renforcée et des capacités hors ligne. L'idée ici, c'est de vous donner un aperçu pratique et direct de la façon dont je pilote ces technologies dans mon quotidien professionnel.
Exécuter du code cloud en local, c'est un peu comme avoir un superpouvoir dans votre propre bureau — et Olama est l'outil qui m'a permis de le faire. J'ai commencé à jouer avec des modèles IA de 4 milliards de paramètres, et laissez-moi vous dire, c'est un game changer pour les applications éducatives et d'entreprise. Je vais vous montrer comment j'ai tout mis en place, étape par étape, en commençant par le choix des modèles et en passant par la configuration des variables d'environnement. Mais attention, il y a des pièges à éviter : si vous dépassez 100K tokens, ça peut devenir un cauchemar. En utilisant Olama, non seulement on peut comparer différentes approches IA pour une utilisation locale, mais on bénéficie aussi d'une confidentialité accrue et de capacités hors ligne. Je vais même vous donner le détail technique et les commandes que j'utilise pour orchestrer tout ça. Ça a un impact direct sur mon efficacité au quotidien, et je suis convaincu que ça peut vous aider aussi.
Configurer Votre Environnement Local avec Olama
Déjà, si vous voulez exécuter des modèles d'IA localement sans dépenser un centime, Olama est votre meilleur allié. Je me suis retrouvé à télécharger et installer Olama sur ma machine, et je vous conseille de faire de même. Assurez-vous d'avoir la dernière version pour éviter les ennuis. Une fois installé, ouvrez Olama et configurez les variables d'environnement pour des performances optimales. Par exemple, Olama sert les modèles localement sur le port 1434. C'est crucial, croyez-moi, car sans ça, vous aurez des soucis à faire fonctionner votre modèle avec Claude Code.
Les problèmes de configuration peuvent surgir, alors soyez vigilant. J'ai eu quelques pépins avec les variables d'environnement qui n'étaient pas correctement définies. Assurez-vous de bien définir votre anthropic o token et anthropic base URL. Si Olama ne fonctionne pas comme prévu, vérifiez que le modèle est bien servi sur le port 1434. Sans ça, votre cloud code ne pourra pas accéder au modèle.
Sélection et Exécution de Modèles d'IA Localement
Après avoir configuré votre environnement, la prochaine étape est de choisir le bon modèle. Avec Olama, vous avez le choix entre plusieurs modèles, comme le GLM 4.7 flash qui fait 19 GB avec 4 milliards de paramètres. Ce modèle est idéal si vous avez une machine puissante, mais attention, ne téléchargez pas ça sur un vieux PC ! Personnellement, j'ai opté pour le modèle Quen 3 avec ses 4 milliards de paramètres. Pas besoin d'une bête de course pour celui-ci, mais il reste performant.
Pensez à exécuter des commandes cloud code localement pour tester l'efficacité du modèle choisi. J'ai personnellement exécuté des scripts qui comptaient le nombre de fichiers dans mon dossier racine. Ça a pris 2 minutes 23 secondes pour le faire, un peu lent, mais ça m'a donné la bonne réponse. Le choix du modèle impacte directement les capacités de réflexion et d'outillage.
Le Rôle de la Longueur de Contexte dans la Performance des Modèles d'IA
La longueur de contexte, c'est crucial. Si vous posez des questions complexes, vous avez besoin d'un modèle avec une longueur de contexte adéquate, genre 32,000 ou 64,000 tokens. Ça impacte directement la capacité du modèle à « réfléchir ». J'ai vu des modèles échouer lamentablement car la longueur de contexte était trop courte. Donc, équilibre entre longueur de contexte et ressources est essentiel.
Dans le monde réel, utilisez un contexte plus long pour des tâches complexes, mais gardez à l'esprit que ça peut consommer énormément de mémoire et ralentir les choses.
Applications des Modèles d'IA Locaux dans l'Éducation et l'Entreprise
Les modèles d'IA locaux ne sont pas juste un gadget pour les geeks. Dans l'éducation, ils peuvent transformer la manière dont nous abordons l'apprentissage. Imaginez un prof qui utilise un modèle IA local pour générer des exercices personnalisés. C'est un game changer !
Dans le monde de l'entreprise, la confidentialité et le contrôle sont des atouts majeurs. Vous ne voulez pas que vos données sensibles soient exposées à des services cloud, n'est-ce pas ? Avec Olama, vous gardez tout en local, sans sacrifier les performances. Cependant, attention aux limitations techniques : une mise en œuvre locale nécessite des ressources adéquates et une certaine expertise technique.
Commandes Techniques et Flux de Travail avec Olama
J'ai orchestré mon flux de travail pour maximiser l'efficacité et réduire les coûts. La clé est de bien comprendre les commandes à exécuter. Par exemple, pour configurer Olama, vous commencez par ouvrir votre terminal et exécuter des commandes spécifiques selon votre système d'exploitation.
Voici un aperçu rapide :
- Assurez-vous que cloud code est ajouté à votre chemin.
- Définissez correctement vos variables d'environnement.
- Évitez les pièges classiques comme l'oubli de lancer Olama sur le bon port.
L'intégration avec les systèmes existants peut être un casse-tête, mais une fois que tout est en place, les gains en efficacité sont immédiats. Ne sous-estimez pas l'importance de ces étapes pour un fonctionnement fluide.
J'ai plongé dans l'installation de modèles d'IA localement avec Olama, et les avantages se sont révélés rapidement : confidentialité renforcée et efficacité accrue. Mais attention, il faut bien choisir ses modèles. Par exemple, avec le modèle GLM 4.7 flash de 19 Go et ses 4 milliards de paramètres, on peut vraiment sentir la puissance, mais aussi la nécessité d'optimiser son environnement. J'ai aussi appris que la longueur du contexte est cruciale pour la performance, donc à ne pas négliger.
- Sélection des modèles : Choisir les bons outils et modèles est essentiel pour maximiser les performances.
- Configuration des variables d'environnement : Une étape clé pour faire tourner vos modèles d'IA localement.
- Durée d'exécution : Compter les fichiers dans le dossier racine a pris 2 minutes 23 secondes, une bonne référence pour évaluer vos propres performances.
En regardant vers l'avenir, je vois une multitude de possibilités à explorer, que ce soit en éducation ou en entreprise. Alors, prêt à démarrer ? Plongez dans la configuration et découvrez le potentiel des modèles d'IA locaux dans votre contexte. Pour approfondir, je vous recommande de regarder la vidéo complète : Claude Code for Free using Local AI Models. Vous y trouverez des astuces pratiques pour aller encore plus loin.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Translate Gemma: Capacités Multimodales en Action
J'ai plongé dans Translate Gemma et, franchement, c'est un vrai game changer pour les projets multilingues. D'abord, je l'ai intégré dans mon infrastructure existante, et puis j'ai exploré ses capacités multimodales. Avec un modèle qui supporte 55 langues et des données d'entraînement couvrant 500 autres, ce n'est pas juste une question de langue—c'est une question de déploiement et d'optimisation pour vos besoins. Je vous montre comment j'ai fait pour que ça fonctionne efficacement, en passant par la comparaison des variantes de modèles, le processus d'entraînement et les options de déploiement. Attention aux tailles des modèles : 4 milliards, 12 milliards, jusqu'à 27 milliards de paramètres—c'est du lourd. Alors, prêt à voir comment je l'ai utilisé avec Kaggle et Hugging Face ?
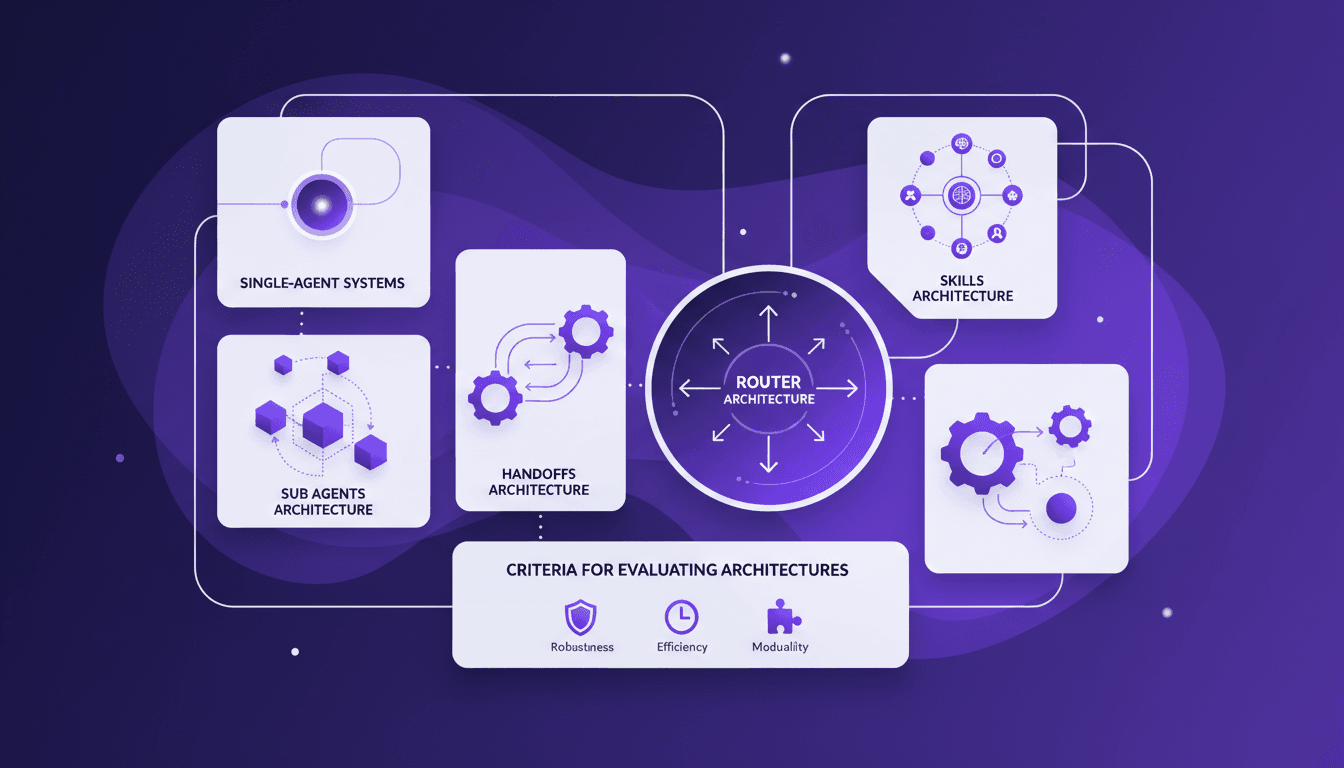
Architecture multi-agents : guide pratique
Je me souviens de la première fois où j'ai essayé d'implémenter un système multi-agents. J'étais submergé par le choix des architectures. Après quelques erreurs, j'ai finalement trouvé un workflow qui fonctionne. Parlons de comment vous pouvez choisir la bonne architecture sans maux de tête. Les systèmes multi-agents peuvent vraiment transformer la façon dont nous gérons des tâches complexes. Avec la bonne architecture, on peut distribuer efficacement la charge de travail et améliorer l'interaction. Mais attention, choisir la mauvaise peut vite devenir un cauchemar en termes d'efficacité et de scalabilité. Dans cet article, je partage mes expériences avec les architectures d'agents secondaires, de handoffs, de compétences et de routeurs. On discutera aussi des critères d'évaluation des architectures et pourquoi il peut être judicieux de commencer par un système mono-agent. Je vous partage mes erreurs et mes réussites pour que vous puissiez éviter les pièges. Prêt à plonger ?
Adoption rapide de Cloud Code : Pourquoi ça change tout
J'ai commencé à utiliser Cloud Code en 2026, et franchement, ça a bouleversé ma manière de coder. Au début, j'étais sceptique—encore un outil de plus qui promet de révolutionner le développement. Mais ensuite, j'ai vu l'interface au niveau commande en action, et j'ai compris. Cloud Code devient rapidement l'outil incontournable pour les développeurs. Ce n'est pas juste une question d'écrire du code, c'est une véritable transformation de notre approche du développement. Dans cet article, je vous explique pourquoi tant de gens effectuent le switch et comment vous pouvez exploiter cette puissance. On va aborder l'adoption rapide de Cloud Code, son interface unique, et comment l'écosystème s'élargit. Ne manquez pas ça si vous voulez garder une longueur d'avance!
Construire une Entreprise IA pour 1$ en 2026
J'ai démarré mon entreprise IA avec seulement un dollar. Ça semble dingue ? Eh bien, en 2026, grâce aux outils IA, c'est non seulement possible, mais aussi pratique. J'ai tout orchestré avec des plateformes de dropshipping, des stratégies de marketing influencées par les influenceurs et des listes de diffusion. Chaque dollar compte, surtout quand il s'agit d'intelligence artificielle et de branding. En utilisant des essais gratuits et des outils comme AutoDS, j'ai pu transformer ce dollar initial en ventes qui rapportent des milliers chaque mois. Je vais vous montrer comment j'ai fait, étape par étape, pour que vous puissiez aussi vous lancer dans cette aventure.
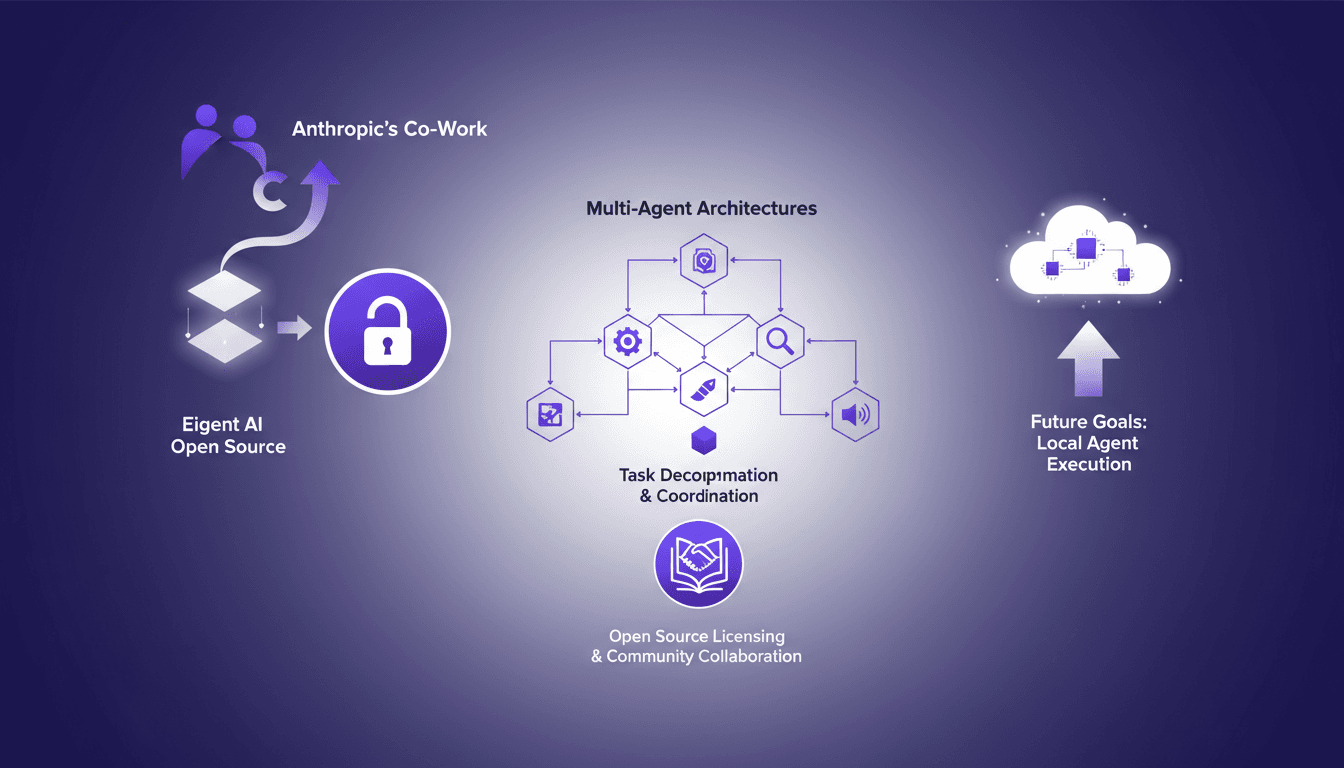
Projets Open Source: Eigent AI défie Claude Cowork
Je me souviens du jour où Eigent AI a décidé d'ouvrir notre produit en open source. C'était un pari audacieux, motivé par la sortie du co-work d'Anthropic. Cette décision a transformé notre approche des architectures multi-agents. En ouvrant notre architecture, nous voulions tirer parti de la collaboration communautaire et améliorer nos systèmes multi-agents. Le défi était de taille mais les résultats ont été à la hauteur, notamment en termes de décomposition de tâches et de coordination via DAG. Si vous vous demandez comment cela a bouleversé notre processus de développement, plongeons ensemble dans cette transformation.