Translate Gemma: Capacités Multimodales en Action
J'ai plongé dans Translate Gemma et, franchement, c'est un vrai game changer pour les projets multilingues. D'abord, je l'ai intégré dans mon infrastructure existante, et puis j'ai exploré ses capacités multimodales. Avec un modèle qui supporte 55 langues et des données d'entraînement couvrant 500 autres, ce n'est pas juste une question de langue—c'est une question de déploiement et d'optimisation pour vos besoins. Je vous montre comment j'ai fait pour que ça fonctionne efficacement, en passant par la comparaison des variantes de modèles, le processus d'entraînement et les options de déploiement. Attention aux tailles des modèles : 4 milliards, 12 milliards, jusqu'à 27 milliards de paramètres—c'est du lourd. Alors, prêt à voir comment je l'ai utilisé avec Kaggle et Hugging Face ?
J'ai bossé avec Translate Gemma, et croyez-moi, c'est un game changer pour les projets multilingues. J'ai commencé par l'intégrer dans mon infrastructure existante (pas une mince affaire), puis je me suis attaqué à ses capacités multimodales. Imaginez : un modèle qui gère 55 langues tout en ayant des données d'entraînement pour 500 autres langues. Mais attention, ce n'est pas juste une question de langues, c'est aussi une question de déploiement et d'optimisation. Après quelques essais et erreurs (et quelques brûlures), j'ai trouvé comment rendre tout ça efficace. On parle ici de modèles allant de 4 à 27 milliards de paramètres. Je vous explique comment comparer les variantes, le processus d'entraînement, et comment j'ai déployé ces modèles avec Kaggle et Hugging Face. Et n'oubliez pas, chaque option de déploiement a ses propres implications. Prêt à plonger avec moi dans Translate Gemma ?
Comprendre les Variantes du Modèle Translate Gemma
Translate Gemma est une innovation majeure pour les tâches de traduction. Mais comment choisir entre ses trois variantes : 4, 12 et 27 milliards de paramètres ? Premièrement, la taille des paramètres influence directement la précision et les ressources nécessaires. J'ai opté pour le modèle de 12 milliards de paramètres pour mes projets de taille moyenne. Il équilibre bien les performances et le coût.
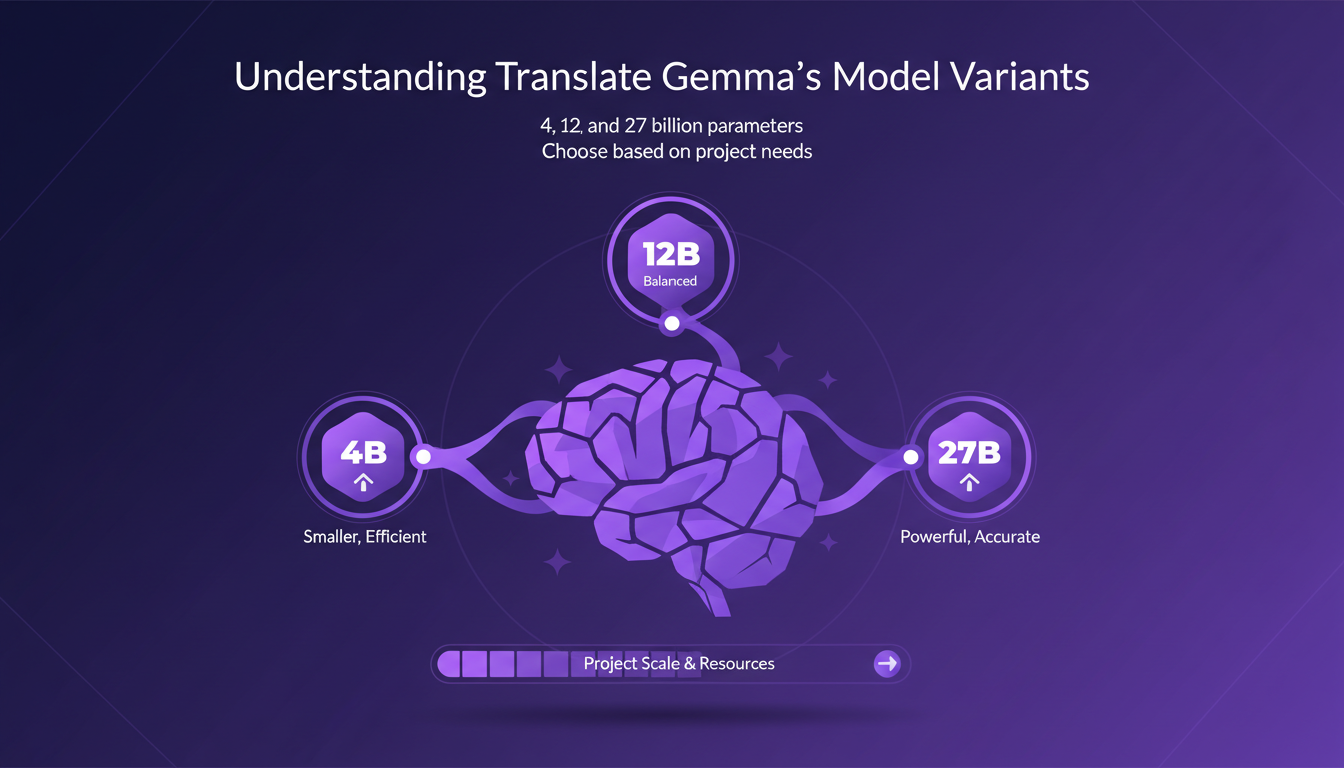
Le modèle de 4 milliards est léger et rapide, mais il manque de précision pour des tâches complexes. Le modèle de 27 milliards, quant à lui, nécessite des infrastructures lourdes, ce qui le rend coûteux. Ainsi, le choix du modèle dépend de l'échelle du projet et de la disponibilité des ressources.
- 4 milliards de paramètres : Léger, rapide mais moins précis.
- 12 milliards de paramètres : Équilibre optimal pour la plupart des projets.
- 27 milliards de paramètres : Précision supérieure, mais coûteux.
Processus d'Entraînement : Fine-tuning Supervisé et Apprentissage par Renforcement
Le fine-tuning supervisé est crucial pour adapter le modèle à des tâches spécifiques. J'ai découvert que l'intégration de l'apprentissage par renforcement améliore l'adaptabilité et la précision de traduction. Cette méthode permet au modèle de produire des sorties plus naturelles.
L'entraînement efficace réduit la consommation de ressources et accélère le déploiement. Cependant, attention à l'overfitting lors du fine-tuning. Il est essentiel de diversifier les jeux de données pour éviter que le modèle ne devienne trop spécifique à un ensemble de données particulier.
- Fine-tuning supervisé : Personnalisation du modèle.
- Apprentissage par renforcement : Améliore l'adaptabilité et le naturel des traductions.
- Varier les jeux de données pour éviter l'overfitting.
Explorer les Capacités Multimodales
Translate Gemma ne se limite pas aux seuls textes. Ses capacités multimodales lui permettent de traiter à la fois des textes et des images. Dans mes applications, j'ai utilisé ces fonctionnalités pour enrichir l'interaction utilisateur et comprendre le contexte de manière plus approfondie.
Cependant, il faut équilibrer l'utilisation multimodale avec la vitesse de traitement. Les capacités multimodales ouvrent de nouvelles voies pour les applications créatives, mais elles demandent des ressources supplémentaires.
- Texte et image : Améliore l'interaction utilisateur.
- Compréhension du contexte améliorée par la combinaison des modalités.
- Équilibrer l'utilisation multimodale avec la vitesse de traitement.
Options de Déploiement pour Différentes Tailles de Modèles
Chaque taille de modèle offre des options de déploiement différentes. Les plus petits modèles se déploient rapidement, mais manquent de précision. Les modèles plus grands nécessitent plus de puissance de calcul. J'ai testé le déploiement sur des serveurs locaux et des plateformes cloud.
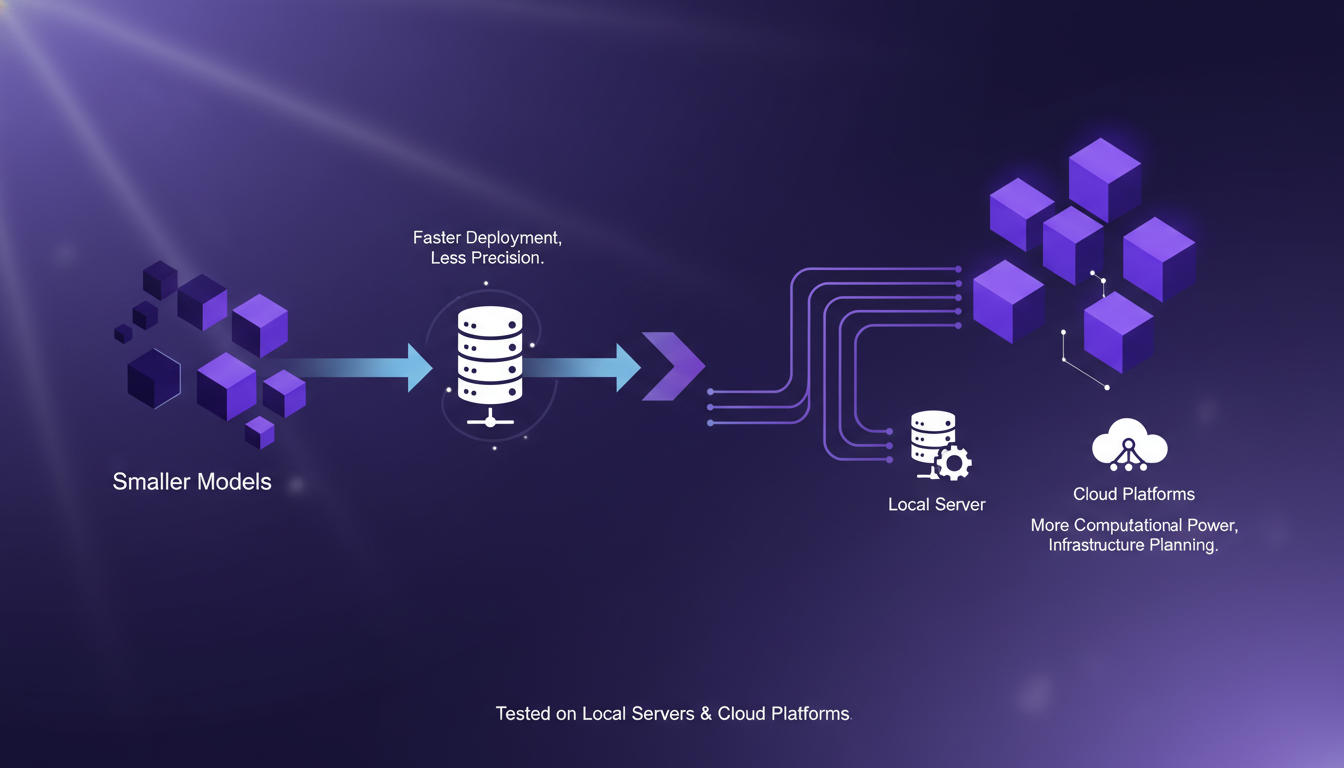
Le choix du déploiement influence la latence et l'expérience utilisateur. Attention aux implications de coût lors du déploiement sur le cloud, surtout pour les modèles de grande taille.
- Modèles plus petits : Déploiement rapide mais précision limitée.
- Modèles plus grands : Plus de puissance nécessaire, coûts plus élevés.
- Stratégie de déploiement impacte la latence et l'expérience utilisateur.
Intégration avec Kaggle et Hugging Face
Kaggle offre une plateforme collaborative pour l'expérimentation de modèles, tandis que Hugging Face fournit des outils pour une intégration transparente. J'ai utilisé ces plateformes pour optimiser mon flux de travail et mes tests.
Néanmoins, il est crucial de rester vigilant quant à la confidentialité des données lors de l'utilisation de plateformes tierces. Ces outils peuvent réduire considérablement le temps de configuration et d'itération.
- Kaggle : Plateforme collaborative pour l'expérimentation.
- Hugging Face : Intégration fluide des modèles.
- Attention à la confidentialité des données sur les plateformes tierces.
Pour en savoir plus sur les architectures multi-agents, consultez choisir la bonne architecture multi-agents ou explorez les nouveaux modèles de traduction ouverts de Google.
Avec Translate Gemma, j'ai découvert un outil polyvalent qui peut vraiment transformer la gestion des tâches multilingues, à condition de l'utiliser intelligemment. D'abord, je choisis la taille du modèle en fonction de mes besoins : 4, 12, ou 27 milliards de paramètres, chacun a son impact sur la performance et les ressources. Ensuite, je déploie efficacement en veillant à équilibrer performance et capacité. Mais attention, ne sous-estimez pas les limites des ressources disponibles. Voici ce que j'ai retenu :
- La taille du modèle influence directement l'efficacité et les coûts.
- Les capacités multimodales de Gemma ajoutent une couche de flexibilité.
- La formation et l'apprentissage par renforcement sont des étapes clés pour optimiser les résultats.
Translate Gemma, c'est une vraie aubaine pour optimiser vos flux de travail multilingues, à condition de bien balancer performance et ressources. Je vous conseille de plonger dans Translate Gemma, de tester ses capacités et d'adapter vos flux. Pour approfondir, regardez la vidéo "TranslateGemma in 7 mins!" sur YouTube : lien.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
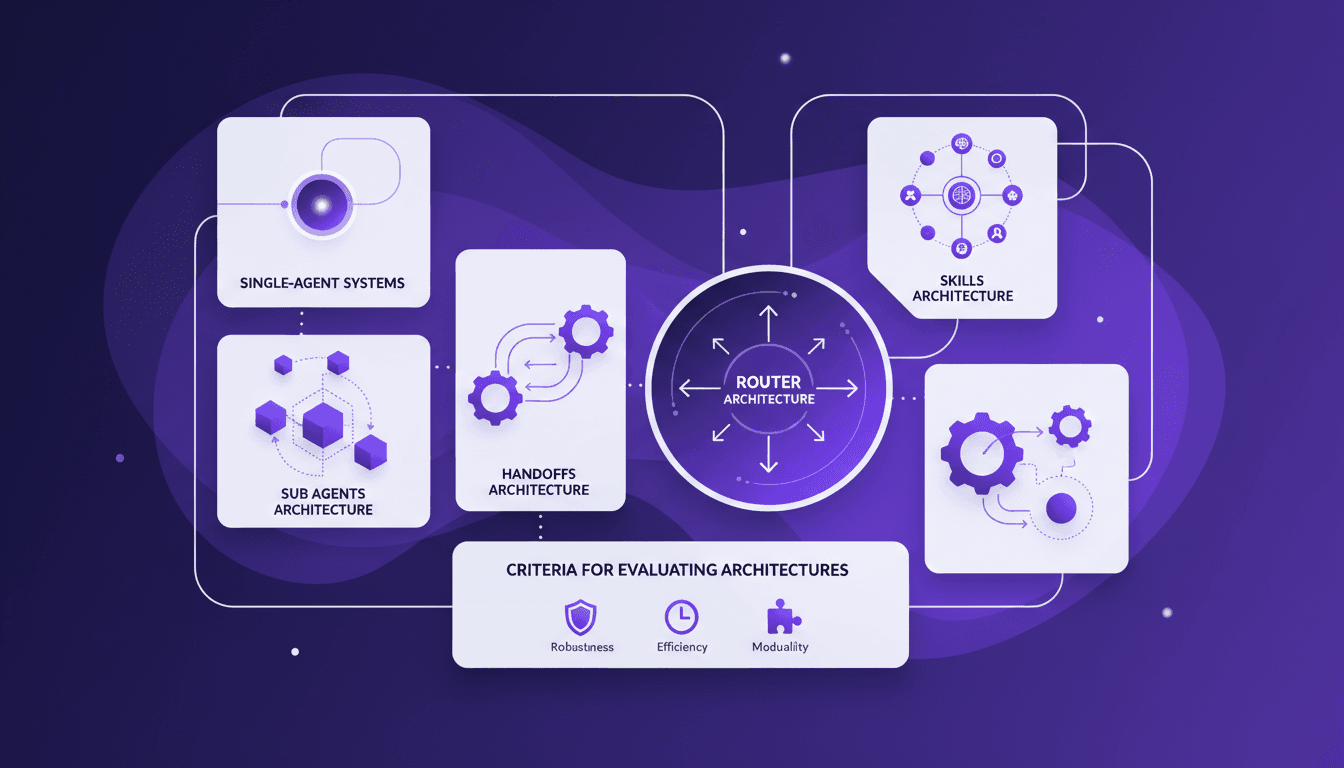
Architecture multi-agents : guide pratique
Je me souviens de la première fois où j'ai essayé d'implémenter un système multi-agents. J'étais submergé par le choix des architectures. Après quelques erreurs, j'ai finalement trouvé un workflow qui fonctionne. Parlons de comment vous pouvez choisir la bonne architecture sans maux de tête. Les systèmes multi-agents peuvent vraiment transformer la façon dont nous gérons des tâches complexes. Avec la bonne architecture, on peut distribuer efficacement la charge de travail et améliorer l'interaction. Mais attention, choisir la mauvaise peut vite devenir un cauchemar en termes d'efficacité et de scalabilité. Dans cet article, je partage mes expériences avec les architectures d'agents secondaires, de handoffs, de compétences et de routeurs. On discutera aussi des critères d'évaluation des architectures et pourquoi il peut être judicieux de commencer par un système mono-agent. Je vous partage mes erreurs et mes réussites pour que vous puissiez éviter les pièges. Prêt à plonger ?
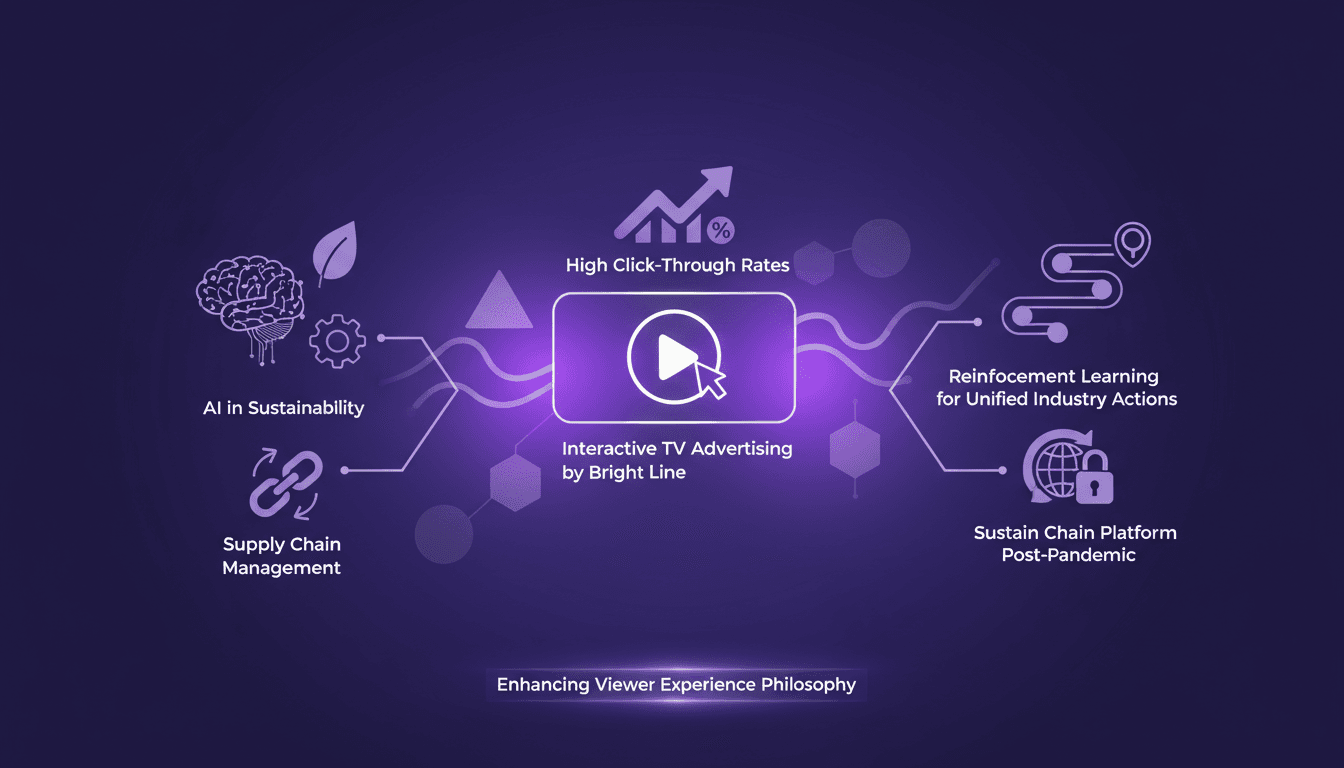
Publicité TV interactive : maximiser l'engagement
Je me souviens encore de la première fois où une publicité interactive à la télé m'a vraiment donné envie de cliquer. C'était une pub de BrightLine, et ça a changé ma perspective sur le potentiel de ce média. Plutôt que de rester un gadget, la publicité TV interactive redessine l'expérience des téléspectateurs, avec des taux de clic qui font rêver (15 % contre 1 % habituellement). BrightLine est à l'avant-garde, en intégrant l'IA pour améliorer l'expérience utilisateur tout en poussant les limites de la durabilité. Dans cet article, je vais vous montrer comment ils orchestrent cette transformation, et pourquoi le futur de la pub TV est déjà là.
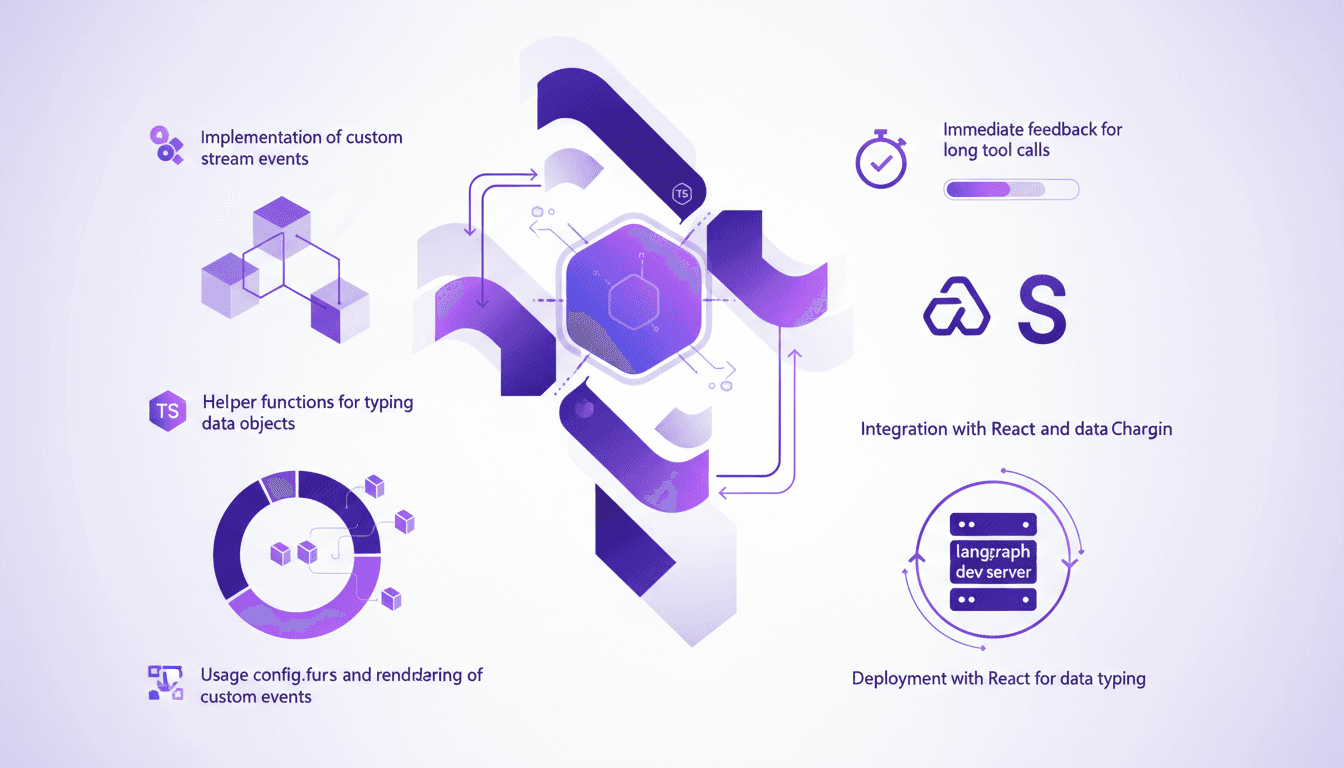
Optimiser l'UX avec LangChain et Typescript
Je me souviens de la première fois où j'ai affronté des interfaces utilisateurs lentes en travaillant avec des outils d'agents. C'était frustrant, surtout quand on veut impressionner un client avec du traitement de données en temps réel. C'est là que j'ai commencé à intégrer des événements de flux personnalisés avec LangChain. Dans cet article, je vais vous montrer comment configurer une interface utilisateur réactive en utilisant LangChain, React et Typescript. Nous plongerons dans les événements de flux personnalisés, la fonction config.writer, et le déploiement avec le serveur de développement langraph. Si vous avez déjà perdu du temps avec des appels d'outils qui traînent, ce tutoriel est pour vous.
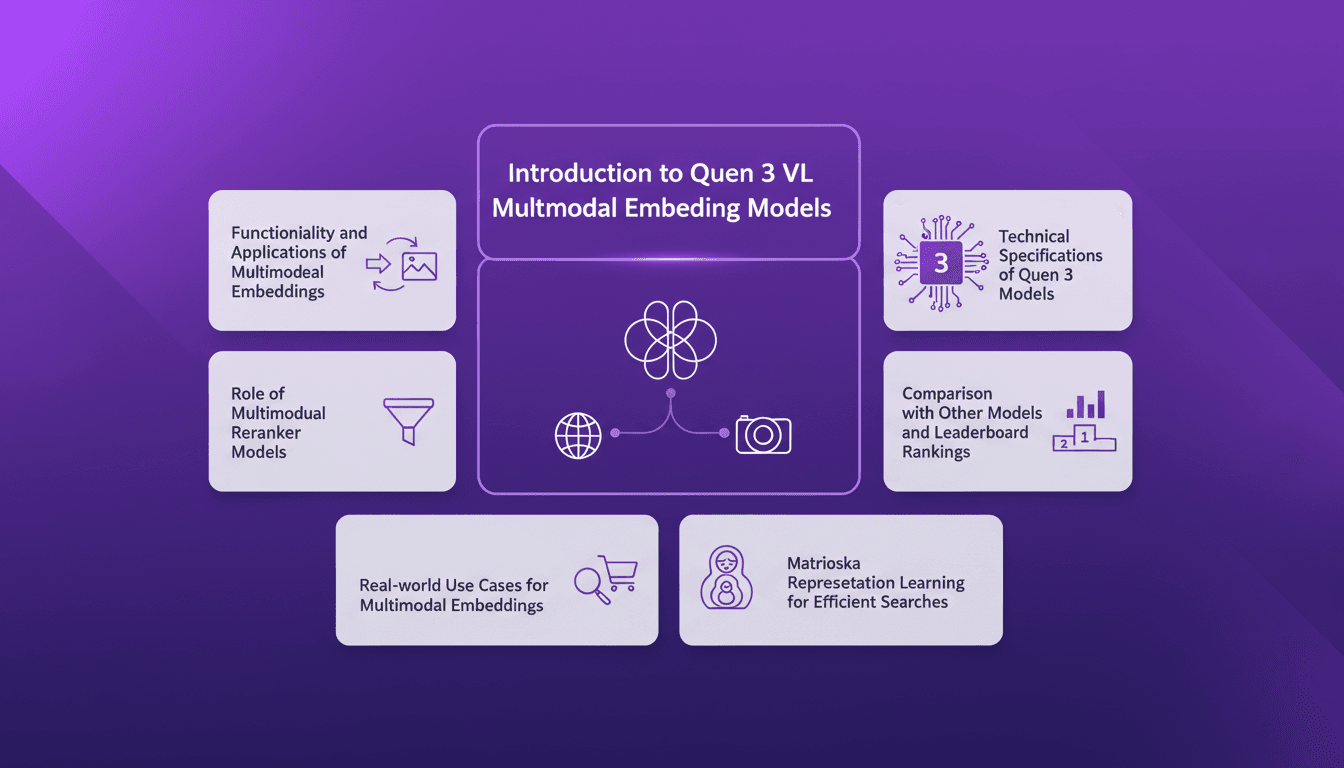
Embeddings Multimodaux Quen 3: Guide Pratique
Je me suis plongé dans les embeddings multimodaux de Qwen 3, avec l'objectif de rationaliser mes projets AI. La promesse ? Une précision et une efficacité accrues dans plus de 30 langues. D'abord, j'ai connecté les modèles d'embedding, puis j'ai orchestré les rerankers pour des recherches plus efficaces. Les résultats ? Un modèle qui atteint 85 % de précision, un véritable game changer. Mais attention, chaque outil a ses limites et Qwen 3 ne fait pas exception. Je vous explique comment j'ai configuré tout ça et l'impact réel que ça a eu.
Tutoriel Cling Motion Transfer: Maîtrisez-le
Je me souviens encore de la première fois où j'ai essayé le Cling Motion Transfer. C'était une vraie révolution. Pour moins d'un dollar, j'ai transformé une simple vidéo en un contenu viral. Dans cet article, je vais vous montrer comment je l'ai fait, étape par étape. Cling Motion Transfer est un outil AI abordable qui se distingue dans le monde de la création vidéo, surtout pour les plateformes comme TikTok. Mais attention, comme tout outil, il a ses caprices et ses limites. Je vais vous guider à travers le choix des images et vidéos, l'utilisation des prompts, et comment finaliser et soumettre votre contenu AI. C'est parti.