Lancement d'Ollama : Défi sur Mac
Je me souviens de la première fois où j'ai lancé Ollama sur mon Mac. Comme ouvrir une boîte à outils flambant neuve, remplie de gadgets étincelants que je mourais d'envie de tester. Mais la vraie question, c'est comment ces modèles tiennent la route. Dans cet article, on va plonger dans les fonctionnalités d'Ollama Launch, mettre à l'épreuve le modèle GLM 4.7 flash, et voir comment Claude Code se compare. On va aussi s'attaquer aux défis d'exécuter ces modèles localement sur un Mac et discuter des améliorations possibles. Si vous avez déjà essayé de faire tourner un modèle de 30 milliards de paramètres avec une longueur de contexte de 64K, vous savez de quoi je parle. Alors, prêt à relever le défi ?
Je me souviens très bien de la première fois où j'ai lancé Ollama Launch sur mon Mac. C'était comme ouvrir une nouvelle boîte à outils, pleine d'outils étincelants que je mourais d'envie de tester. Mais comme toujours, la véritable épreuve réside dans l'exécution. D'abord, je me suis plongé dans les fonctionnalités d'Ollama. Très vite, j'ai vu les limites de la longueur de contexte par défaut de Lama, à 4 096 tokens. Ça peut marcher pour des tâches basiques, mais si vous passez à 64K, vous entrez dans une toute autre dimension. Ensuite, j'ai testé le modèle GLM 4.7 flash. Là encore, attention aux performances qui peuvent chuter si on ne gère pas bien le contexte. Côté Claude Code, il se défend bien, mais n'oubliez pas qu'il peut avoir des limites. Et pour ceux qui, comme moi, aiment tout faire tourner en local sur leur Mac, sachez que c'est un vrai défi. Mais avec quelques ajustements, notamment en optimisant l'orchestration, on peut vraiment améliorer les performances. En fin de compte, ce sont les petits détails qui font la différence.
Exploration des Fonctionnalités du Lancement d'Ollama
D'abord, parlons d'Ollama Launch, une nouvelle fonctionnalité qui m'a vraiment simplifié la vie pour exécuter Claude Code avec le support de l'Anthropic API. J'ai configuré ça sur mon Mac Mini Pro avec 32 Go de mémoire (oui, je sais, c'est pas mal) et honnêtement, j'ai été agréablement surpris par la facilité d'utilisation. Pas besoin de bidouiller pendant des heures, tout est pratiquement prêt à l'emploi.

Ce qui m'a vraiment marqué, c'est la possibilité de lancer des modèles comme Claude Code ou GLM 4.7 Flash sans que cela devienne un cauchemar de configuration. Mais attention, il faut bien régler la longueur de contexte sinon ça devient vite le chaos.
Tester le Modèle GLM 4.7 Flash
Ensuite, passons au test du modèle GLM 4.7 Flash, qui est une version plus compacte du modèle GLM 4.7 avec ses 30 milliards de paramètres, dont trois milliards sont actifs. J'ai configuré une longueur de contexte de 64K pour ce modèle, ce qui est crucial pour ses performances. Ne vous laissez pas tromper par le nombre élevé de paramètres, ce n'est pas toujours synonyme de meilleures performances.
Après 90 minutes de tests, j'ai réalisé que la quantification joue un rôle énorme ici. Parfois, la quantification réduit la précision, mais elle améliore aussi la vitesse d'exécution. C'est un compromis entre précision et rapidité qu'il faut bien peser.
- 30 milliards de paramètres, mais seulement trois milliards actifs.
- Contexte de 64K pour optimiser les performances.
- Attention aux compromis entre quantification et précision.
L'Importance de la Longueur de Contexte
La longueur de contexte, c'est un peu comme la mémoire à court terme d'un modèle. Par défaut, Lama utilise une longueur de 4,096. Pour obtenir de meilleurs résultats, j'ai ajusté ça à 64K. Ça change tout ! Mais attention, pousser trop loin la longueur de contexte peut saturer la mémoire et ralentir le traitement.
En ajustant cette variable, j'ai pu améliorer considérablement les performances, mais il faut toujours être conscient des limites matérielles.
Exécuter des Modèles Localement sur Mac : Défis et Solutions
Faire tourner ces modèles localement, c'est un vrai défi. Même avec 32 Go de RAM sur mon Mac Mini Pro, il faut jongler avec la gestion mémoire. Claude Code, par exemple, peut devenir très lent si on ne fait pas attention. J'ai dû utiliser des astuces pour optimiser l'exécution locale, comme la gestion des processus en arrière-plan et l'optimisation des ressources.
Des améliorations futures pourraient rendre l'exécution locale plus viable, mais pour l'instant, c'est limité sans GPU puissant.
Claude Code vs Autres Modèles : Un Bilan de Performance
Enfin, comparons Claude Code au modèle GLM 4.7. Avec l'Anthropic API, Claude Code a certes ses forces, mais aussi des faiblesses. J'ai noté des gains d'efficacité, mais il y a des domaines où Claude Code pourrait s'améliorer, notamment en termes de vitesse d'exécution et de gestion des ressources.
Des développements futurs pourraient combler ces lacunes, mais pour l'instant, Claude Code brille surtout par sa flexibilité et son intégration avec d'autres outils.
- Claude Code performant grâce à l'Anthropic API.
- Besoin d'améliorations pour la vitesse et la gestion des ressources.
- Avenir prometteur avec des développements en cours.
Après avoir plongé dans Ollama Launch et testé les GLM 4.7 et Claude Code, je dois dire que ces outils offrent des possibilités excitantes, mais il y a des défis à considérer. D'abord, la gestion de la longueur de contexte est cruciale. Passer à une longueur de contexte de 64K au lieu des 4,096 par défaut de Lama a vraiment changé la donne. Ensuite, exécuter ces modèles localement sur Mac n'est pas sans accrocs. Avec un modèle de 30 milliards de paramètres et 3 milliards actifs, les performances locales demandent une optimisation rigoureuse. Enfin, il est essentiel de trouver l'équilibre entre potentiel de la technologie et contraintes matérielles.
En regardant vers l'avenir, l'optimisation de l'exécution locale et des longueurs de contexte est un véritable levier pour exploiter le plein potentiel de ces outils. Alors, prêt à pousser l'exécution de votre modèle au niveau supérieur ? Commencez à expérimenter et partagez vos découvertes avec la communauté. Pour un aperçu plus détaillé, n'hésitez pas à visionner la vidéo originale — c'est un excellent point de départ pour toute cette aventure.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Cloner des Voix Gratuitement : Qwen TTS Révolutionne
Je me souviens de la première fois où j'ai cloné une voix avec Qwen TTS — c'était comme entrer dans le futur. Imaginez avoir un outil aussi puissant, et en plus open source, à portée de main. Ce n'est pas juste de la théorie; c'est l'application concrète de cette technologie aujourd'hui. En juin dernier, Qwen a dévoilé ses modèles TTS, et d'ici septembre, le Quen 3 TTS Flash avec support multilingue était prêt. Pour quiconque s'intéresse au clonage de voix et à la génération de discours multilingues, c'est un véritable game changer. Avec des modèles allant de 0,6 milliard à 1,7 milliard de paramètres, les possibilités sont énormes. Mais attention, il y a des limites techniques à garder à l'esprit. Dans cet article, je vais vous guider à travers les capacités multilingues, la libération open-source, et la synthèse émotionnelle. Préparez-vous à explorer comment vous pouvez exploiter cette technologie dès aujourd'hui.
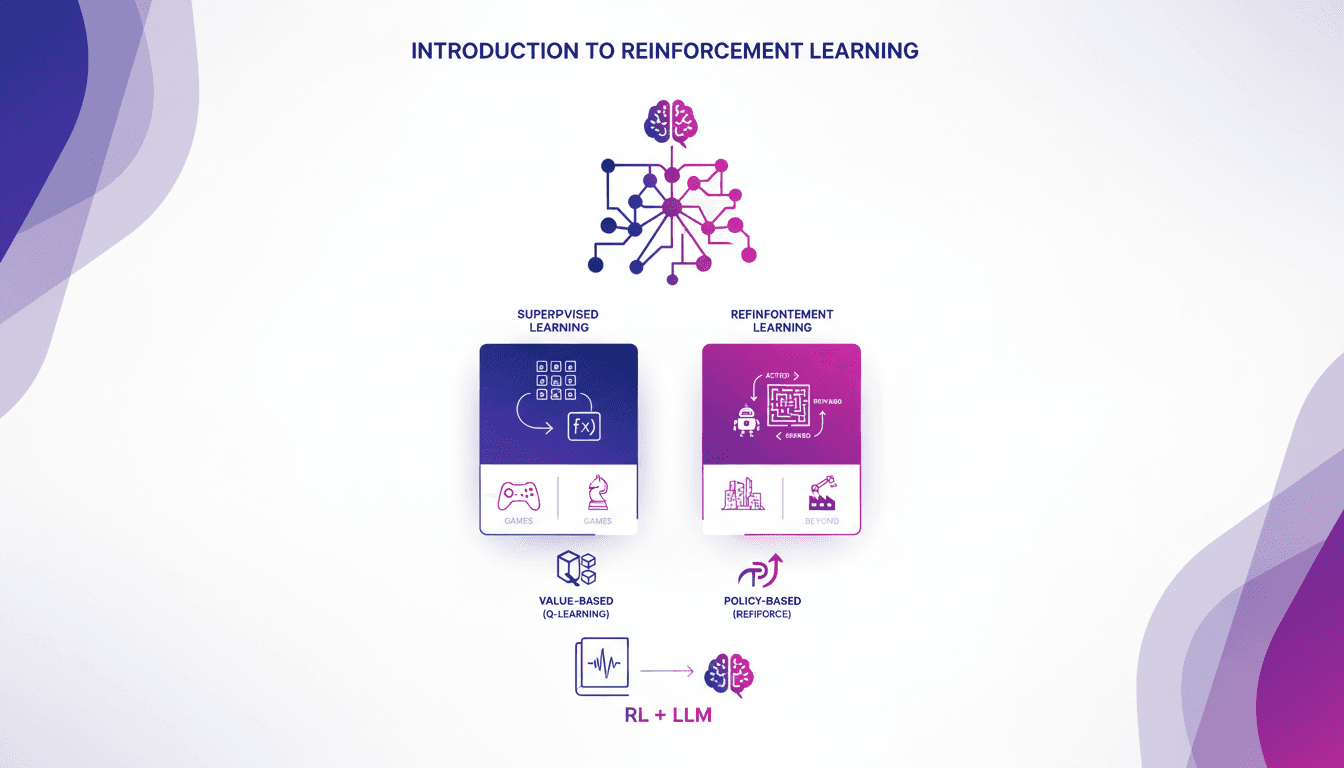
Introduction pratique à l'apprentissage renforcé
Je me souviens de ma première rencontre avec le renforcement de l'apprentissage. C'était comme débloquer un nouveau niveau dans un jeu, où les algorithmes apprennent par essai et erreur, tout comme nous. Contrairement à l'apprentissage supervisé, le RL ne s'appuie pas sur des jeux de données étiquetés. Il apprend des conséquences de ses actions. D'abord, on compare le RL à l'apprentissage supervisé, puis on plonge dans ses applications réelles, notamment dans les jeux. Je vous guiderai à travers les méthodes basées sur la valeur, comme le Q-learning, et les méthodes basées sur la politique, en montrant comment ces approches transforment des modèles de langage massif. En fin de compte, vous verrez comment trois manières clés d'utiliser le RL pour affiner les grands modèles de langage offrent des résultats impressionnants.

Optimisez les agents profonds avec /remember
J'ai passé d'innombrables heures à peaufiner les configurations des agents profonds, et je peux vous dire que la commande /remember est un véritable changement de jeu. C'est comme donner à votre agent un cerveau qui retient vraiment les informations utiles. Laissez-moi vous montrer comment je l'utilise pour rationaliser les processus et améliorer l'efficacité. Avec la commande /remember dans le CLI des agents profonds, vous pouvez enseigner aux agents à apprendre de l'expérience. On va plonger dans le fonctionnement de tout ça et pourquoi c'est un indispensable dans votre arsenal.
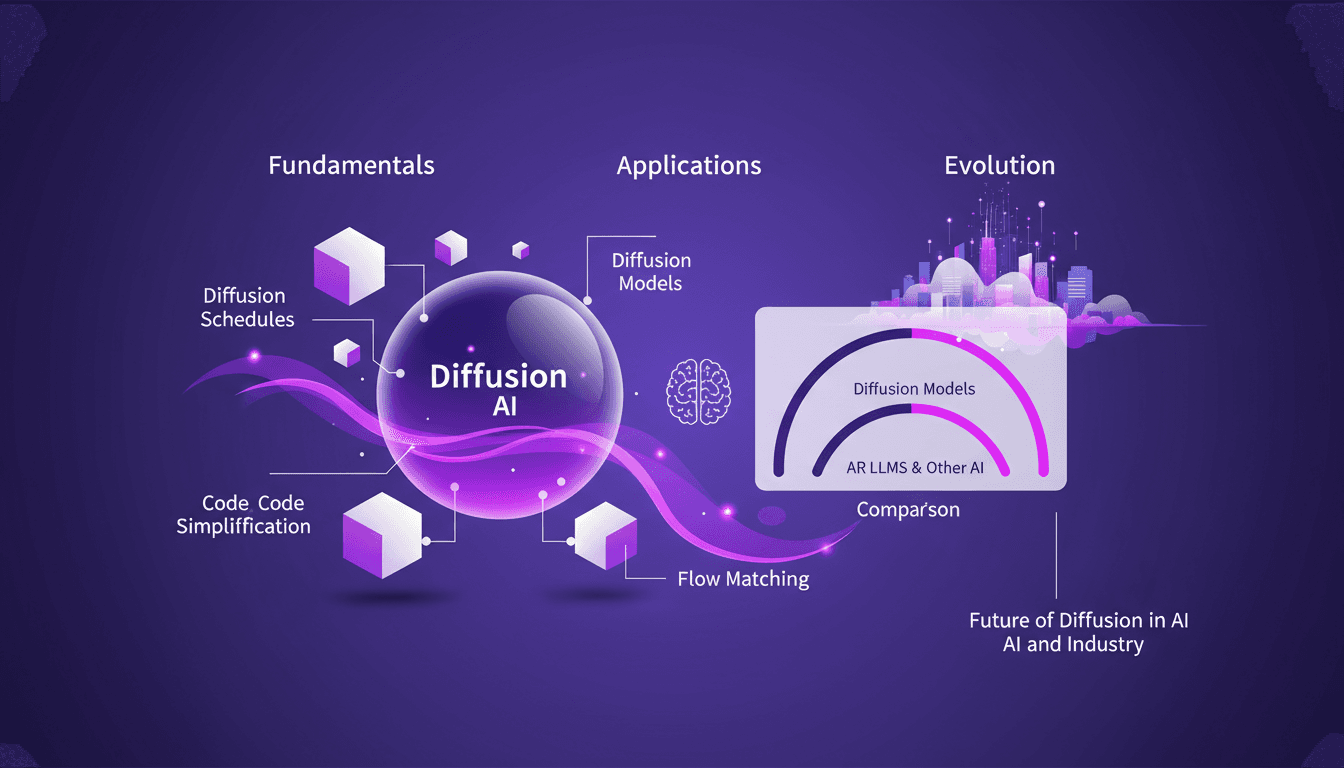
Techniques Diffusion ML: Appliquées et Optimisées
Depuis que je suis plongé dans le machine learning en 2012, j'ai vu des techniques venir et partir, mais les modèles de diffusion sont un vrai changement de jeu. Et ce n'est pas juste pour les académiciens—je parle d'applications concrètes qui peuvent transformer votre flux de travail. La diffusion en ML n'est pas un simple mot à la mode. C'est un cadre fondamental qui redéfinit notre approche de l'IA, de la modélisation d'images au traitement de données complexes. Pour les fondateurs et les praticiens, comprendre et appliquer ces techniques peut vous faire gagner du temps et augmenter votre efficacité. Avec seulement 15 lignes de code, vous pouvez mettre en place un processus de machine learning puissant. Si vous êtes prêt à explorer l'avenir de l'IA, c'est le moment de maîtriser la diffusion.
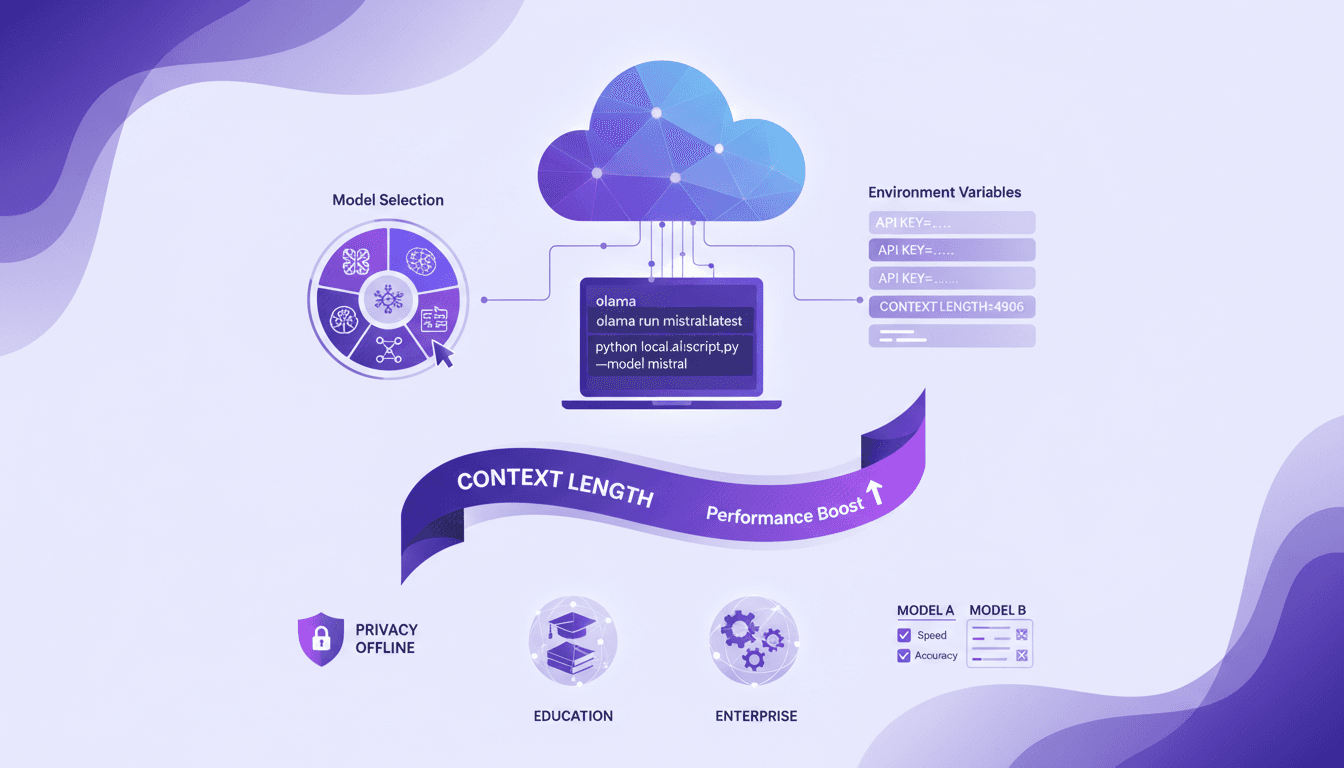
Exécuter du Code Cloud avec Olama: Tutoriel
J'ai commencé à exécuter du code cloud en local pour booster l'efficacité et la confidentialité, et Olama a été un véritable game changer. Imaginez pouvoir manipuler des modèles IA avec 4 milliards de paramètres, le tout sans quitter votre bureau. Je vais vous montrer comment j'ai configuré tout ça, de la sélection des modèles à l'ajustement des variables d'environnement, et pourquoi ça change la donne pour l'éducation et les entreprises. Mais attention aux limites de contexte : au-delà de 100K tokens, ça se complique. En utilisant Olama, on peut comparer différents modèles IA pour une utilisation locale tout en assurant une confidentialité renforcée et des capacités hors ligne. L'idée ici, c'est de vous donner un aperçu pratique et direct de la façon dont je pilote ces technologies dans mon quotidien professionnel.