Mistral Small 4 : Déploiement et Cas d'Utilisation
J'ai récemment exploré le modèle Mistral Small 4, et laissez-moi vous dire, c'est une bête avec ses 119 milliards de paramètres. Mais ne vous laissez pas intimider ; tout dépend de la manière dont vous l'utilisez. Avec ses capacités multimodales et multilingues, ce modèle change vraiment la donne. Je vais vous guider à travers son déploiement, les compromis auxquels j'ai été confronté, et où il brille vraiment. Que vous compariez avec GPT-3 ou que vous cherchiez à comprendre les exigences matérielles, il y a ici de quoi optimiser votre approche AI. Attention, ne sous-estimez pas les spécifications techniques, car elles peuvent vous coûter cher en performance.
J'ai plongé tête la première dans le modèle Mistral Small 4, et croyez-moi, avec ses 119 milliards de paramètres, c'est du costaud. Mais ne vous laissez pas impressionner ; c'est tout une question de maîtrise. D'abord, j'ai dû jongler avec ses 6 milliards de paramètres actifs pour optimiser le déploiement. Ensuite, c'était question de comprendre les spécifications techniques et de comparer avec d'autres modèles comme GPT-3. C'est là que les compromis apparaissent : performances versus complexité. J'ai aussi exploré les cas d'utilisation pratiques, et franchement, le potentiel multimodal et multilingue est impressionnant. Attention aux exigences matérielles, c'est du sérieux. Pour les curieux de l'open source, le modèle propose également des formats et des checkpoints intéressants. Bref, Mistral Small 4 n'est pas qu'un simple modèle, c'est un véritable outil de transformation pour ceux qui savent s'en servir.
Comprendre le Modèle Mistral Small 4
Quand j'ai commencé à travailler avec le modèle Mistral Small 4, je me suis tout de suite rendu compte qu'il s'agit bien plus qu'un simple modèle AI. Avec ses 119 milliards de paramètres, dont 6 milliards actifs, on parle d'une véritable bête technologique. Et malgré ce chiffre impressionnant, seulement 4 experts sur les 128 sont actifs en même temps. C'est là que le modèle Mixture of Experts (MoE) prend tout son sens : il permet une allocation dynamique des ressources, optimisant ainsi les performances en fonction des tâches spécifiques.
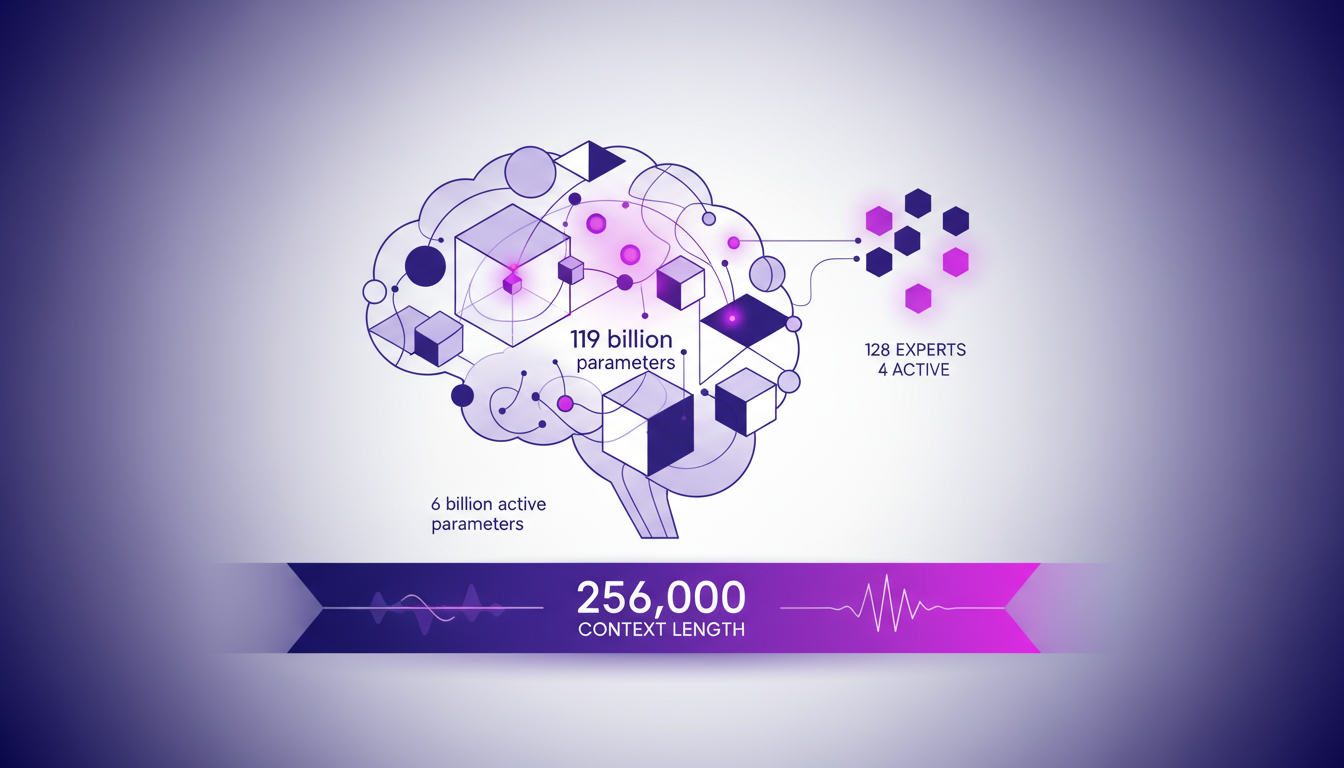
Ce modèle se distingue également par un contexte de longueur de 256 000, ce qui signifie que lors de l'application en situations réelles, il peut traiter d'énormes quantités de données simultanément. Cela change la donne, surtout dans les applications complexes nécessitant une compréhension contextuelle étendue.
Spécifications Techniques et Indicateurs de Performance
La première fois que j'ai plongé dans les spécifications techniques, j'ai été frappé par les chiffres : 196 tokens par seconde et un temps jusqu'au premier token (TTFT) de seulement 8 millisecondes. C'est rapide, vraiment rapide. Mais attention, la performance dépend aussi de la précision des calculs. Le modèle utilise les formats de précision flottante FP8 et NVFP4, ce qui réduit la mémoire et améliore le débit.
En pratique, cela signifie que lors du déploiement, on peut s'attendre à une réduction de 40 % du temps de complétion de bout en bout, particulièrement si l'on utilise le checkpoint Eagle pour le décodage spéculatif. Mais attention, ces gains peuvent varier en fonction de l'infrastructure matérielle.
- 119 milliards de paramètres au total, 6 milliards actifs
- 256 000 de longueur de contexte
- 196 tokens/seconde de vitesse
- 8 ms TTFT
Comparaison avec le GPT-3 et Autres
En comparant le Mistral Small 4 avec des modèles comme le GPT-3, la différence d'architecture saute aux yeux. Là où le GPT-3 utilise ses 120 milliards de paramètres de manière plus linéaire, Mistral met en avant sa capacité de traitement spécialisée grâce à ses 128 experts. Cela rend Mistral souvent plus efficace dans les scénarios où la personnalisation et l'optimisation sont clés.
Toutefois, il y a des compromis à faire, notamment en termes de longueur de contexte et de rapidité de traitement. Le Mistral Small 4 surpasse souvent le GPT-3 en termes de longueur de sortie et de temps de réponse. Cependant, il nécessite une infrastructure plus robuste, ce qui peut être un obstacle pour certaines entreprises.
Scénarios de Déploiement et Cas d'Utilisation
Lors de mes expérimentations avec Mistral Small 4, j'ai découvert qu'il excelle dans des environnements nécessitant une compréhension multimodale, comme l'analyse de documents ou les assistants de chat internes. Son aptitude à gérer des entrées textuelles et visuelles le rend particulièrement polyvalent.
En termes de coûts, il est crucial de trouver un équilibre entre performance et dépenses. J'ai appris à mes dépens que sous-estimer les besoins matériels peut rapidement faire exploser le budget. L'important est de piloter le modèle dans un environnement cloud adapté, comme je l'ai fait lors de mes tests.
- Utilisation multimodale : texte et image
- Applications : analyse documentaire, assistant de chat
- Équilibre entre coûts et performance nécessaire
Licences, Open Source et Formats de Modèles
Le fait que Mistral Small 4 soit sous licence Apache 2.0 est un avantage considérable. Cela ouvre la voie à des adaptations personnalisées sans les tracas des licences restrictives. En tant que développeur, c'est un atout majeur pour l'intégration et la fine-tuning en entreprise.
En termes de formats de modèles, Mistral propose le FP8, le NVFP4 et le checkpoint Eagle. Cela permet une flexibilité en fonction des besoins d'optimisation et des contraintes matérielles. Cependant, il est essentiel de garantir que le matériel utilisé est à la hauteur des exigences pour tirer parti de ces formats.
"Le modèle offre des capacités de vision, multilingues et multimodales, facilitant l'adaptation aux besoins spécifiques de l'entreprise."
- Licence Apache 2.0 : liberté d'utilisation et d'adaptation
- Formats : FP8, NVFP4, Eagle Checkpoint
- Besoin de matériel approprié pour de meilleures performances
Avec tout cela en tête, je ne peux que souligner l'importance de bien comprendre les spécifications techniques et les besoins de votre projet avant de choisir un modèle comme Mistral Small 4. Cela peut faire la différence entre un déploiement réussi et un projet coûteux et inefficace.
Le Mistral Small 4, c'est un vrai titan avec ses 119 milliards de paramètres, mais attention, c'est pas juste la taille qui compte. Voici ce que j'ai retenu :
- J'ai découvert qu'avec ses 6 milliards de paramètres actifs, on peut vraiment optimiser les performances, mais il faut bien comprendre les specs et les limites pour en tirer le meilleur parti.
- Le contexte de 256 000, ça ouvre des portes pour des cas d'usage super complexes. Mais méfiez-vous, chaque projet a ses propres contraintes.
- Comparé à d'autres modèles comme GPT-3, le Mistral Small 4 offre des options intéressantes, mais il faut bien jauger ses besoins en déploiement.
Ce modèle peut vraiment changer la donne si on sait l'utiliser à bon escient. Alors prêt à explorer le Mistral Small 4 ? Commencez par évaluer vos besoins en déploiement et voyez où ce modèle peut faire la différence. Pour une compréhension plus profonde, je vous recommande de regarder la vidéo originale "Mistral Small 4 in 8 mins!" sur YouTube. C'est une mine d'or pour tout mettre en perspective. Lien YouTube.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Découverte de Gemini Embedding 2: Guide Pratique
J'ai plongé dans Gemini Embedding 2, à la fois excité et sceptique. Ayant déjà été déçu par des modèles survendus, je voulais voir si celui-ci tenait ses promesses. Spoiler : il a des fonctionnalités révolutionnaires, mais attention aux limites. Gemini Embedding 2 promet des capacités avancées en embedding multilingue et multimodal, mais comment se comporte-t-il vraiment en application concrète ? Je vous emmène dans un guide pratique (en 8 minutes chrono) pour découvrir ses capacités, apprendre comment utiliser le Matrioska Representation Learning et comparer avec le modèle précédent. On passe aussi en revue l'utilisation avec Google Collab et l'importance de la similarité cosinus. C'est parti pour un tour d'horizon qui va droit au but !
Intégration de Gemini Embedding 2: Guide Pratique
J'ai plongé dans Gemini Embedding 2 pour optimiser la gestion de l'audio, du texte, des images et des vidéos. Imaginez un instant : une approche unifiée qui prend en charge plusieurs modalités d'embedding. J'ai moi-même testé cette promesse, et croyez-moi, il y a des nuances essentielles à connaître pour exploiter pleinement son potentiel. Que vous cherchiez à unifier vos recherches à travers différents médias ou à intégrer ce modèle dans vos frameworks existants, ce guide pratique vous montrera comment. Attention, certaines limitations techniques peuvent vous surprendre, mais avec une bonne orchestration, les résultats sont là. Allons-y, je vous montre comment je l'ai intégré dans mes workflows pour un impact direct et mesurable.
Déployer des Agents avec Langraph CLI: Guide Pratique
Déployer des agents ne devrait pas être un casse-tête. Avec Langraph CLI, j'ai réduit mon temps de déploiement à quelques minutes. D'abord, je configure l'installation du CLI avec une simple commande 'uv tool install langraph cli'. Ensuite, je teste mes applications localement avec Langsmith Studio, ce qui me permet d'itérer rapidement (c'est crucial pour éviter les mauvaises surprises en production). Puis, je crée une nouvelle application Langraph avec 'langraph new' et je suis prêt pour le déploiement. Je vous explique comment j'ai intégré Langsmith, géré mes déploiements et utilisé les endpoints disponibles, tout ça en quelques commandes depuis le terminal. Croyez-moi, une fois que vous aurez goûté à cette simplicité, vous ne reviendrez plus en arrière.
Automatiser sans coder avec Claude Code
Je me souviens encore du moment où j'ai compris que je pouvais automatiser mes tâches sans écrire une seule ligne de code. C'était comme découvrir une arme secrète. Avec Claude Code, j'ai transformé des tâches répétitives en workflows efficaces, gagnant du temps et réduisant les erreurs. Dans cet article, je vais vous montrer comment j'ai fait, en passant en revue les cadres, les applications réelles et comment vous pouvez l'adapter à vos besoins uniques. Si l'efficacité est votre priorité, vous ne voudrez pas manquer ça.
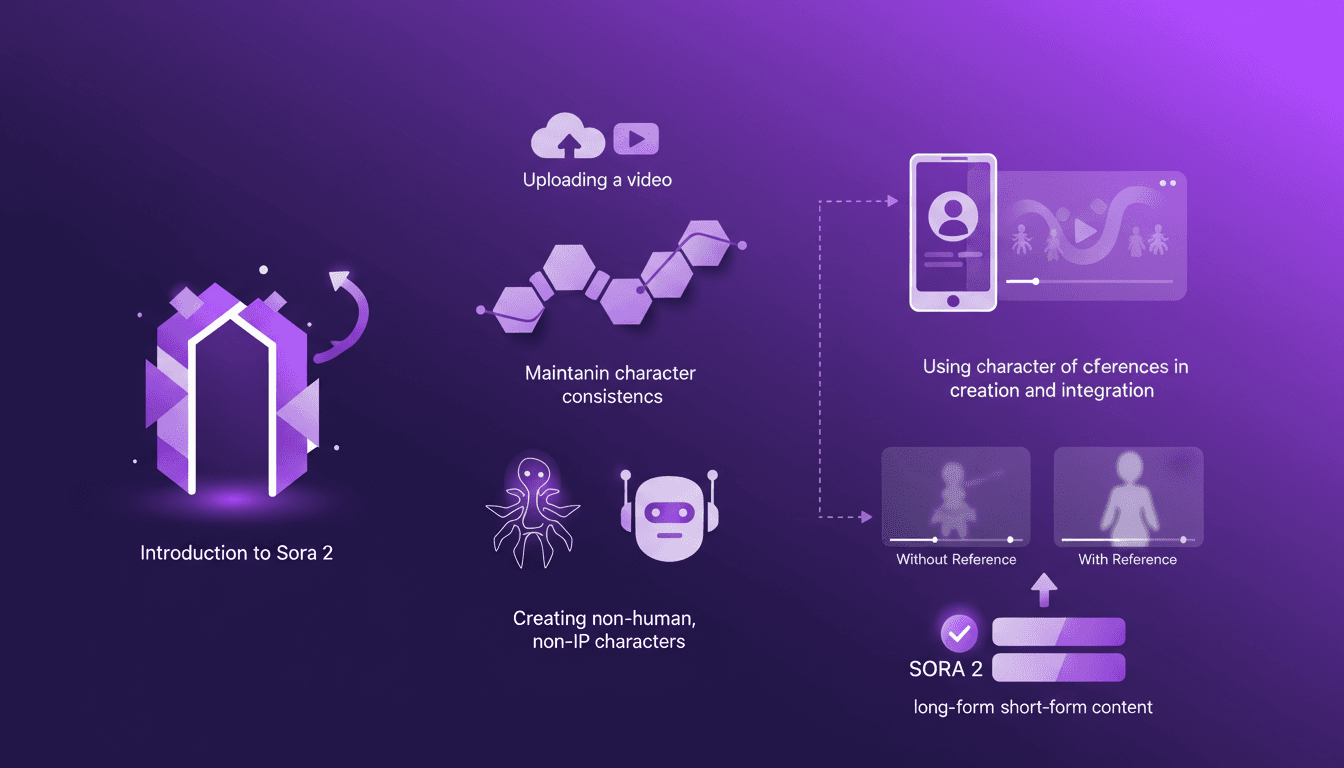
Créer des Personnages Cohérents avec Sora 2
J'ai plongé dans Sora 2 et, croyez-moi, la fonctionnalité de création de personnages est un vrai game changer pour quiconque prend la cohérence vidéo au sérieux. Vous savez à quel point c'est frustrant quand vos personnages générés par l'IA semblent différents à chaque scène ? Sora 2 s'attaque à ce problème de front. Dans cet article, je vous montre comment j'utilise Sora 2 pour maintenir la cohérence des personnages, même lorsque je crée des personnages non humains et non IP. On va parcourir le workflow, de l'importation de votre vidéo initiale à la sortie finale cohérente. Je vais démontrer la création et l'intégration de personnages, et comparer les vidéos avec et sans références de personnages. Sora 2 est un atout majeur pour le contenu long et court. Accrochez-vous, c'est du concret.