Edge AI: Benefits and Implementing Tiny LLMs
I've spent over a decade diving into Edge AI, and let me tell you, it's a game changer. Running AI models directly on edge devices isn't just a tech trend—it's a practical solution to real-world challenges. With the launch of Gemma 4 and advances in Tiny LLMs, we're witnessing a shift towards more efficient and reliable AI solutions. When it comes to deployment and cost, Edge AI is redefining the landscape with performance gains, privacy enhancements, and offline use. Yet, the true potential lies in the skill architecture and customization of the models. In this talk, we delve into the technical infrastructure needed to run AI on edge devices, deployment and licensing changes, and how Tiny LLMs can transform our current approaches.
When I first started integrating AI models on edge devices, I didn't realize how much of a game changer it would be. But after over a decade in the field, I can confidently say it's a major turning point. Running AI models directly on edge devices is far more than just a tech trend—it's a practical solution to real issues like privacy and cost reduction. With the launch of Gemma 4 and advancements in Tiny LLMs, we're witnessing the emergence of more efficient and reliable AI solutions. From a technical standpoint, the ability to deploy AI models at scale on edge devices is transforming how we think about performance and offline use. But be careful, don't underestimate the challenges related to technical infrastructure and model skill customization. In this talk, we'll explore how these technologies are revolutionizing our current approach, the necessary structure to implement these solutions, and the implications of deployment and licensing changes.
Understanding Edge AI and Its Benefits
I've been deep into Edge AI over the past few years, and let me tell you, it's a game changer for several reasons. First off, one of the biggest advantages is latency reduction. Processing data locally means nearly instant responses. Imagine live voice translation on your phone without ever relying on the cloud – that's what we achieved on the Pixel last year.
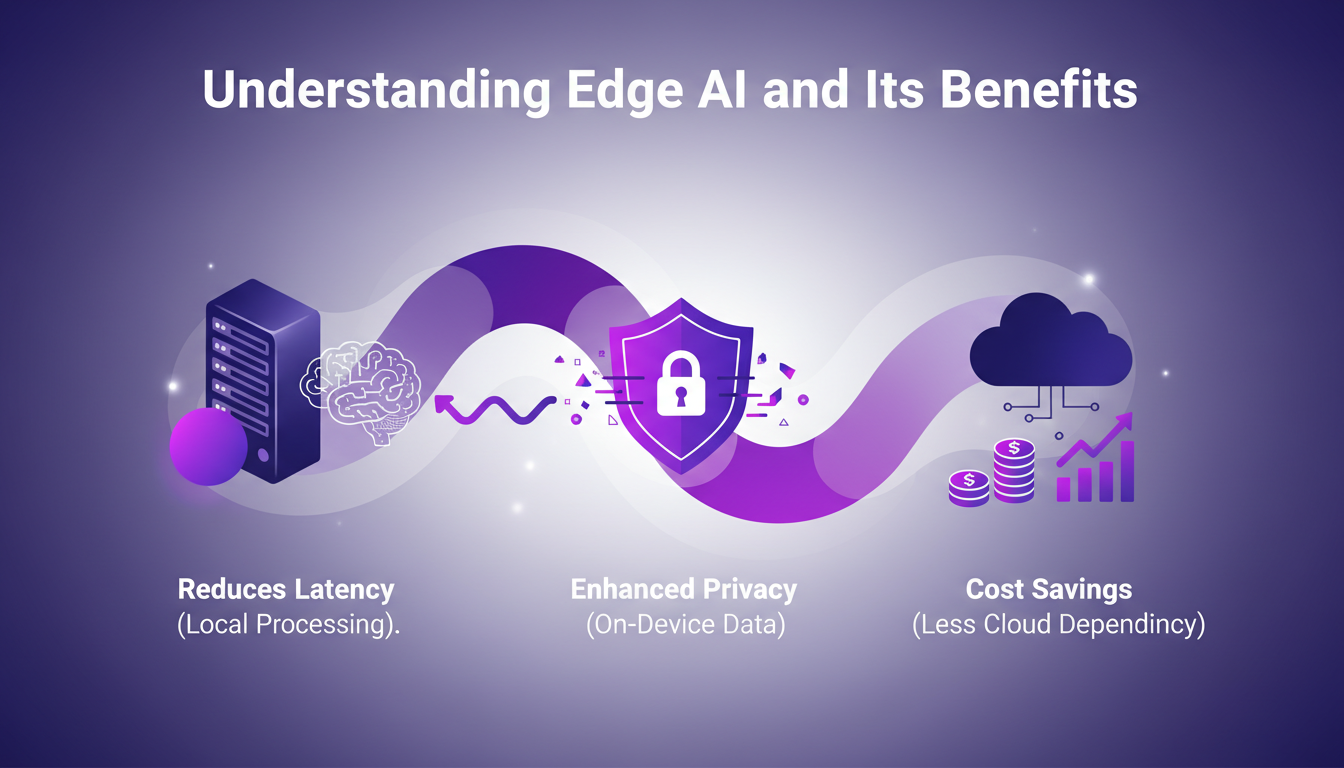
Next, let's talk privacy. Data staying on the device is a blessing for sensitive applications like messaging. And I'm not even talking about the savings from reduced cloud dependency. Businesses save big by minimizing data transfer and processing costs.
But watch out, not everything is rosy with Edge AI. Devices have limited resources, and power constraints can be a headache. That said, we already see real-world applications in IoT and mobile devices where these limits are manageable.
- Improved latency and user experience
- Better data privacy
- Reduction in cloud-related costs
- Practical applications in IoT and mobile
- Challenges with limited resources
Tiny LLMs and Agent Skills on Edge Devices
With Tiny LLMs, we're entering a new era of optimization for low-resource environments. I've often had to balance model size with performance – a delicate equilibrium. Agent skills allow for task-specific model customization, which is crucial when every millisecond counts.
The key is to customize without sacrificing reliability. For instance, a 270-million parameter model dedicated to function calling achieved 85 to 90% reliability in our internal evaluations — a feat for such a small model. But beware, models under 500 million parameters require fine-tuning to reach production-level reliability.
- Optimization for low-resource environments
- Task-specific model customization
- Balancing model size and performance
- Fine-tuning essential for reliability
- Limits of complexity with smaller models
Gemma 4: Launch and System-Level GenAI Models
Last week, we launched Gemma 4, marking a turning point for system-level generative AI models. With models ranging from 2 to 5 billion parameters, the focus is on efficiency and scalability. For industries relying on real-time data, this is a major leap forward.
But watch out for licensing limitations. Under Apache 2.0, it's crucial to adhere to deployment constraints. I've seen implementations fail simply because license rules weren't strictly followed.
- System-level generative AI models
- Efficiency and scalability in deployment
- Implications for real-time data industries
- Deployment strategies under Apache 2.0
- Be mindful of licensing limitations
Technical Infrastructure for Running AI on Edge
When talking about AI on Edge, infrastructure is key. We need to handle models from 100 to 500 million parameters while optimizing RAM and context window sizes. It's a real challenge, but with the right platforms and tools, it's doable.
I've often used platforms like Dynamic Software Interfaces to facilitate deployment. But beware of device compatibility issues and maintenance, which can quickly become major hurdles.
- Infrastructure requirements for AI on Edge
- Managing model performance
- Optimizing RAM and context window sizes
- Supporting tools and platforms
- Potential pitfalls: compatibility and maintenance
Skill Architecture and Customization for AI Models
Skill architecture allows extending AI model capabilities, crucial for meeting specific industry needs. However, it's important to balance customization with model stability. Ongoing updates and fine-tuning are essential.
I've seen companies fail by overcomplicating their models without considering performance. It's a delicate balance: more complexity can mean specialized performance but can also render the model unstable.
- Extending model capabilities via skill architecture
- Custom skills for specific industry needs
- Balancing customization and stability
- Importance of ongoing updates
- Increased complexity vs. specialized performance
Edge AI is flipping the AI script by bringing computation closer to the data source, and it's a game changer. I've worked with Tiny LLMs in our setups, and here's what I've nailed down:
- First, focus on model size: with 500 million parameters, you can fine-tune for production-level reliability. That's your magic number.
- Then, for E2B models, you'll need 2 billion parameters in RAM. Without that, efficiency tanks.
- I also found medium-size models with a 128K context window hit the sweet spot for complex tasks.
But watch out, deploying these models comes with its own set of privacy and cost trade-offs.
The future of AI is at the edge, and we're at the forefront. If you haven't started yet, begin small, focus on your specific needs, and iterate based on real-world feedback. To dive deeper, I recommend checking out Cormac Brick's video on Tiny LLMs. It's a goldmine for anyone looking to get into Edge AI!
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
Setting Up Claude Co-work: A Builder's Guide
I still remember the first time I set up Claude Co-work. It was like opening a toolbox with endless possibilities. But let's be honest, it wasn't all smooth sailing. After getting burned a few times, I finally navigated the setup, features, and customization to make Claude Co-work a real asset in my projects. Whether you're a beginner or have some experience, understanding how to make the most of this AI assistant is crucial. Let's dive in, and I'll show you how to turn Claude Co-work into a powerful ally.
Dipsic V4: AI Revolution, Challenges OpenAI
I've been in the AI trenches for years, watching models evolve. But when I first got my hands on Dipsic V4, I knew we were onto something game-changing. With 1600 billion parameters, this model isn't just another tool in the landscape; it’s a potential disruptor in a space dominated by giants like OpenAI's GPT 5.5. Let me show you why this model is causing such a stir and how it’s rewriting the rules. We’ll dive into its innovative features, aggressive pricing strategy, and what it means for players like Nvidia and OpenAI. Watch out, this could be a game changer.
Recursion in AI: Transforming Models
I've spent countless hours tweaking AI models, and let me tell you, recursion is the game changer we've been waiting for. Forget the race for more parameters; now it's about intelligence. While traditional models hit scaling walls, recursion offers a fresh perspective. We're diving into how it could redefine AI efficiency and capability. We'll discuss hierarchical reasoning models, tiny recursive models, deep equilibrium learning, and the challenges of optimization. If you've ever been frustrated by scalability limits, you're going to love this new paradigm.
Dynamic Software Interfaces Evolution
I've watched software interfaces evolve from static to dynamic, and it's a game changer. As a forward-deployed engineer, I've seen firsthand how personalization is redefining our approach to software. We're moving beyond one-size-fits-all solutions. We're crafting interfaces that adapt to each user through coding agents and a reimagined delivery stack. It's a pivotal moment for the industry, but watch out for the pitfalls: you need precise orchestration and to avoid over-customization that can confuse users. Don't get stuck in old habits, it's time to embrace a more flexible, user-centric approach. Join me as we explore how these transformations are reshaping our daily work as developers.

GPT-5.5 Performance Boosts: Key Insights
I was knee-deep in parsing challenges when GPT-5.5 came along, and let me tell you, it's a game changer. But it’s not all roses. In the intricate world of Databricks, strategic setup is key. With impressive performance boosts and increased accuracy, GPT-5.5 is setting new standards, but you need to harness it wisely. I'll show you how I tapped into this power, from custom parsing techniques to multi-agent setups. Get ready to dive into the technical nitty-gritty and see how Codex 5.5 stands as the state-of-the-art model!