Building LLM Judges: Optimize with GAPA
I've spent years building AI systems, and if there's one thing I've learned, it's that having calibrated LLM judges is crucial. Let me walk you through how I use tools like the GAPA algorithm to optimize these evaluators, ensuring they're not just functional but effective. In AI development, the accuracy and reliability of LLM judges can make or break your system. With tools like GAPA and insights from subject matter experts, we can refine these judges to handle specific error types and continuously improve through a data flywheel approach. I'll detail how experts define evaluation metrics, the challenges of annotating conversation traces, and strategies for building multiple LLM judges for specific error types. With the GI algorithm reaching 61% accuracy on the validation set, we're hitting par to frontier. It's a game changer, but watch out for rushing through the steps.
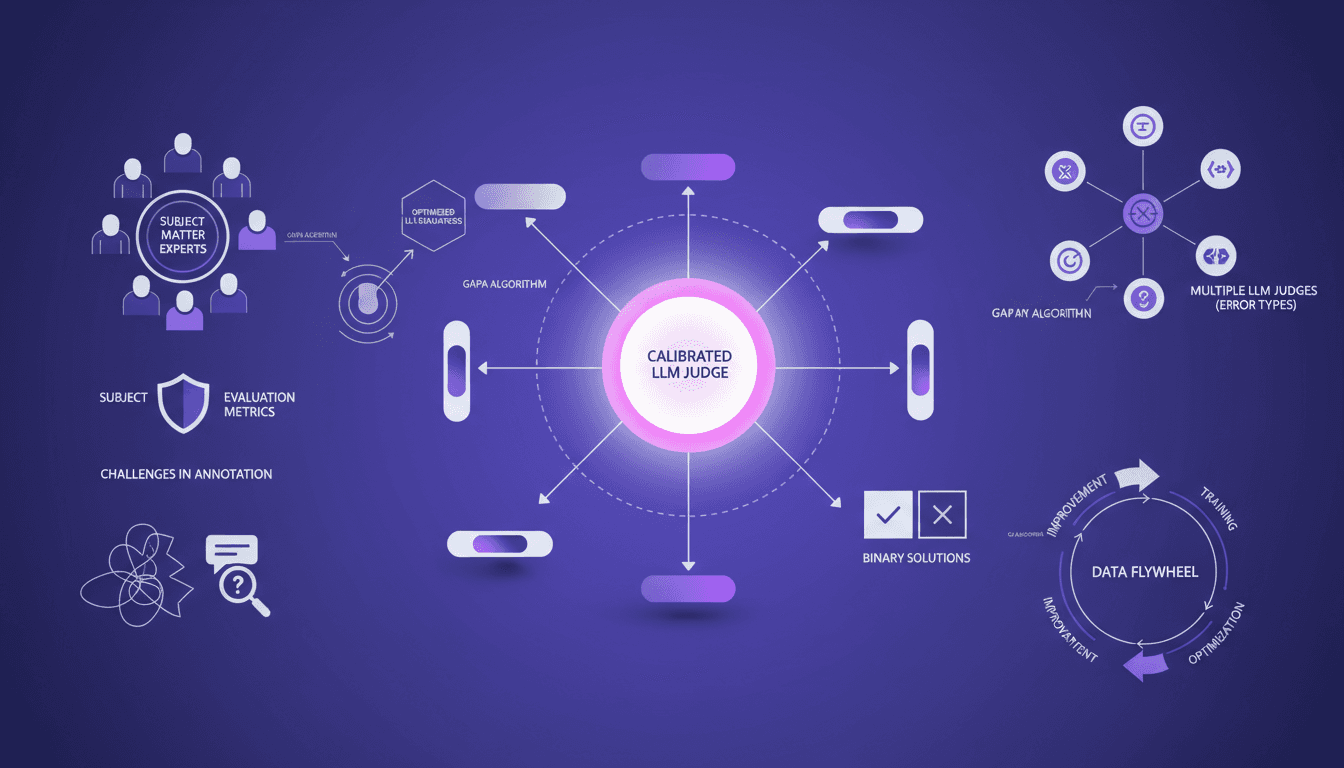
I've spent years fine-tuning AI systems, and trust me, calibrating LLM judges isn't optional; it's essential. Picture your system without it—like flying blind. So, let me walk you through my routine: I connect the GAPA algorithm, leverage insights from experts, and ensure these evaluators aren't just gadgets but hyper-effective tools. We're talking accuracy, reliability—two words that spell the difference between a project that soars and one that crashes. With GAPA, and a nudge from experts, I calibrate the judges to tackle specific error types and continuously improve—a real data flywheel. And then there's the GI algorithm hitting 61% accuracy on the validation set, does that speak to you? It's huge, but careful not to skip steps. We'll dive into the importance of evaluation metrics, the challenges of annotating conversation traces, and how to build multiple LLM judges for specific errors. You'll see, it's a game changer.
The Role of Calibrated LLM Judges
In the world of AI development, calibrated LLM judges are like the compass, guiding us through the maze of biased evaluations. Why are they so essential? Because they ensure our AI models are aligned with project goals, both in offline tests and online evaluations. I learned the hard way that without calibration, you might end up with a 98% compliance bias in initial setups.
To avoid the pitfalls of an uncalibrated judge, I steer these tools to ensure they're not just compliance followers. The key is aligning them with human annotations, which requires constant iteration, but it's worth it. Watch out: an uncalibrated judge could prioritize politeness over factual accuracy, which is far from ideal.
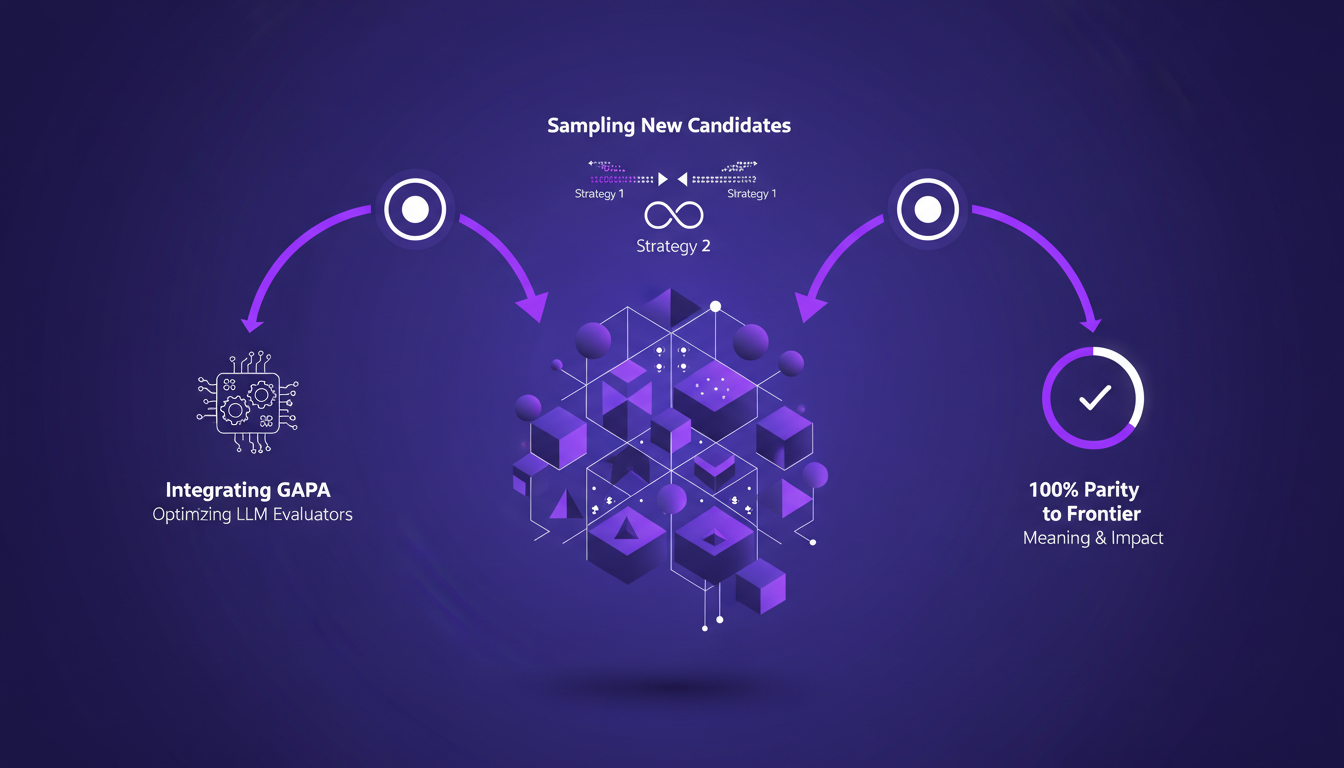
Optimizing with the GAPA Algorithm
When it comes to optimizing LLM evaluators, the GAPA algorithm is my go-to tool. I integrate it to optimize evaluators using two strategies for sampling in the GI algorithm. Achieving 100% at the par to frontier is crucial: it means reaching the maximum performance frontier.
But, of course, there are trade-offs. Sometimes, optimization pushes us to reach 61% accuracy on the validation set, which is decent, but not yet optimal. Balancing precision and performance is a delicate exercise, but necessary to maintain efficiency.
Defining Metrics with Subject Matter Experts
When I work with experts to define evaluation metrics, the challenge is to align their insights with technical needs. This is where binary solutions come into play. Instead of complicating with complex scoring systems, simplifying the learning process for LLM judges can be more effective.
Avoiding common pitfalls in defining metrics is essential. For instance, focusing too much on one aspect can give a biased view of the overall evaluation. Thus, collaborating with experts results in a more nuanced and tailored evaluation for specific use cases.
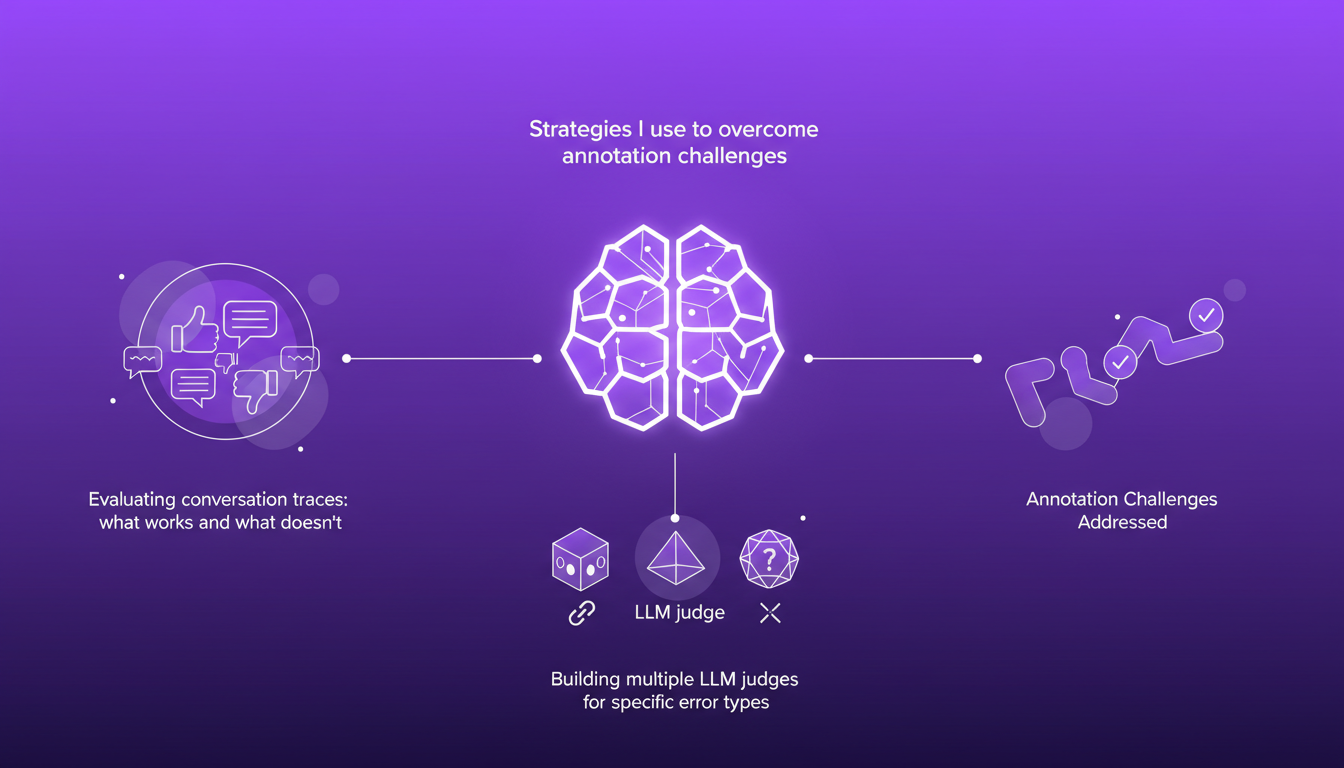
Addressing Annotation and Evaluation Challenges
Annotation can be a real headache, but I've developed some strategies to overcome these hurdles. Evaluating conversation traces, for example, requires a nuanced approach: certain error types like policy adherence issues or response style problems need specific handling.
Building multiple LLM judges for different error types is more effective than a single judge for overall evaluation. That said, watch out for common annotation pitfalls, like ignoring minor errors that can accumulate.
Continuous Improvement with the Data Flywheel
Implementing a data flywheel is the holy grail for continuous AI improvement. With constant feedback loops, we enhance the accuracy of LLM judges and maintain momentum in data cycles. Practical tips? Never underestimate the role of the GI algorithm in sustaining these improvements.
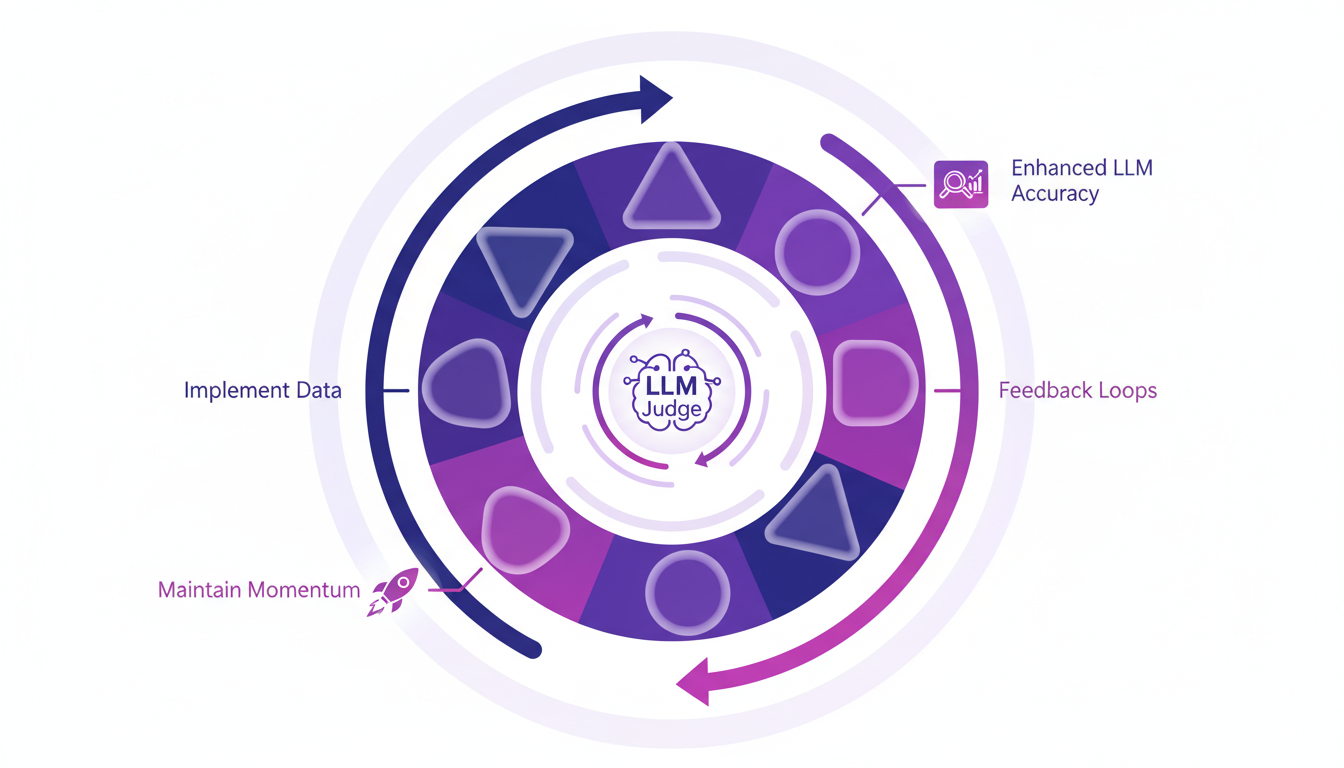
Ultimately, continuous optimization of your models involves careful observation of new data and real-time adjustments. Remember: the faster you go, the quicker you improve, but always keep a critical eye on data quality.
Building effective LLM judges isn't just about setting them up; it's a continuous process of optimization and collaboration with experts. First key takeaway: I use the GAPA algorithm to refine my LLM evaluators. It's a real game changer, hitting a 61% accuracy on the validation set. Then, I make sure to integrate subject matter experts to define evaluation metrics, because you can't know everything alone. Lastly, I tackle the challenges in annotating and evaluating conversation traces, which is often trickier than you'd think. With the right data flywheel, reaching 100% to the frontier is possible, but watch out for the limits: not everything is perfect from the start. Looking forward, I see a genuine transformation by integrating these strategies into our AI workflows. Now, I strongly encourage you to start integrating these strategies and witness the improvement in your system's performance. Check out the video 'Judge the Judge' by Mahmoud Mabrouk on YouTube for a deeper dive. It's like having a chat with a field-experienced colleague.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
Mythos: Revolution and Risks in Cybersecurity
I stumbled upon Mythos during a security audit, and it was a game changer. Imagine uncovering vulnerabilities that have been lurking for decades with an AI model that costs just about $50 per exploit. Incredible, right? But, it's not without its risks. In the cybersecurity world, Mythos is shaking up the landscape by discovering zero-day vulnerabilities that have evaded detection for years. But with great power comes great responsibility. Let's dive into how Mythos is revolutionizing the cybersecurity industry and what you need to keep an eye on.
AI's Impact on Web Development: Practical Approach
The first time I integrated AI into my web development workflow, it felt like adding a turbo engine to a classic car—everything was suddenly faster and more efficient. But beware, like any powerful tool, AI comes with its own set of challenges. Let's dive into how AI is reshaping web development. From code optimization to AI-driven browsers, we're facing a revolution. I've built two custom skills using a skill creator, and in just six months, the rising quality of AI models has changed the game for web developers. Let's explore how to navigate this new frontier.
Jetson Spark: Harnessing Local LLM Power
I've been hands-on with Jetson Spark, and let me tell you, running large language models locally is a game changer. I'll walk you through my setup, the pitfalls I encountered, and the real-world impact. With its 128 GB of unified memory, the Jetson Spark allows handling models with 200 billion parameters right on site. But watch out, without proper quantization and memory bandwidth management, you might get burned. By comparing local AI development with cloud solutions, I share my insights on model throughput and efficiency. If you're curious about how Jetson Spark stacks up against cloud solutions, this article is for you.
Cancer Treatment: AI and Single Cell Sequencing
I remember the day Sid Severy shared his journey with us. It wasn't just about fighting cancer; it was about rewriting the rules with AI and cutting-edge medical tech. Imagine leveraging AI and single cell sequencing to revolutionize a treatment plan. In this conference, I'll dive into Sid's story, a microcosm of how AI is redefining cancer treatment. We're talking personalized mRNA vaccines and navigating the FDA's Single Patient IMD approval process. Hold on tight, this is where tech meets medicine head-on.

Efficient Idea Exploration with Codex
I still remember the first time I integrated Codex into our workflow at Braintrust. It was like flipping a switch on our innovation process. Ideas that were previously just floating around transformed into concrete prototypes we could test and iterate in real time. In this article, I'll walk you through how Codex has revolutionized our approach to handling customer feedback and innovation. We're talking ultra-efficient idea exploration, real-time feedback handling, and a shortened feedback loop. With Codex, we actively engage our customers and generate high-quality feedback.