Jetson Spark: Harnessing Local LLM Power
I've been hands-on with Jetson Spark, and let me tell you, running large language models locally is a game changer. I'll walk you through my setup, the pitfalls I encountered, and the real-world impact. With its 128 GB of unified memory, the Jetson Spark allows handling models with 200 billion parameters right on site. But watch out, without proper quantization and memory bandwidth management, you might get burned. By comparing local AI development with cloud solutions, I share my insights on model throughput and efficiency. If you're curious about how Jetson Spark stacks up against cloud solutions, this article is for you.
When I first got my hands on the Jetson Spark, I didn't expect it to revolutionize the way I work with large language models. You see, having 128 GB of unified memory to handle models with 200 billion parameters locally feels almost unreal. But before diving headfirst, I learned the hard way that mastering quantization and memory bandwidth is crucial. That's where Jetson Spark really shines. I'll walk you through how I set up my environment, the mistakes to avoid, and most importantly, how it stacks up against cloud solutions. I'll also touch on the importance of time to first token for user experience. If you're in AI development, you know every millisecond counts. We'll also discuss real-world use cases and why, sometimes, staying local can be more advantageous than going to the cloud. So, ready for a practical deep dive?
Exploring Jetson Spark's Capabilities
The Jetson Spark, with its unified memory architecture of 128 GB, is a powerhouse for local AI development. I've managed models with up to 200 billion parameters on this setup. It's like juggling astronomical numbers on a system that fits under your desk. Local processing reduces latency and significantly improves the user experience. First, I connect to the memory architecture to leverage this power. Then, it's crucial to understand the trade-offs between memory capacity and memory bandwidth. Sometimes, more memory doesn't necessarily mean better performance.
"With Jetson Spark, I manage 200 billion parameter models without breaking a sweat."
Key takeaways:
- 128 GB unified memory architecture
- Handles models up to 200 billion parameters
- Reduces latency through local processing
Quantization Formats: Impact on Performance
The NVFB4 quantization format is critical for maintaining throughput without sacrificing quality. I've seen up to 14 billion tokens per second using NVFB4, which is impressive. Quantization reduces model size but watch out for potential accuracy trade-offs. Implementing NVFB4 requires understanding your model's specific needs. It's like tailoring a high-fashion mannequin: each model has its own peculiarities.
Key takeaways:
- NVFB4 maintains throughput even with larger models
- Up to 14 billion tokens per second achievable
- Understand the trade-offs in terms of accuracy
Time to First Token: Why It Matters
User experience hinges on the time to first token; faster is always better. Jetson Spark excels here, with minimal delay in token generation. A real-world example: I cut my response time by half using optimized settings. But be careful with model size; larger models can slow down the initial response.
Key takeaways:
- Time to first token crucial for user experience
- Jetson Spark delivers exceptional responsiveness
- Optimizing settings reduces response time
Model Throughput and Efficiency: A Practical Comparison
Comparing model sizes, I found a sweet spot for throughput versus efficiency. 1.5 billion tokens per second is achievable with the right configuration. Balancing throughput with power consumption is key to efficiency. Sometimes, smaller models deliver better real-world performance due to speed.
"Sometimes, a small and fast model is better than a big and slow one."
Key takeaways:
- 1.5 billion tokens per second achievable
- Balance throughput and power consumption
- Smaller models can outperform larger ones
Local AI Development vs Cloud Solutions
Running models locally on Jetson Spark reduces reliance on cloud services, cutting costs. Local development offers more control and privacy over data. However, cloud solutions still have the edge in scalability. Evaluate your project's needs: local for speed and control, cloud for scale.
Key takeaways:
- Cost reduction by using Jetson Spark locally
- More control and privacy over data
- Cloud solutions better for scalability
For more insights on AI orchestration challenges, check out Building AI Agents at Hex and Optimizing Generative AI Models with Quantization.
First off, Jetson Spark's 128 GB of unified memory is a game changer for local AI development. Handling up to 200 billion model parameters locally is impressive, but watch out for trade-offs. For example, time to first token is crucial for user experience, so you'll need to optimize carefully. Then, with 1.5 billion tokens per second for the 1.5 billion instruction model, efficiency is clearly there. But don't get carried away; quantization formats can impact model performance, so test according to your specific needs. Looking forward, I truly believe local AI development like this will revolutionize how we manage projects, balancing efficiency and cost-effectiveness. I encourage you to explore these capabilities and test Jetson Spark to see how it fits into your existing workflows. For a deeper dive, I strongly suggest watching the original video on YouTube.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
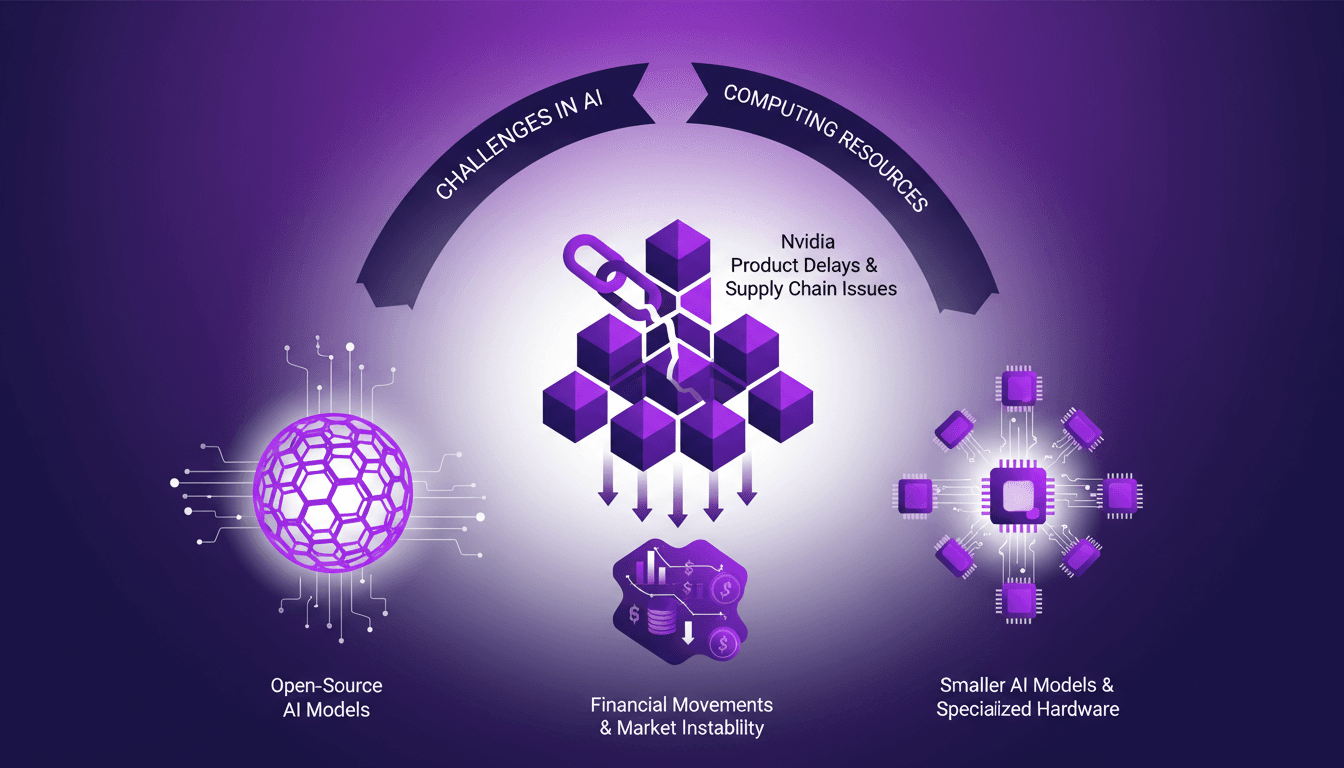
AI Resource Struggles: Nvidia Delays, Open Source
I remember the first time I hit a wall with AI compute resources. It felt like trying to run a marathon on a treadmill stuck at walking speed. In this rapidly evolving AI landscape, we're facing real challenges—from Nvidia's delays to the growing allure of open-source models. The market is in flux, with financial movements like Mistral's debt announcements adding another layer of complexity. We need to navigate resource shortages, the emergence of smaller AI models, and supply chain issues affecting component lead times. Let's dive into these dynamics from a practitioner’s perspective, focusing on practical solutions and trade-offs.
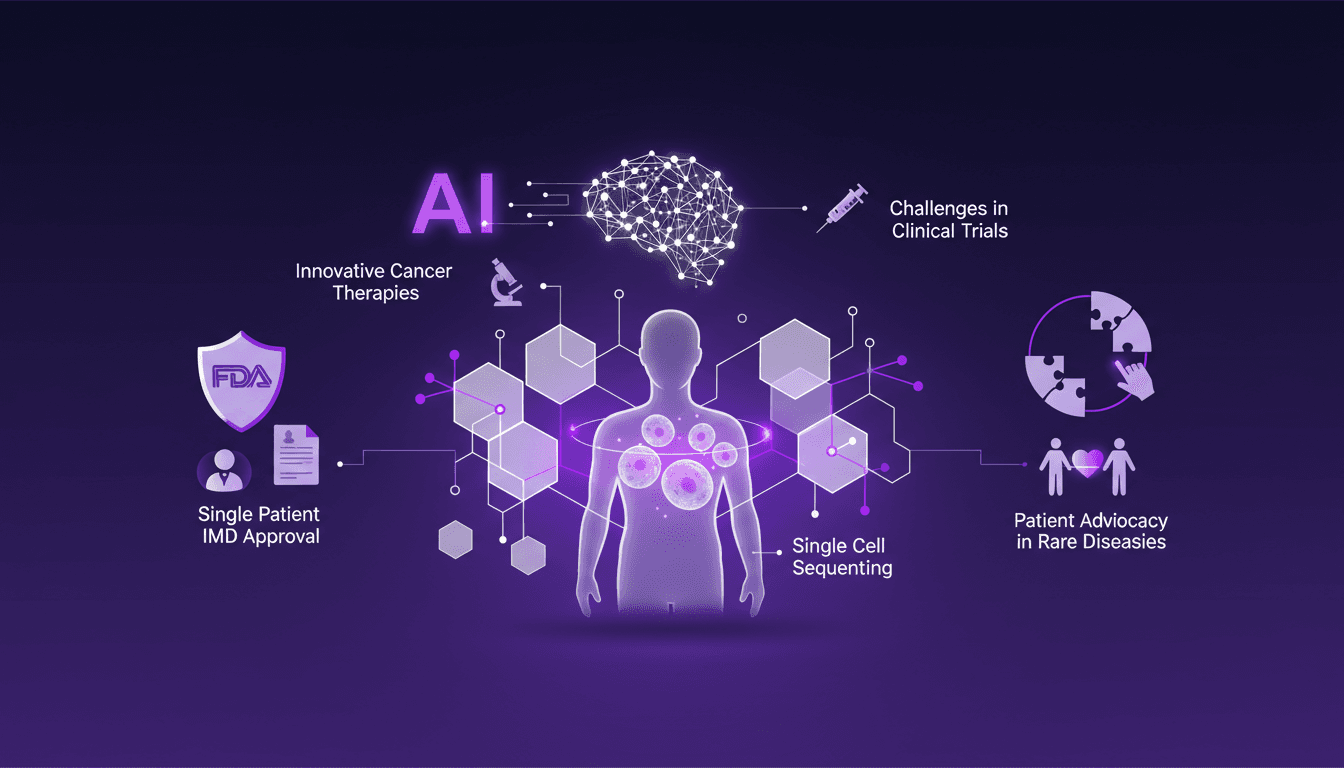
Cancer Treatment: AI and Single Cell Sequencing
I remember the day Sid Severy shared his journey with us. It wasn't just about fighting cancer; it was about rewriting the rules with AI and cutting-edge medical tech. Imagine leveraging AI and single cell sequencing to revolutionize a treatment plan. In this conference, I'll dive into Sid's story, a microcosm of how AI is redefining cancer treatment. We're talking personalized mRNA vaccines and navigating the FDA's Single Patient IMD approval process. Hold on tight, this is where tech meets medicine head-on.

Efficient Idea Exploration with Codex
I still remember the first time I integrated Codex into our workflow at Braintrust. It was like flipping a switch on our innovation process. Ideas that were previously just floating around transformed into concrete prototypes we could test and iterate in real time. In this article, I'll walk you through how Codex has revolutionized our approach to handling customer feedback and innovation. We're talking ultra-efficient idea exploration, real-time feedback handling, and a shortened feedback loop. With Codex, we actively engage our customers and generate high-quality feedback.
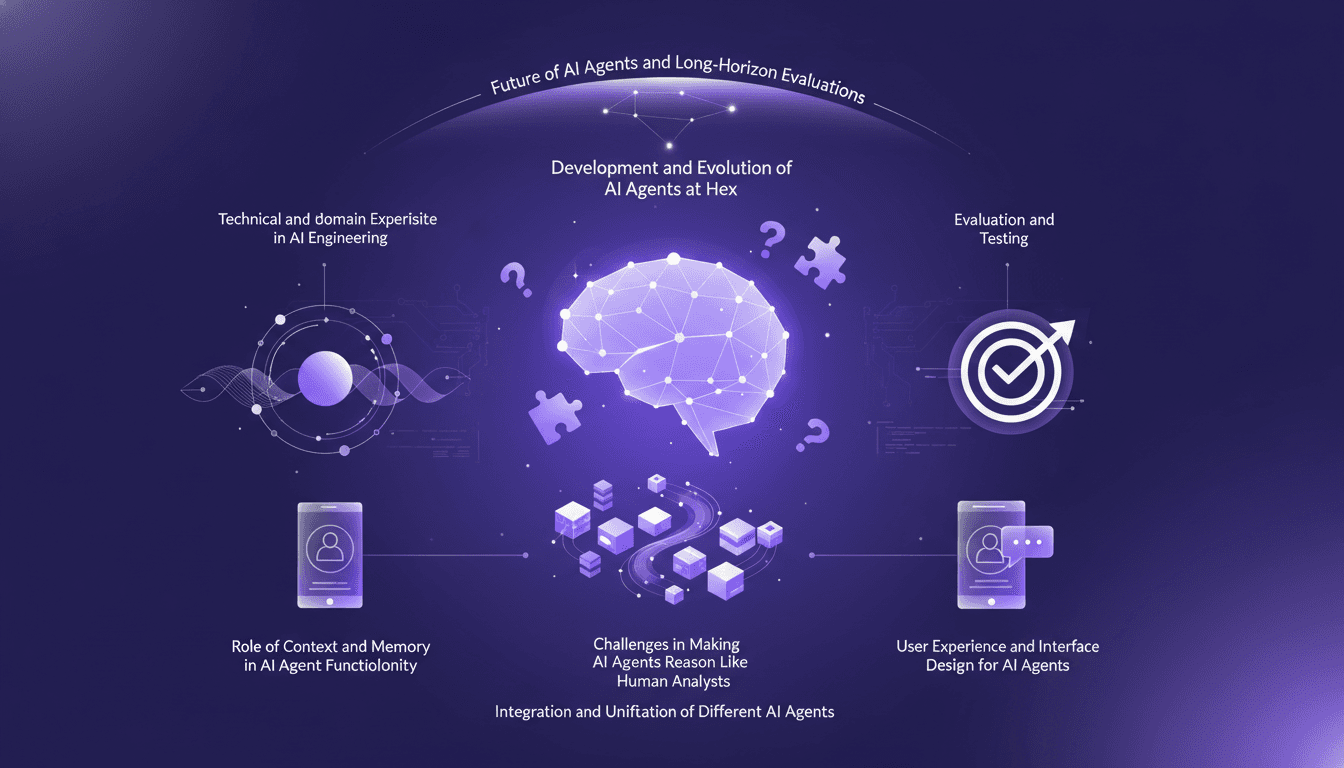
Building AI Agents at Hex: Workflow Challenges
At Hex, I've spent countless hours fine-tuning our AI agents to think like human data analysts. It's been a real journey, but every challenge brings us closer to our goal: creating agents that can reason accurately. First, I connect the various systems, then I test them (and sometimes I get burned). Integration and performance evaluation are crucial to avoid pitfalls like context overflow or poorly designed user interfaces. The key is user experience and contextual memory. Our aim? To reach 100% accuracy by day 90. We're not there yet, but every step counts. Join me in this adventure where technical expertise meets practical application.
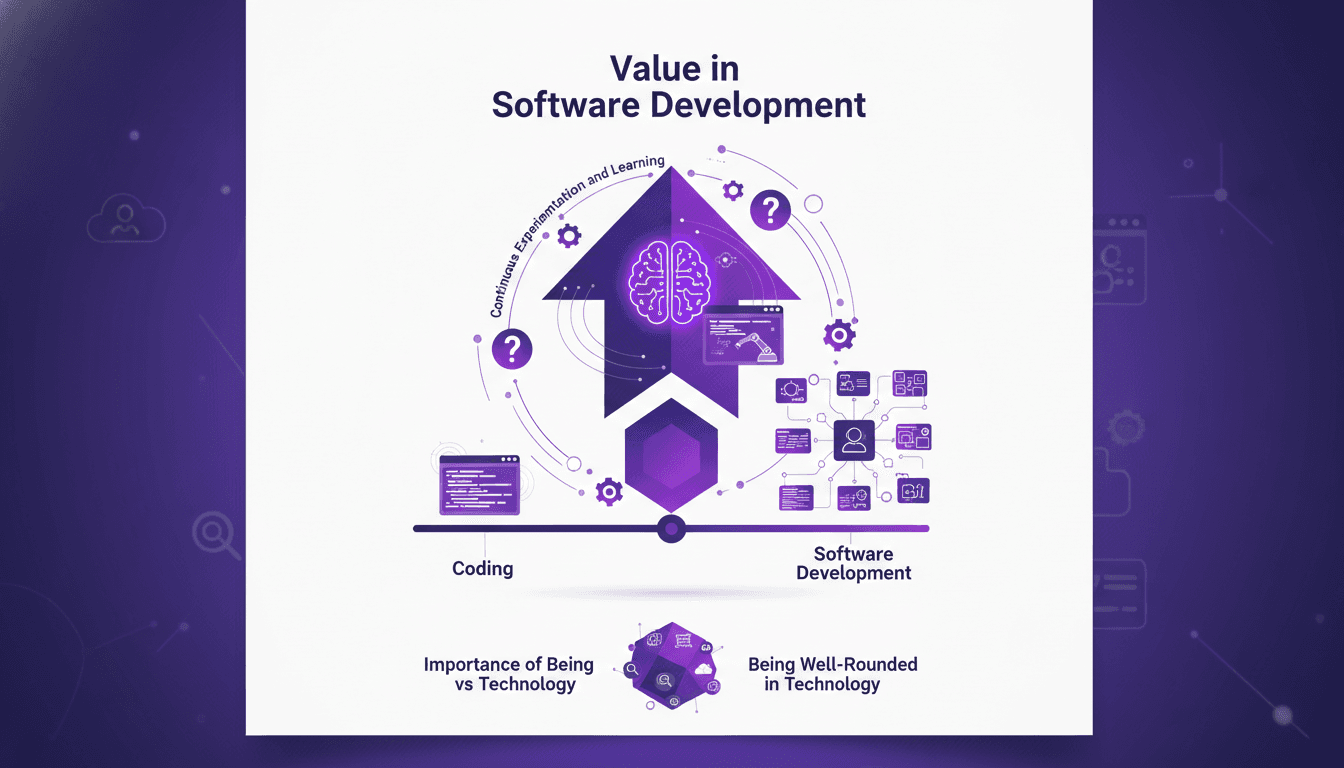
Software Development: Fast Coding, But at What Cost?
I've been coding at breakneck speed, but over time, I learned that the real cost isn't just about how fast you type. Software development is a whole different game. You can code 55 times faster, but if you're not careful, costs can skyrocket. Let's dive into why coding is cheap, but software is expensive. We'll explore the importance of being well-rounded, the role of junior engineers and AI, and why continuous experimentation is key. It's in understanding the value beyond mere lines of code that successful projects are distinguished from costly failures.