AI Model Limits: What Still Falls Short
I've been knee-deep in AI models, testing and retesting, and let me tell you, there's still a lot they can't handle. I've been burned more than once by putting too much faith in these models. From the 'Busher benchmark' to Arena's voting system, I've seen where models shine and where they stumble. Let's dissect these limitations together and understand the real performance landscape. From recent cloud models to older ones like GPT and Gemini, there are clear trends and specific fields, like gaming, where performance still falls short. Ready to cut through the hype? Let's dive in!

I've been knee-deep in AI models, testing and retesting, and let me tell you, there's still a lot they can't handle. More than once, I've been burned by expecting them to handle everything seamlessly. From the 'Busher benchmark' to Arena's voting system, I've seen firsthand where these models shine and where they stumble badly. Let's sift through these limitations together and truly understand the performance landscape. Recent cloud models versus older ones like GPT and Gemini, it's a constant battle, and sometimes they still fall for nonsense questions. And then there are specific fields, like gaming, where performance just isn't up to par yet. So, let's cut through the hype and face the reality of where these models stand.
Understanding the 'Busher Benchmark'
I dove into the 'Busher benchmark', and let me tell you, it's not just a buzzword. It's a real litmus test for AI capabilities. With 155 questions, it covers a broad spectrum, but watch out for its blind spots. For instance, when I tested several recent models, I discovered that some had a troubling tendency to accept nonsensical questions without blinking.
This benchmark reveals a lot about the reasoning of models and their tendency to follow nonsense questions. It's surprising to find that even recent models, which should be more advanced, often falter when faced with such questions. This is where you really see the difference between a model that simply regurgitates information and one that interprets it intelligently.
"The Busher benchmark is a real eye-opener for understanding the limits of AI models."
Ultimately, the 'Busher benchmark' isn't just a measure; it's a window into how AI models handle absurd information. It highlights crucial gaps, even in models we consider advanced.
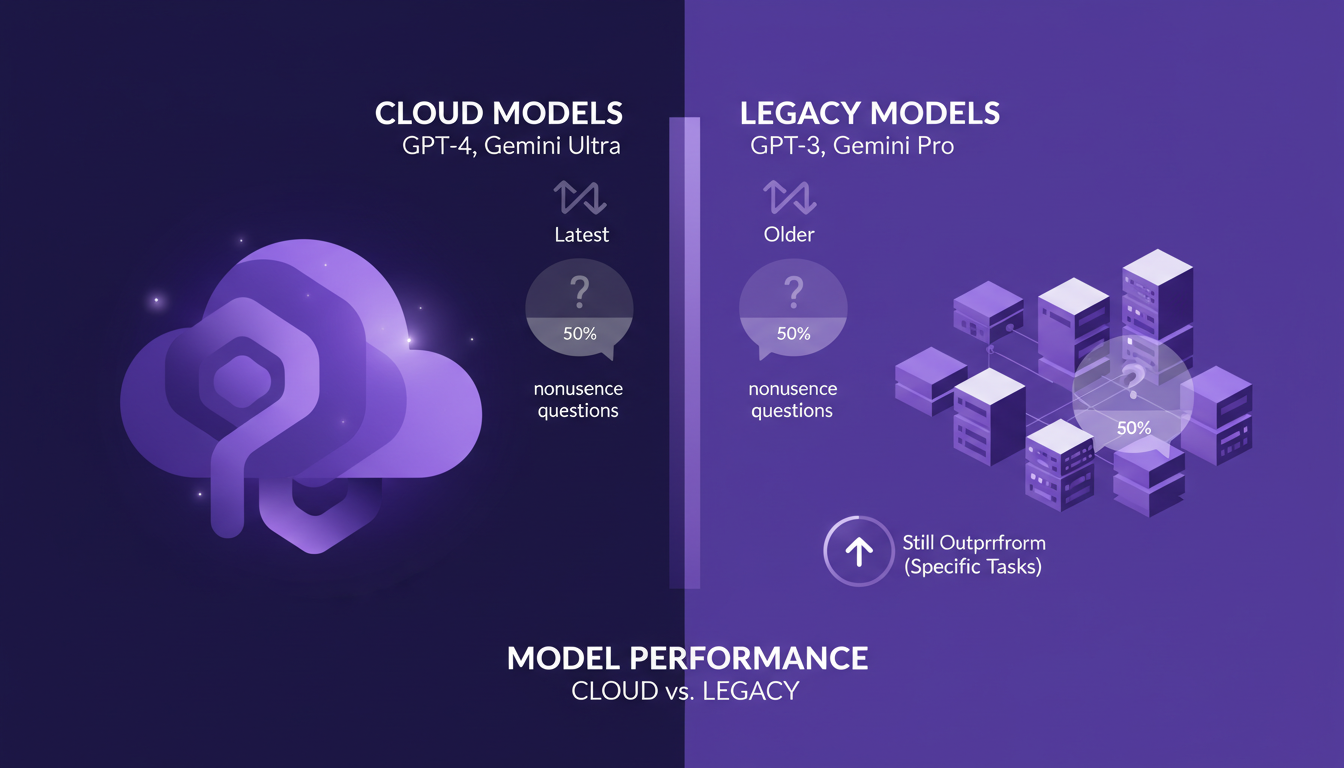
Model Performance: Cloud vs. Legacy
When I compare the latest cloud models to older ones like GPT and Gemini, I'm struck by a trend: a 50/50 split on their ability to handle nonsensical questions. Recent cloud models seem to resist nonsense better, but beware, it's not always the case. Sometimes, older models like GPT can still surprise with their performance in specific areas.
New models often offer impressive features, but there's a trade-off between these new features and consistency. For instance, in tests, I've noticed that some older models still outperform the newer ones in specific tasks, particularly when accuracy is more critical than novelty.
- Recent cloud models: tendency to resist nonsense better.
- GPT and Gemini models: 50/50 on nonsense questions.
- Trade-off between new features and consistency.
It's essential to keep these trade-offs in mind when choosing a model for specific applications. Improved performance in cloud models doesn't always compensate for the proven reliability of older models in all contexts.
Anthropic Models: Evolution and Insights
Since Claude 4.5, I've witnessed significant improvements in Anthropic models. Reasoning has played a crucial role in these improvements. By tracking 700 models, I've seen trends emerge, and while Anthropic models have shown advancements, limitations still exist.
The improvements observed don't mean everything is perfect. I've noticed that even with increased reasoning, some models don't necessarily perform better. It's a reminder that AI isn't just about more reasoning but about its proper application.
- Claude 4.5: significant progress since its release.
- 700 models tracked: trends and insights.
- Increased reasoning: not always synonymous with better performance.
These insights are crucial for understanding where and how to effectively deploy these models in real-world applications.
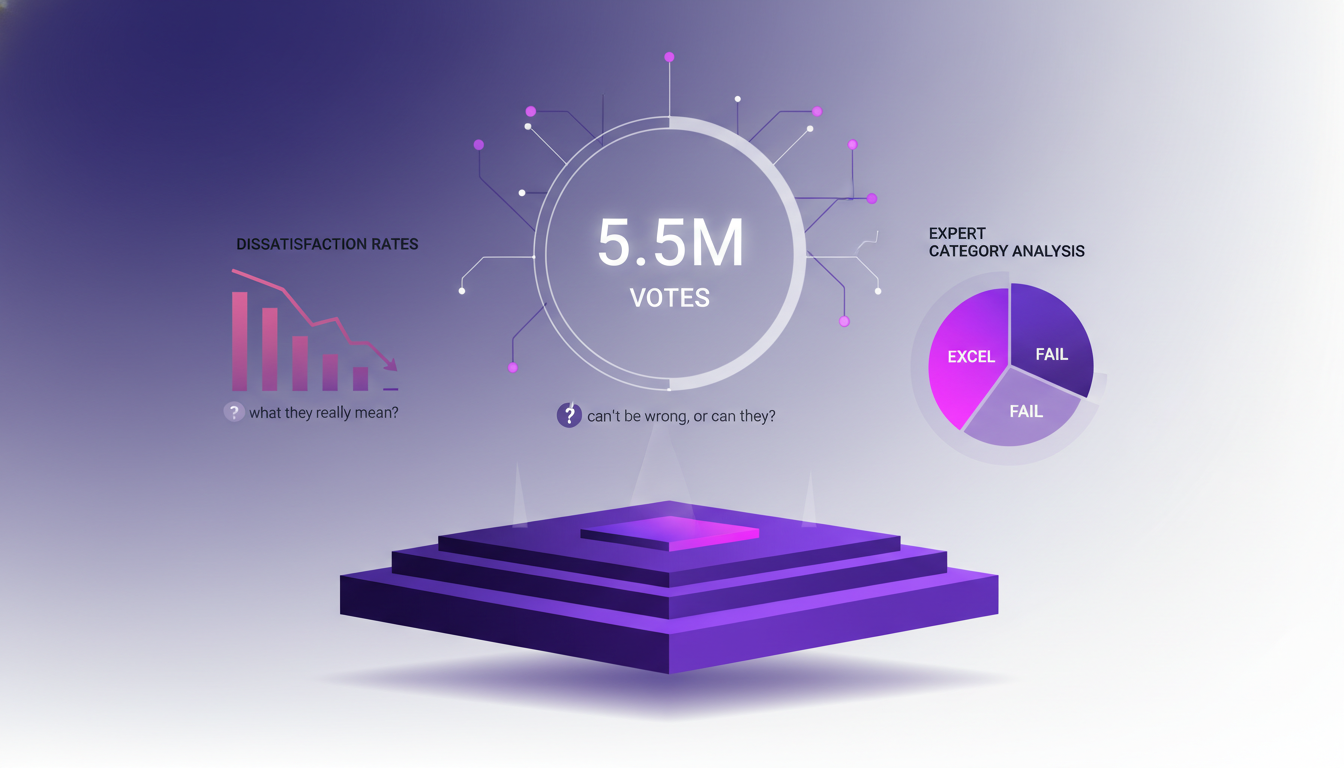
Arena Platform: Voting System and Analysis
Arena's voting system, with its 5.5 million votes, can't be wrong, right? Well, not so fast. When I delved into dissatisfaction rates, I found there were nuances. The dissatisfaction rate has dropped from 20% in 2017 to 9% today, showing improvement, but there are areas where models still fail.
Expert category analysis reveals that some models excel in specific areas, while others fail miserably. It reminds me that even with millions of votes, results must always be critically analyzed.
- 5.5 million votes: a lot, but not immune to errors.
- Dissatisfaction rate: from 20% to 9%.
- Expert category analysis: strengths and weaknesses of models.
These analyses are essential for understanding where models shine and where they stumble, influencing future decisions on their use.
Challenges in Specific Fields: Gaming and Beyond
I've explored AI's performance in gaming, and it's still a tough nut to crack. AI models struggle to outperform humans in complex games. This highlights specific challenges in niche areas. For example, in gaming, where decisions are often multidimensional and quick, AIs struggle to keep up.

Deploying AI in specific fields requires a delicate balance between innovation and practical application. I've noticed common pitfalls, such as overestimating AI's capabilities or ignoring its limitations.
- Performance in gaming: persistent challenges.
- Specific field challenges in niche areas.
- Common pitfalls: overestimating AI capabilities.
Ultimately, to succeed in niche AI deployments, one must not only innovate but also deeply understand the current limitations and capabilities of models.
So, after diving into the world of AI models, here are my takeaways:
- Tracked 700 models so far, and while they've come a long way, they're definitely not infallible. Knowing their limits is key to deploying them more effectively.
- The 'Busher benchmark', with its 155 questions, shows that even GPT and Gemini models can fall for nonsense questions about 50% of the time. So, keeping a critical eye is vital.
- Anthropic models have improved significantly over time, but watch out: reasoning is still a major challenge for all these models. Looking ahead? I'd say we're at a turning point—the models keep getting better, but staying informed and continuously testing is how we'll push them to their full potential. Check out Peter Gostev's video on Arena.ai for a deeper dive; it's essential if you really want to understand what these models still struggle with.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
First Impressions of GPT-5.5 by Claire Vo
I remember when I first dove into GPT-5.5. It felt like opening a toolkit with a new, sharper tool, ready to redefine how I handle coding tasks. Claire Vo shares her first impressions of this model that seems to push the boundaries of AI in software development. From autonomous code execution to bug fixing, there's a lot to explore. And with a 98% accuracy in fixing bugs, it's no empty promise. In this interview, Claire takes us through her discoveries, comparing GPT-5.5 with previous models and assessing its potential impact on the software development process.
Alibaba's AI: Open Source Revolution or Risk?
I've spent the last week diving deep into the latest AI advancements, and let me tell you, Alibaba's open-source model is shaking things up. But it’s not just Alibaba; from Cloud Opus 4.7 to interactive 3D models, the AI landscape is evolving faster than ever. With major players like Google and OpenAI also making significant strides, whether you’re a developer, a data scientist, or just an AI enthusiast, these changes demand your attention. Picture this: models capable of generating real-time interactive 3D worlds! The open-source versus proprietary models debate is becoming increasingly relevant. I've navigated these updates with the excitement of a kid in a candy store, but beware, there are pitfalls to avoid.
Bot Management: Challenges and Practical Solutions
I've spent years managing bots on X, and trust me, it's no walk in the park. Imagine putting six years of effort into an account, only to see it suspended by the anti-bot algorithms—painful, right? And that's just scratching the surface. With AI on the rise, voice identity theft is a growing nightmare, and tools like Open Close are changing the content game overnight. Media outlets are seeing their organic reach plummet, internet security's evolving... If you're a builder like me, facing these challenges head-on, stick around. I'm sharing concrete strategies to master AI and turn these hurdles into opportunities.
GPT 5.5: Revolutionizing Code and Workflow
I've been in the AI trenches for years, but GPT 5.5 is truly a game changer. I connected it to my usual workflows, refactored code, and even built knowledge graphs more efficiently than ever. This model isn’t just about incremental improvements; it redefines how AI can tackle complex problems. With a 10x speed improvement in running experiments, I can orchestrate entire projects end-to-end without worrying about the machine learning infrastructure. If you've ever been frustrated by the limits of previous models, now's the time to dive into GPT 5.5.
Tech Stack: Building a $25K/Month App
I remember the moment I realized my timer app was pulling in $25K a month. Not a dream, but a reality. Let me walk you through the tech stack that made this possible. In this article, I break down the tools, costs, and strategies powering my app, focusing on efficiency and cost management. Discover why Air Table is my go-to CRM, how Postmark handles our email communications, and the game-changing impact of an optimized development environment. We're talking real numbers here: $280 for servers, $250 on tools, and $1,400 on ads. No abstract theories—just concrete insights for those ready to build something profitable.