Construire un Agent AI en Temps Réel avec Cerebras
Je me souviens encore de la première fois où j'ai connecté un système Cerebras à mon workflow AI. La vitesse était époustouflante, mais j'ai vite compris que ce n'était pas qu'une question de vitesse. Il s'agit d'orchestrer efficacement chaque élément, du décodage spéculatif au transfert de données vocales en temps réel. Avec le Wafer Scale Engine 3 de Cerebras, on repousse les limites de l'inférence AI et des applications en temps réel. Dans cet article, je vous emmène dans les coulisses de la construction d'un agent de vente AI en temps réel, utilisant du matériel Cerebras, en comparant notamment avec les GPU Nvidia. On décode ensemble comment le décodage spéculatif et la technologie Live Kit transforment l'expérience utilisateur. Accrochez-vous, car on va parler de comment entraîner des agents de vente AI avec des LLMs et développer des systèmes multi-agents pour un support spécialisé. C'est parti !
Je me souviens encore de la première fois où j'ai connecté un système Cerebras à mon workflow AI. La vitesse était époustouflante, mais attention, ce n'est pas qu'une question de vitesse. C'est l'orchestration efficace de chaque élément qui fait la différence. D'abord, j'ai dû comprendre le décodage spéculatif, essentiel pour l'inférence rapide, puis j'ai intégré le transfert de données vocales en temps réel. Avec le Wafer Scale Engine 3 de Cerebras, qui compte 4 000 milliards de transistors et 900 000 cœurs, on entre dans une nouvelle ère de l'AI. Ce n'est pas juste de la théorie, c'est de la pratique pure : construire des systèmes AI plus intelligents et plus rapides qui révolutionnent notre manière de faire du business. Dans cet article, je vais vous montrer comment j'ai construit un agent de vente AI en temps réel. On comparera aussi avec les GPU Nvidia, et je vous expliquerai comment le décodage spéculatif et la technologie Live Kit transforment l'expérience utilisateur. On parlera aussi de l'entraînement des agents de vente AI avec des LLMs et de l'expansion vers des systèmes multi-agents pour un support spécialisé. Prêt à pousser les limites ? Allons-y !
Comprendre les Innovations Matérielles de Cerebras
Quand on parle de puissance de calcul, Cerebras place la barre très haut avec son Wafer Scale Engine 3. Imaginez une puce de la taille d'une assiette, bourrée de 4 trillions de transistors et 900 000 cœurs. C'est un monstre. Comparé aux GPU Nvidia, c'est un peu David contre Goliath, mais cette fois, David a une sacrée longueur d'avance. En termes de performance d'inférence, Cerebras surpasse ses concurrents de 20 à 70 fois. Pourquoi ? Grâce à une architecture qui élimine les goulets d'étranglement de la bande passante mémoire. Pas de transfert incessant de données entre les cœurs et la mémoire externe, tout est à portée de main sur la puce.
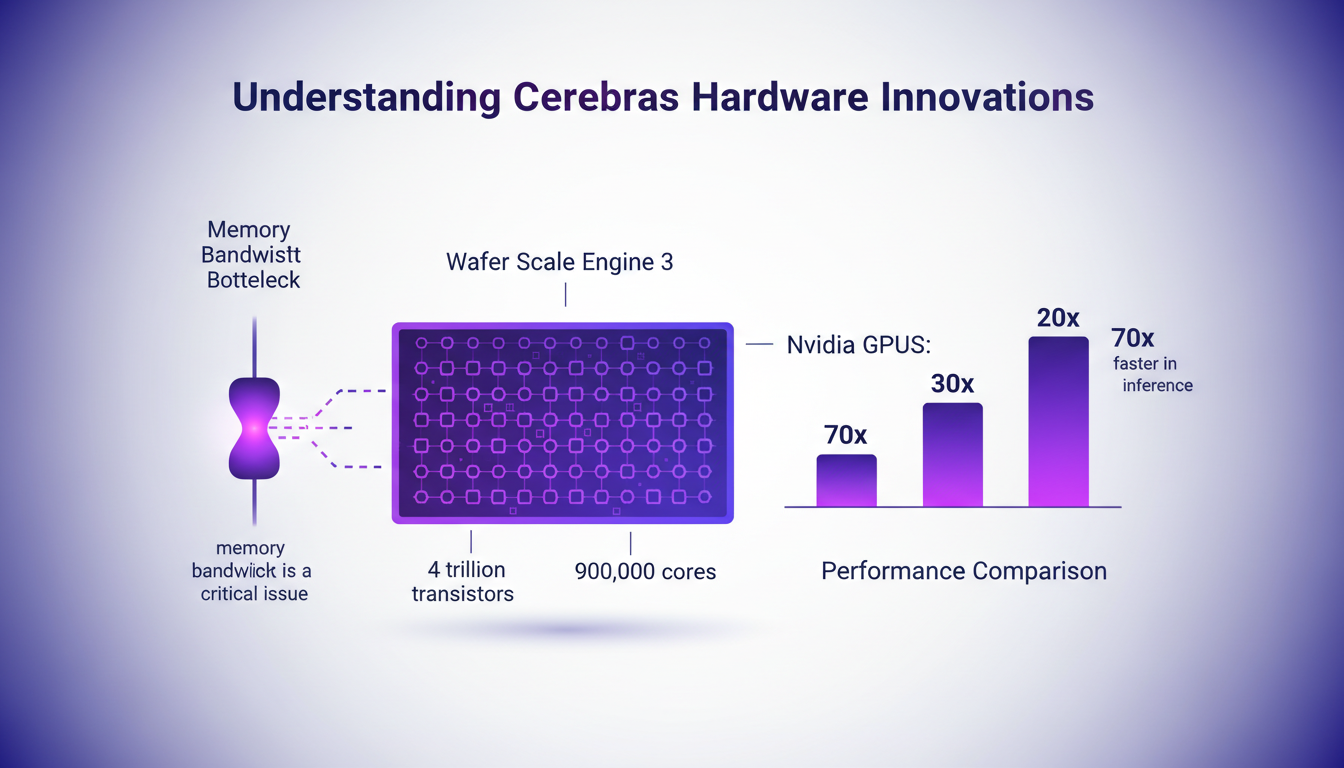
"Cerebras a résolu le problème du goulet d'étranglement de la mémoire, un véritable obstacle pour les GPU traditionnels."
Pour les développeurs IA, c'est une aubaine. Plus besoin de jongler avec les limitations matérielles. On se concentre sur l'optimisation de l'algorithme, pas sur le matériel. C'est un gain de temps et d'énergie considérable.
Construire un Agent Vocal IA en Temps Réel
Intégrer Cerebras dans un système vocal IA, c'est comme passer de la bicyclette à la voiture de course. D'abord, je connecte Cerebras à mon système d'IA. Ensuite, j'utilise le speculative decoding pour augmenter la vitesse d'inférence. Ce n'est pas qu'une question de rapidité, c'est aussi d'adaptabilité. Un bon agent vocal doit être précis, rapide, et capable de s'adapter aux demandes en temps réel.
Les défis sont nombreux : des problèmes de compatibilité aux ajustements d'algorithmes. Mais une fois ces obstacles surmontés, l'impact est direct. Un agent qui comprend et répond de manière fluide, c'est un atout majeur.
Spéculative Decoding : Accélérer l'Inférence
Le speculative decoding est un peu comme anticiper les besoins de votre voiture en course. On prédit les résultats possibles et on les teste en parallèle. Ça permet de gagner du temps, mais il faut trouver le bon équilibre entre vitesse et précision. Trop de vitesse, et on risque de faire des erreurs. Trop de précision, et on perd l'avantage de la rapidité.
J'ai vu des systèmes se planter parce qu'ils misaient tout sur la vitesse. Alors, comment éviter ça ? En calibrant finement l'algorithme et en surveillant les résultats en temps réel. Ça demande du temps, mais les gains en efficacité sont indéniables.
"L'impact sur les applications en temps réel est énorme, mais attention aux pièges de la vitesse excessive."
Exploiter Live Kit pour des Données Vocales à Faible Latence
Avec Live Kit, je transmet les données vocales en temps réel grâce au protocole WebRTC. C'est essentiel pour garder une latence faible et assurer une communication fluide. La détection d'activité vocale joue un rôle crucial. Elle permet d'identifier quand l'utilisateur parle et d'adapter le traitement en conséquence.

Orchestrer un système multi-agent, c'est un peu comme diriger un orchestre. Chaque agent a son rôle, et il faut s'assurer qu'ils travaillent tous en harmonie. Mais attention, trop de latence, et c'est la cacophonie. Il faut parfois sacrifier un peu de qualité pour garder la fluidité.
Former et Étendre les Agents de Vente IA
Pour former des agents de vente IA, j'utilise des LLMs (modèles de langage de grande taille). Ça commence par un entraînement précis et des appels d'outils pour étendre leurs capacités. Mais attention, la gestion des ressources du système est cruciale. Trop de ressources allouées, et le système s'effondre.
Anticiper le futur, c'est s'assurer que le système est flexible et peut évoluer avec le marché. C'est là que l'expérience de terrain prend tout son sens. Chaque ajustement est une leçon apprise et une amélioration pour le futur.
"Former un agent IA, c'est préparer l'avenir tout en optimisant le présent."
En résumé, l'innovation de Cerebras, l'intégration de systèmes vocaux avancés, et l'utilisation de techniques comme le speculative decoding transforment la manière dont nous abordons l'IA aujourd'hui. Avec les bons outils et une approche pragmatique, on peut véritablement révolutionner le secteur.
Construire des systèmes d'IA en temps réel avec Cerebras, c'est un vrai bouleversement, mais il ne faut pas sous-estimer les défis. D'abord, j'ai dû maîtriser le décodage spéculatif pour optimiser l'inférence. Ensuite, j'ai géré le transfert de données à faible latence, une étape cruciale pour la performance. En orchestrant tout cela de manière intelligente, je peux créer des agents IA qui répondent aux exigences d'aujourd'hui tout en étant prêts pour les défis de demain.
- 4: Quatre capacités clés des agents vocaux à maîtriser.
- 4 trillions: Nombre de transistors dans le Wafer Scale Engine 3.
- 900,000: Cœurs dans le Wafer Scale Engine 3.
L'avenir s'annonce prometteur : en intégrant le matériel Cerebras dans nos flux de travail, on peut vraiment transformer nos systèmes d'IA. Vous voulez révolutionner vos systèmes d'IA ? Commencez dès aujourd'hui avec Cerebras. Pour une compréhension plus approfondie, je vous encourage à visionner la vidéo complète : lien YouTube.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
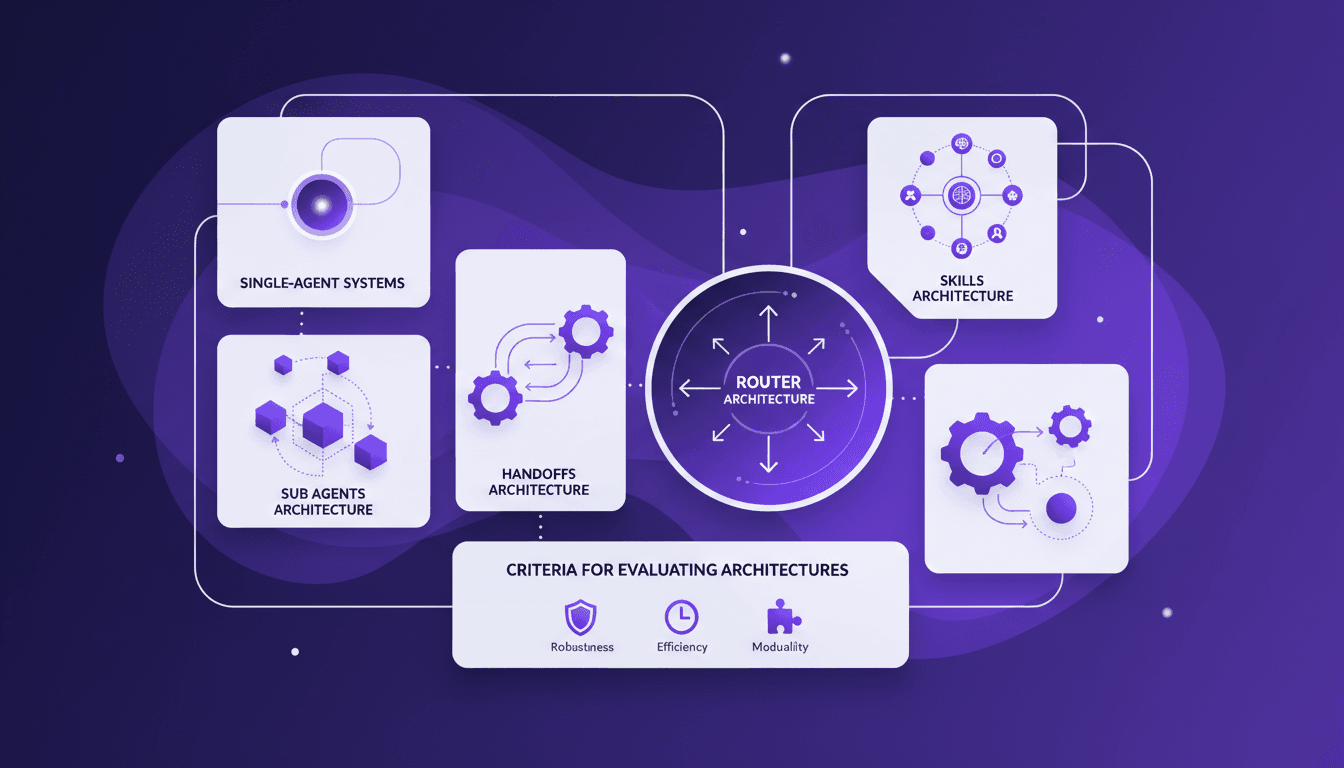
Architecture multi-agents : guide pratique
Je me souviens de la première fois où j'ai essayé d'implémenter un système multi-agents. J'étais submergé par le choix des architectures. Après quelques erreurs, j'ai finalement trouvé un workflow qui fonctionne. Parlons de comment vous pouvez choisir la bonne architecture sans maux de tête. Les systèmes multi-agents peuvent vraiment transformer la façon dont nous gérons des tâches complexes. Avec la bonne architecture, on peut distribuer efficacement la charge de travail et améliorer l'interaction. Mais attention, choisir la mauvaise peut vite devenir un cauchemar en termes d'efficacité et de scalabilité. Dans cet article, je partage mes expériences avec les architectures d'agents secondaires, de handoffs, de compétences et de routeurs. On discutera aussi des critères d'évaluation des architectures et pourquoi il peut être judicieux de commencer par un système mono-agent. Je vous partage mes erreurs et mes réussites pour que vous puissiez éviter les pièges. Prêt à plonger ?
Intégration IA chez Caterpillar: 100 ans d'innovation
Je me souviens encore de la première fois où j'ai vu une machine Caterpillar en action—c'était un vrai bouleversement dans le secteur de la construction. Avance rapide jusqu'au CES 2026, et nous parlons maintenant d'innovations pilotées par l'IA qui pourraient redéfinir toute l'industrie. Alors que Caterpillar fête son centenaire, ils repoussent les limites avec l'apprentissage automatique, en partenariat avec Nvidia. On ne parle pas juste de machines autonomes pour l'exploitation minière et la construction, mais d'un véritable écosystème d'autonomie et de connectivité. Et attention, avec l'introduction de leur assistant IA CAT, la promesse est claire : transformer la manière dont nous abordons le développement des compétences et l'avenir de l'autonomie dans ce secteur. Pas de promesses en l'air ici, juste des solutions concrètes qui visent à changer la donne.
Translate Gemma: Capacités Multimodales en Action
J'ai plongé dans Translate Gemma et, franchement, c'est un vrai game changer pour les projets multilingues. D'abord, je l'ai intégré dans mon infrastructure existante, et puis j'ai exploré ses capacités multimodales. Avec un modèle qui supporte 55 langues et des données d'entraînement couvrant 500 autres, ce n'est pas juste une question de langue—c'est une question de déploiement et d'optimisation pour vos besoins. Je vous montre comment j'ai fait pour que ça fonctionne efficacement, en passant par la comparaison des variantes de modèles, le processus d'entraînement et les options de déploiement. Attention aux tailles des modèles : 4 milliards, 12 milliards, jusqu'à 27 milliards de paramètres—c'est du lourd. Alors, prêt à voir comment je l'ai utilisé avec Kaggle et Hugging Face ?
Optimiser l'UX avec LangChain et Typescript
Je me souviens de la première fois où j'ai affronté des interfaces utilisateurs lentes en travaillant avec des outils d'agents. C'était frustrant, surtout quand on veut impressionner un client avec du traitement de données en temps réel. C'est là que j'ai commencé à intégrer des événements de flux personnalisés avec LangChain. Dans cet article, je vais vous montrer comment configurer une interface utilisateur réactive en utilisant LangChain, React et Typescript. Nous plongerons dans les événements de flux personnalisés, la fonction config.writer, et le déploiement avec le serveur de développement langraph. Si vous avez déjà perdu du temps avec des appels d'outils qui traînent, ce tutoriel est pour vous.
Embeddings Multimodaux Quen 3: Guide Pratique
Je me suis plongé dans les embeddings multimodaux de Qwen 3, avec l'objectif de rationaliser mes projets AI. La promesse ? Une précision et une efficacité accrues dans plus de 30 langues. D'abord, j'ai connecté les modèles d'embedding, puis j'ai orchestré les rerankers pour des recherches plus efficaces. Les résultats ? Un modèle qui atteint 85 % de précision, un véritable game changer. Mais attention, chaque outil a ses limites et Qwen 3 ne fait pas exception. Je vous explique comment j'ai configuré tout ça et l'impact réel que ça a eu.