Training an LLM from Scratch: Practical Guide
I remember the first time I decided to train a large language model from scratch. It felt like climbing a mountain with no map. But once you get the hang of it, it's like orchestrating a symphony. In this guide, I'll take you through my journey of building an LLM locally, inspired by Andre Karpathy's Nano GPT. We'll dive into tokenizer selection, Transformer model architecture, training parameters, and much more. I'll share the mistakes I made, the solutions I found, and how I optimized for efficiency. This is a practical guide for anyone wanting to truly understand each step of the process without wasting time on unnecessary details.
I remember the first time I decided to train a large language model from scratch, right on my local setup. It felt a bit like climbing a mountain without a map—daunting and exciting at the same time. But once you start taming the beast, it's a real thrill, like orchestrating a symphony. In this guide, I'll walk you through how I tackled this monumental task, inspired by Andre Karpathy's Nano GPT. I'll talk about tokenizer selection, a crucial step I initially underestimated, the Transformer model architecture, and how I fine-tuned the training parameters. But beware, there are pitfalls—I got burned more than once, especially with data quality and loss functions. We'll also dive into inference techniques and evaluation, not forgetting the unique challenges of audio and multimodal models. If you're ready to roll up your sleeves and dive into the technical details, this guide is for you.
Setting the Stage: Choosing the Right Tokenizer
When it comes to training language models (LLMs), selecting the right tokenizer is crucial. I’ve been burned before by underestimating its importance. First, there’s what we call character-level tokenization. It’s simple, really. You have 65 possible tokens, which makes the calculations more digestible for the model. But watch out, this can quickly become a headache for understanding correlations between tokens. Bi-grams can help better structure the data, but again, you have to orchestrate it well.
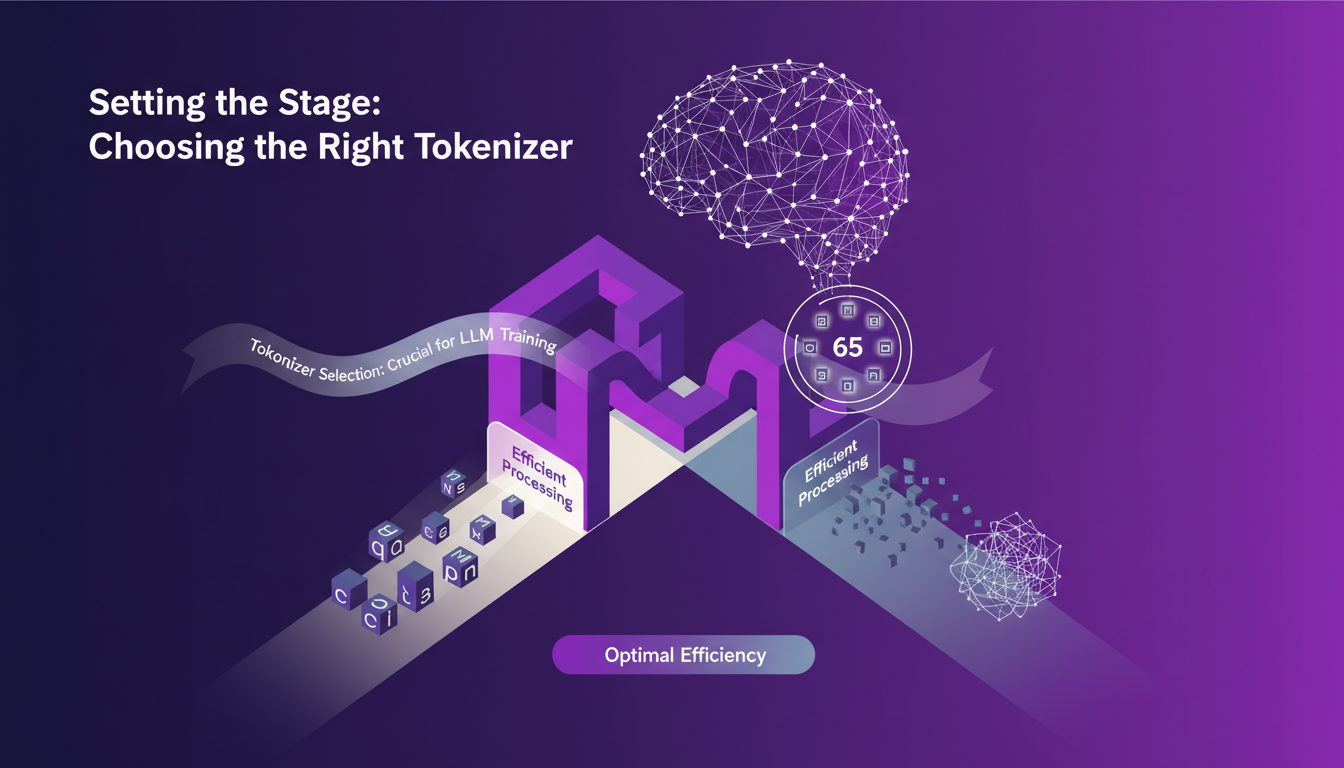
At my agency, I initially opted for a full tokenizer with a large number of tokens. Bad idea. The lack of convergence was glaring. You need to know that the simplicity of character-level tokenization can be an asset, especially when starting out or when data is limited. Remember: too much complexity can lead to performance issues.
Decoding the Transformer Model Architecture
Transformers are fascinating but complex. First, there’s the multi-head self-attention. This allows the model to focus on different parts of the data simultaneously. Then, residual connections help prevent information loss at each layer.
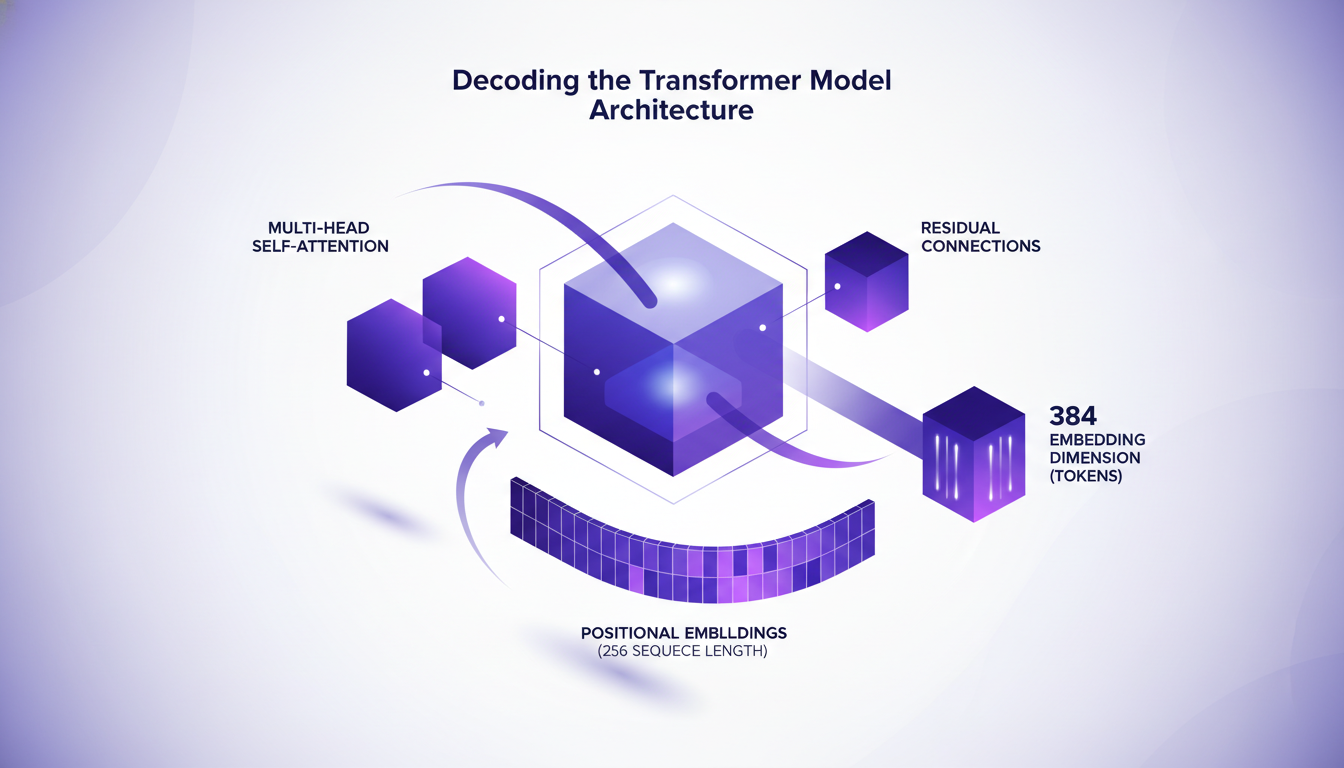
Next, there are the positional embeddings. With a sequence length of 256, the model "knows" where each token is located. For my part, I chose a token embedding dimension of 384. Why? Because it’s a good compromise between complexity and performance. However, don’t forget that the larger the dimension, the higher the computational cost.
Optimizing Training Parameters: What Works
For training, the loop is crucial. My approach: dynamically adjust learning rates. The cross-entropy loss is often used but watch out for deviations. The Kullback-Leibler (KL) divergence is a good complement for assessing the difference between predicted and actual distributions.
There are key moments when the model starts to understand context. You see it when it produces more coherent outputs. But beware of poorly configured learning rate schedules; they can derail the entire training.
Inference Techniques: Making Sense of Outputs
In inference, I often play with temperature sampling. This allows for varying the "creativity" of the outputs. Too low, and the text is monotonous; too high, and you get gibberish. To evaluate performance, I rely on practical metrics rather than theoretical ones.
When we talk about inference speed, you have to find the right balance with accuracy. Focusing too much on one can harm the other. And watch out for common mistakes: for instance, forgetting to normalize outputs can skew results.
Navigating Challenges in Multimodal and Audio Models
Integrating audio into LLMs presents unique challenges. Data quality is paramount. I’ve often had to reevaluate my datasets to ensure they are rich and varied enough.
For example, when integrating both audio and textual data, models can get confused if the data isn’t well-aligned. Looking to the future, I see interesting directions, but some questions remain unanswered, notably on how to effectively tokenize voice and music simultaneously.
- Selecting the right tokenizer is crucial to avoid convergence issues.
- Multi-head attention, residual connections, and positional embeddings are the pillars of Transformers.
- Optimize your learning rates for effective and stable training.
- Balance precision and speed during inference.
- Data quality is essential in multimodal models.
I took on the challenge of training an LLM from scratch and found out it was more of a journey of discovery than just a technical task. Each step, from tokenizer selection to tackling multimodal challenges, taught me something new. Here are the concrete takeaways:
- Tokenizer Selection: I went with character-level tokenization with 65 possible tokens. It's flexible, but watch out for sequence explosion.
- Model Architecture: I set 256 as the sequence length with 384-dimension embeddings. It's a solid standard but it can be memory-intensive.
- Training Parameters: Don’t skimp on optimization; it’s a game changer. But, over-iterating can slow you down.
The future of LLM training is exciting. We can always refine and try new approaches. Ready to start your own LLM training adventure? Share your experiences and let's keep the conversation going. For more insights, check out Angelos Perivolaropoulos' original video: Training an LLM from Scratch, Locally. It's packed with nuggets for builders like us.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
Building Context as Code: My Approach
I remember the first time I heard 'context is the new code'. It was like a light bulb moment. Suddenly, everything clicked. I realized that context isn't just a backdrop—it's a dynamic, living part of our development cycle, much like the code itself. In today's rapidly evolving tech landscape, understanding and leveraging context can be a game changer. It's no longer just about writing efficient code; it's about orchestrating the right context around it. Here's how I tackle this challenge in my daily workflow, integrating context into every phase, from development to optimization. We'll cover security, testing, and how to distribute this context because, trust me, I've learned some lessons the hard way. Get ready to see context from a new perspective.
Recursion in AI: Transforming Models
I've spent countless hours tweaking AI models, and let me tell you, recursion is the game changer we've been waiting for. Forget the race for more parameters; now it's about intelligence. While traditional models hit scaling walls, recursion offers a fresh perspective. We're diving into how it could redefine AI efficiency and capability. We'll discuss hierarchical reasoning models, tiny recursive models, deep equilibrium learning, and the challenges of optimization. If you've ever been frustrated by scalability limits, you're going to love this new paradigm.
Using a Sandbox for Your Cloud Agent
I dove headfirst into testing our cloud agent SDK in the E2B sandbox, and let me tell you, it was a rollercoaster ride. From initial setup to deployment, I faced security hurdles and unexpected twists that kept me on my toes. In the world of cloud environments, security and efficiency are paramount. Whether you're adapting an SDK or managing API keys, the challenges are real. Here's my journey through the E2B sandbox, tackling these issues firsthand. I faced security concerns with API keys and deployment issues on Render due to security protocols. Don't get caught off guard by the pitfalls of sandboxing—follow my journey and learn how to navigate these challenges.
Setting Up Claude Co-work: A Builder's Guide
I still remember the first time I set up Claude Co-work. It was like opening a toolbox with endless possibilities. But let's be honest, it wasn't all smooth sailing. After getting burned a few times, I finally navigated the setup, features, and customization to make Claude Co-work a real asset in my projects. Whether you're a beginner or have some experience, understanding how to make the most of this AI assistant is crucial. Let's dive in, and I'll show you how to turn Claude Co-work into a powerful ally.
Set Up Codex in a Few Clicks for Time Savings
I remember the first time I set up Codex. It felt like unlocking a new level of productivity. With just a few clicks, I had my projects and tools seamlessly integrated. Let me show you how I did it, and how you can too. Codex is all about streamlining your workflow—whether you're transferring projects, integrating systems, or prepping for meetings, it's a game changer. The key is setting it up efficiently. I connected my systems to Codex, integrated Google Calendar, Gmail, and Slack, and saw an immediate transformation in my time management. I'll walk you through these steps so you can maximize your efficiency with Codex.