Optimizing Inference Chips for AI Agents
I've spent countless hours orchestrating AI agent workflows, and let me tell you, the right chip makes all the difference. But when I see current GPUs only hitting 30-40% utilization, it's clear we need purpose-built silicon. This article dives into the challenges and innovations in AI chip design, focusing on practical solutions for builders like us. We explore Nvidia's $20 billion acquisition of Groq, the role of compilers, and the promises of Google's TPU v7. In short, everything you need to optimize your AI agent loops.

I've spent countless hours orchestrating AI agent workflows, and let me tell you, having the right chip is crucial. The reality is, our current GPUs are maxing out at just 30-40% utilization. This makes it clear: we need silicon purpose-built for these tasks. That's where we dive in—Nvidia's $20 billion acquisition of Groq highlights the push for tailored solutions, and Google's TPU v7 is a real gem for inference. But remember, it's not just about the hardware. Compilers play a huge role in AI chip performance. So, if you want to optimize your AI agent loops, you need to understand the current challenges and know where to put your money. What I'm offering here is a deep dive into purpose-built silicon for our agents, with concrete solutions for us, the builders in the field.
The Limitations of Current GPUs in Agent Workflows
In the realm of agent workflows, traditional GPUs are like pedestrians on a highway. I'm not kidding. They struggle to reach only 30 to 40% of peak utilization, which is ridiculous given their potential. The problem? These workflows require rapid context switching (and the average GPU doesn't like that). Agents don't follow the standard inference model - it's more of a complex ballet of task switching that leaves the GPU behind.
So why aren't GPUs up to the task? For a simple reason: they're designed for massive, continuous tasks, not these little hops. When I pilot these agents, I clearly see longer processing times and rising costs. That's when I think it's time to rethink our approach.
- Utilization: 30 to 40% of peak utilization.
- Context switching: Poor capability to handle rapid switches.
- Costs: Increased costs due to inefficiency.
Why Purpose-Built Silicon is a Game Changer
Purpose-built silicon is like giving a GPS to a lost hiker. With Nvidia's $20 billion acquisition of Groq, it's clear the industry is taking this direction seriously. These chips are specifically designed for these agent loops, and I say bravo! Why? Because they finally understand what I need: efficient management of these complex loops.
These chips reduce costs by optimizing utilization and improving performance. I've seen it with my own eyes. When I integrated these dedicated solutions, the difference was noticeable: less latency, more fluidity. And frankly, it's a relief.
- Acquisition: Nvidia invested $20 billion in Groq.
- Optimization: Better management of agent loops.
- Cost: Cost reduction through improved utilization.
The Role of Compilers in Chip Performance
I've been burned several times before fully understanding the importance of compilers. These tools are crucial for getting the most out of your hardware. They optimize code execution, enabling more efficient use of the hardware. If you neglect this aspect, you're depriving yourself of a significant performance boost.
To maximize your results, it's essential to understand how these compilers work. I recommend diving into their functionality and integrating them into your workflow as soon as possible. My advice? Don't underestimate their power.
- Optimization: Compilers optimize code execution.
- Performance: Significant improvement in hardware performance.
- Tip: Invest time to understand their functionality.
Exploring Google's TPU v7 for Inference
Google hit it big with their TPU v7, and honestly, I'm impressed. Built specifically for inference, it handles context switches at a crazy speed. And that's where speculative decoding comes into play, a concept that, when used well, can transform the way you manage agent workflows.
Integrating these TPUs into my projects, the gains in speed and latency reduction are undeniable. It's literally a new dimension opening up for us.
- Architecture: Optimized for rapid context switching.
- Speculative decoding: Improves workflow management.
- Real-world impact: Faster processing and reduced latency.
Navigating Design Gaps and Future Innovations
I'm not going to lie, there are still gaps to fill in AI chip design for agent loops. But innovation never stops, and solutions are emerging. Balancing cost, performance, and efficiency remains a constant challenge, but strategies to achieve this are being perfected.
To stay ahead, you have to pilot differently. I recommend exploring new technologies and adapting quickly. It's the only way to remain competitive in this constantly evolving landscape.
- Gaps: Current design still imperfect.
- Innovations: Solutions are emerging to fill these gaps.
- Strategy: Adopt and integrate new technologies quickly.
For more insights on the future of semiconductors, check out our article on Supply Chain 2.0: Revolutionizing Semiconductors.
In the realm of AI agent workflows, picking the right chip is a real game changer for performance. With innovations like Google's TPU v7, purpose-built silicon truly stands out. But watch out, current GPUs only hit 30 to 40% of their peak utilization on these workloads, which can be a bottleneck. Nvidia's $20 billion acquisition of Groq underscores the significance of these advancements.
- First, to optimize your workflows, start by evaluating your current chip usage.
- Second, explore purpose-built solutions tailored to your specific needs.
- Third, keep an eye on new technologies like TPU v7 to enhance inference.
Looking ahead, I believe these technologies will redefine how we work. Plan to adapt your infrastructure to harness these innovations.
Ready to optimize your workflows? I encourage you to revisit your current chip usage and consider purpose-built solutions. For deeper insights, watch the original video: YouTube link.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics

Supply Chain 2.0: Revolutionizing Semiconductors
I've been knee-deep in semiconductor supply chains for years, and let me tell you, it's not just about making chips; it's about orchestrating a global symphony. First, you tackle the 1,400 process steps, then you navigate through a dozen countries. But what happens when a $300 chip holds up a $50,000 car? That's when things get real. With AI chips at the forefront, every step from manufacturing to delivery must be optimized. Let's dive into how we're handling these challenges and where the opportunities lie.
Dipsic V4: AI Revolution, Challenges OpenAI
I've been in the AI trenches for years, watching models evolve. But when I first got my hands on Dipsic V4, I knew we were onto something game-changing. With 1600 billion parameters, this model isn't just another tool in the landscape; it’s a potential disruptor in a space dominated by giants like OpenAI's GPT 5.5. Let me show you why this model is causing such a stir and how it’s rewriting the rules. We’ll dive into its innovative features, aggressive pricing strategy, and what it means for players like Nvidia and OpenAI. Watch out, this could be a game changer.
Error Reduction in GPT-5.5 with Databricks
I dove into GPT-5.5 with Databricks, and let me tell you, the improvements are not just theoretical. After integrating it into my workflows, I saw a 46% error reduction compared to 5.4. The performance boost, especially with the Agent Supervisor API, is impressive. Parsing quality and task performance have clearly upped their game. Needless to say, my custom agents, with Databricks tools, are now more efficient. But watch out, it's not all perfect; you need to handle these new tools with care to avoid pitfalls. This update, I must admit, has directly impacted my projects, and I'm not stopping here.
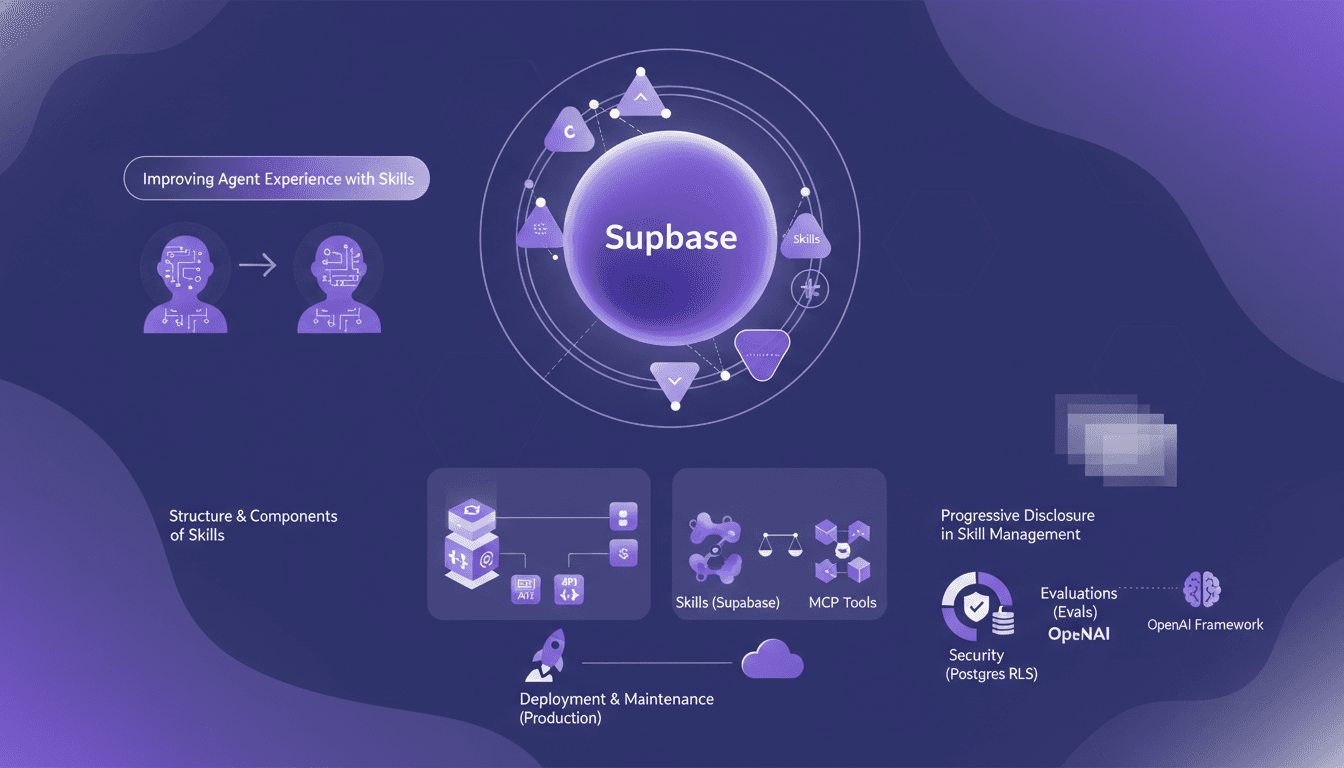
Boosting Agents with Supabase Skills: Our Approach
I spent two months knee-deep in Supabase, crafting skills for our AI agents. Let me walk you through how we made them not just good, but actually effective. In this article, I dive into our approach to enhancing agent experience with Supabase, dissecting the structure and components of skills, and comparing them to MCP tools. We've leveraged evaluations to test agent behavior, not to mention the pivotal role OpenAI’s framework played. From RLS in Postgres to deploying in production — each step came with its hurdles. I’ll explain how I orchestrated all of this and, importantly, what I wish I'd known earlier.
Ralph Loops: Building Simple, Effective AI
I remember the first time I built a Ralph Loop. It was like finding a missing puzzle piece in AI-driven development. Not just theory, but a real workflow that changed how I orchestrate tasks. These loops streamline automation using AI models like GPT 5.8, offering a practical, no-nonsense approach. Imagine orchestrating tasks seamlessly while addressing the challenges and benefits of using AI in software development. In this article, I'll take you through Ralph Loops, their practical applications, and how they can truly transform your workflow. Let's dive into the limits, security and ethical considerations, and scaling these processes in team environments. Yes, the future of AI in automating complex workflows is already here. Ready to dive in?