Optimizing AI Models: Our Practical Approach
I saw a gap in the market for small model inference, so I decided to build the infrastructure myself. With over 3 million models on Hugging Face, the lack of effective infrastructure was glaring. Why is this important? Because small models play a crucial role in AI search and document processing. And the challenges? There were plenty, but I tackled them head-on. From context rot to optimizing agent workflows, each step was a learning curve. I orchestrated model swapping for efficient GPU usage while supporting various open-source architectures. In short, we filled a market gap with a robust, scalable solution.
A few months ago, while browsing the models on Hugging Face, one statistic caught my attention: 3 million models. Yet, despite this abundance, the infrastructure for small model inference was almost non-existent. So, I rolled up my sleeves and decided to build that infrastructure myself. Why? Because in the AI space, small model inference is a cornerstone for search and document processing. In this talk, I'm going to share how I tackled the challenges head-on: managing context rot, enhancing agent workflows, and optimizing GPU usage through model swapping. We supported various open-source models and architectures, all with a scalable and robust solution. So, let's dive into the technical details together and see how filling this gap transformed our approach to AI models.
Identifying the Market Gap for Small Model Inference
I've always been struck by the lack of adequate infrastructure for small model inference, especially considering their importance in AI search and document processing. That's where I sensed a real gap in the market: many solutions focus on large models but neglect the small ones, which are essential for specific tasks. There is a glaring inefficiency in current inference solutions, something I've noticed after a few years of experience in AI. My article on Substack, published a few months ago, had already drawn attention to these issues. It was no surprise when I decided to build a solution to fill this void.
A key figure to keep in mind: There are currently nearly 3 million open-source models on platforms like Hugging Face. With such diversity, infrastructure must be ready to handle these models efficiently.
Tackling Challenges in Model Inference
One of the biggest challenges encountered is what I call "context rot." This is the degradation of quality that occurs as context increases, and it has a direct impact on workflows. Then there's the efficient use of GPUs. Existing open-source inference solutions often have limitations, particularly regarding GPU utilization efficiency. I've had to navigate through these obstacles, sometimes getting burned, but each mistake taught me something valuable.
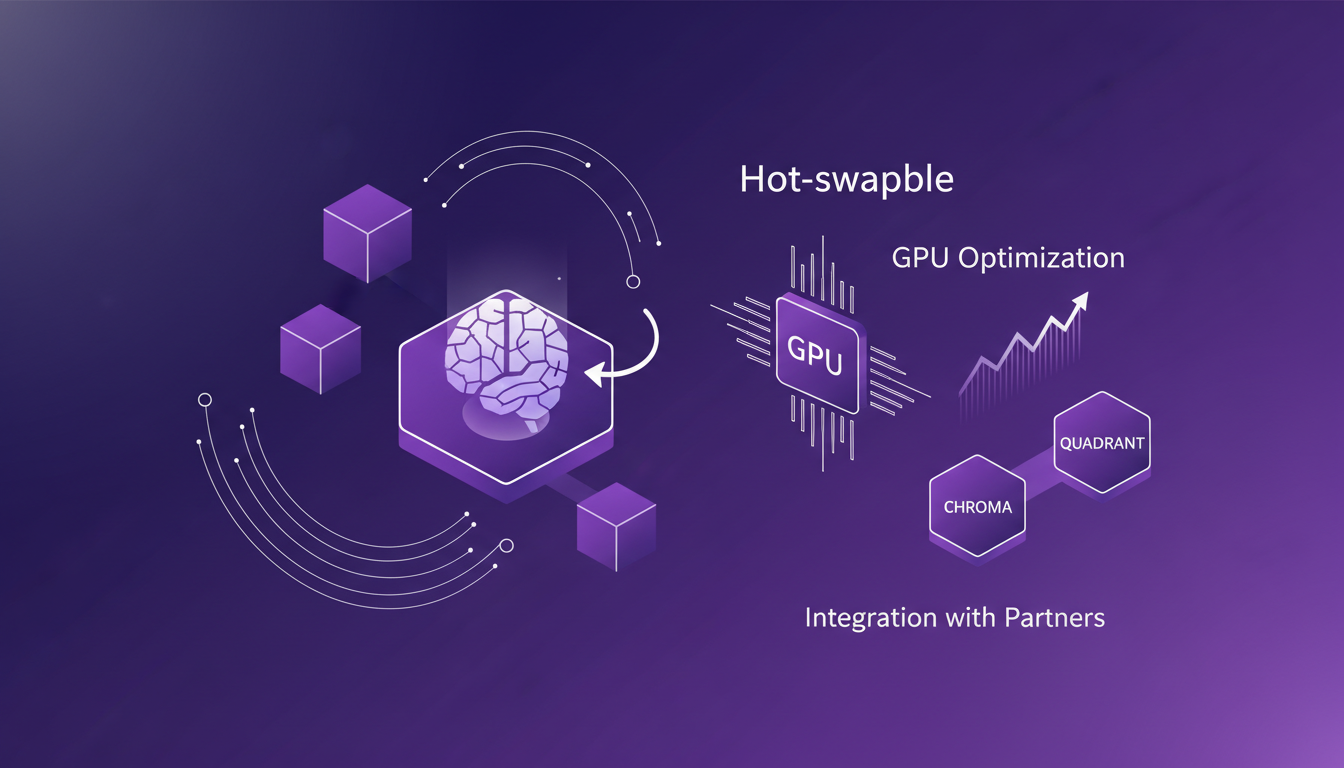
Implementing Solutions: Hot-Swapping and GPU Optimization
To improve GPU utilization, I implemented model hot-swapping: a technique that allows one model to be replaced by another without stopping the infrastructure. This enables better resource utilization and significant cost savings. I worked with partners like Chroma and Quadrant to integrate these solutions. The benefits are clear, but one must be aware of potential pitfalls, such as system overload.
- Cost savings through better GPU utilization
- Integration with partners for optimized solutions
- Beware of possible system overloads
Supporting Open-Source Models and Architectures
We also extended our support to various open-source models using methods like VLAM for training. This enabled us to handle diverse architectures and maintain essential flexibility in our model support. Managing different aspects like query-key-value fusion and positional embeddings is challenging but crucial for efficient inference.
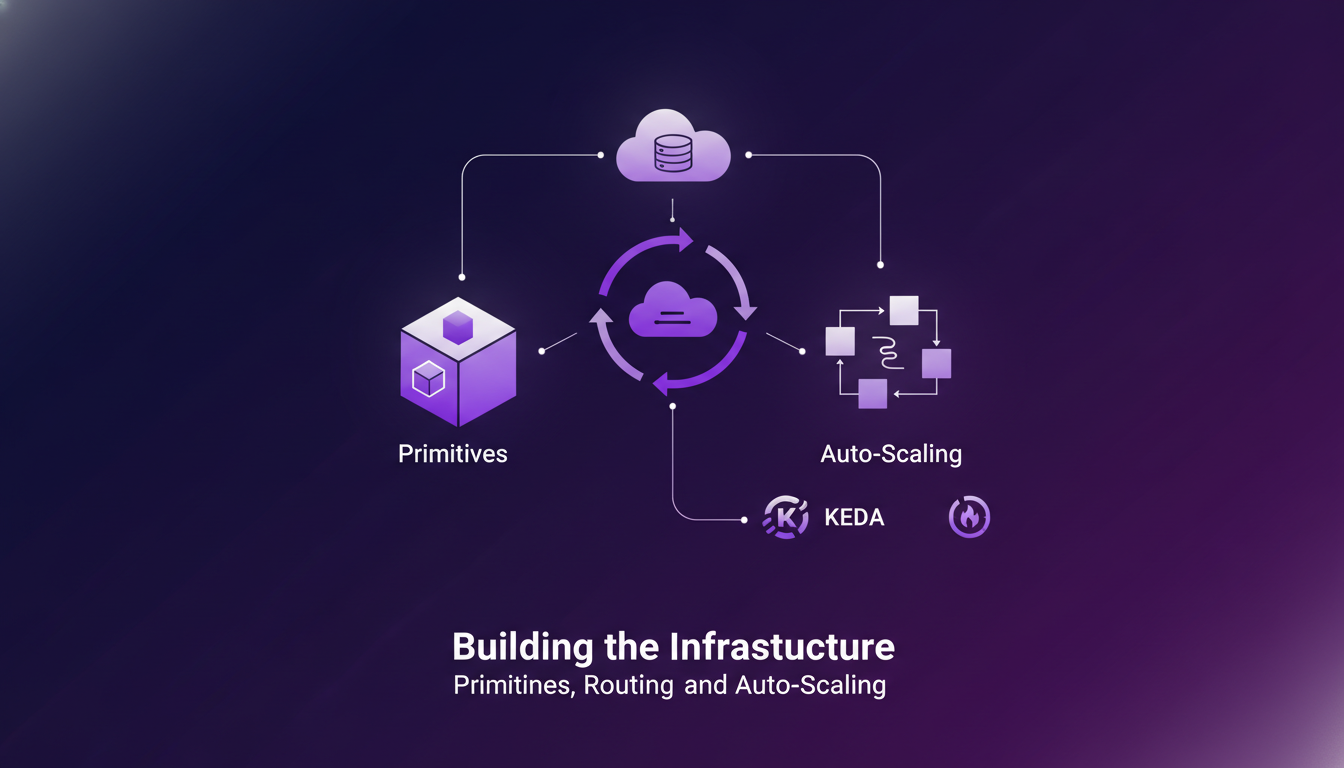
Building the Infrastructure: Primitives, Routing, and Auto-Scaling
Our infrastructure relies on primitives such as encode, score, and extract, which are vital for model management. We also integrated auto-scaling solutions with KEDA and Prometheus, allowing us to optimize workload and resource utilization. The launch of the Superlinked inference engine was a key moment, and the lessons learned are invaluable.
In summary, building this infrastructure has been a challenging journey, but each hurdle strengthened our ability to provide robust and efficient solutions for small model inference. Practical experience and mistakes allowed me to refine our approach, and I'm confident that we've filled a critical gap in the market.
I've built an infrastructure that bridges the gap in small model inference, optimizing efficiency and effectively supporting open-source models. Here are the key takeaways from this journey:
- With the right tools and strategies, we can overcome challenges in AI model inference.
- Small model inference is crucial for AI search and document processing.
- There's a real market gap for open-source model inference solutions.
- Efficient GPU utilization through model hot-swapping is a game changer.
Looking forward, I believe this approach will transform how we integrate and leverage AI models in daily operations. But watch out, it's important to manage resources carefully to avoid GPU overload.
Ready to optimize your AI model inference? Dive into our approach and see the difference it can make in your workflows. Watch the full video "The Small Model Infrastructure Nobody Built (So We Did) — Filip Makraduli, Superlinked" for a deeper understanding: https://www.youtube.com/watch?v=qdh_x-uRs9g
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics

Gemma 4: Transforming Edge AI Deployment
I dove into deploying AI on edge devices with Gemma 4, and let me tell you, it's a game changer. But there are nuances you need to know to make it work seamlessly. Gemma 4 brings new capabilities for processing data locally, reducing latency and bandwidth usage. I set up the Light RT deployment framework, and the performance boost with NPU acceleration is impressive. But don't get too excited just yet — cross-platform integration requires some tweaks. Community support and open-source contributions are key assets. Want to maximize these benefits? I'm sharing what I've learned from the field.
Ralph Loops: Building Simple, Effective AI
I remember the first time I built a Ralph Loop. It was like finding a missing puzzle piece in AI-driven development. Not just theory, but a real workflow that changed how I orchestrate tasks. These loops streamline automation using AI models like GPT 5.8, offering a practical, no-nonsense approach. Imagine orchestrating tasks seamlessly while addressing the challenges and benefits of using AI in software development. In this article, I'll take you through Ralph Loops, their practical applications, and how they can truly transform your workflow. Let's dive into the limits, security and ethical considerations, and scaling these processes in team environments. Yes, the future of AI in automating complex workflows is already here. Ready to dive in?
Edge AI: Benefits and Implementing Tiny LLMs
I've spent over a decade diving into Edge AI, and let me tell you, it's a game changer. Running AI models directly on edge devices isn't just a tech trend—it's a practical solution to real-world challenges. With the launch of Gemma 4 and advances in Tiny LLMs, we're witnessing a shift towards more efficient and reliable AI solutions. When it comes to deployment and cost, Edge AI is redefining the landscape with performance gains, privacy enhancements, and offline use. Yet, the true potential lies in the skill architecture and customization of the models. In this talk, we delve into the technical infrastructure needed to run AI on edge devices, deployment and licensing changes, and how Tiny LLMs can transform our current approaches.
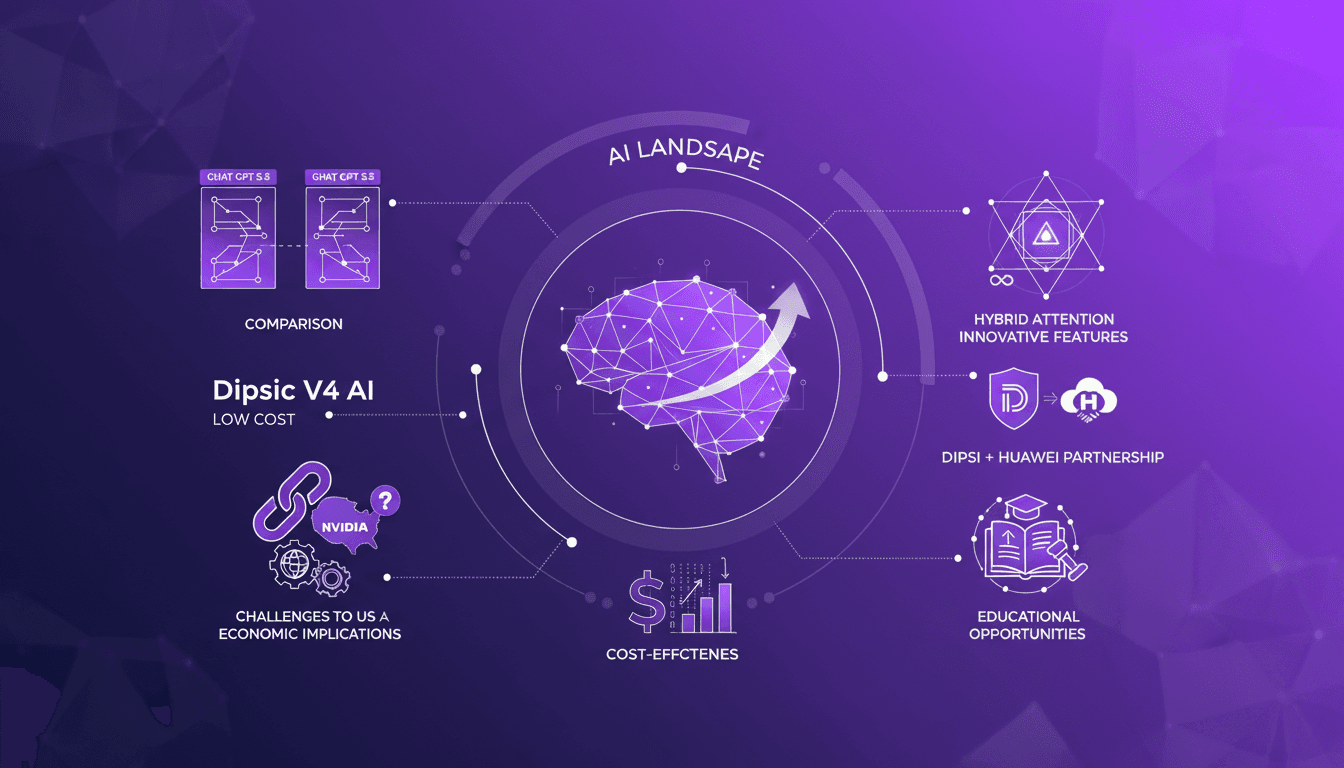
Dipsic V4: AI Revolution, Challenges OpenAI
I've been in the AI trenches for years, watching models evolve. But when I first got my hands on Dipsic V4, I knew we were onto something game-changing. With 1600 billion parameters, this model isn't just another tool in the landscape; it’s a potential disruptor in a space dominated by giants like OpenAI's GPT 5.5. Let me show you why this model is causing such a stir and how it’s rewriting the rules. We’ll dive into its innovative features, aggressive pricing strategy, and what it means for players like Nvidia and OpenAI. Watch out, this could be a game changer.
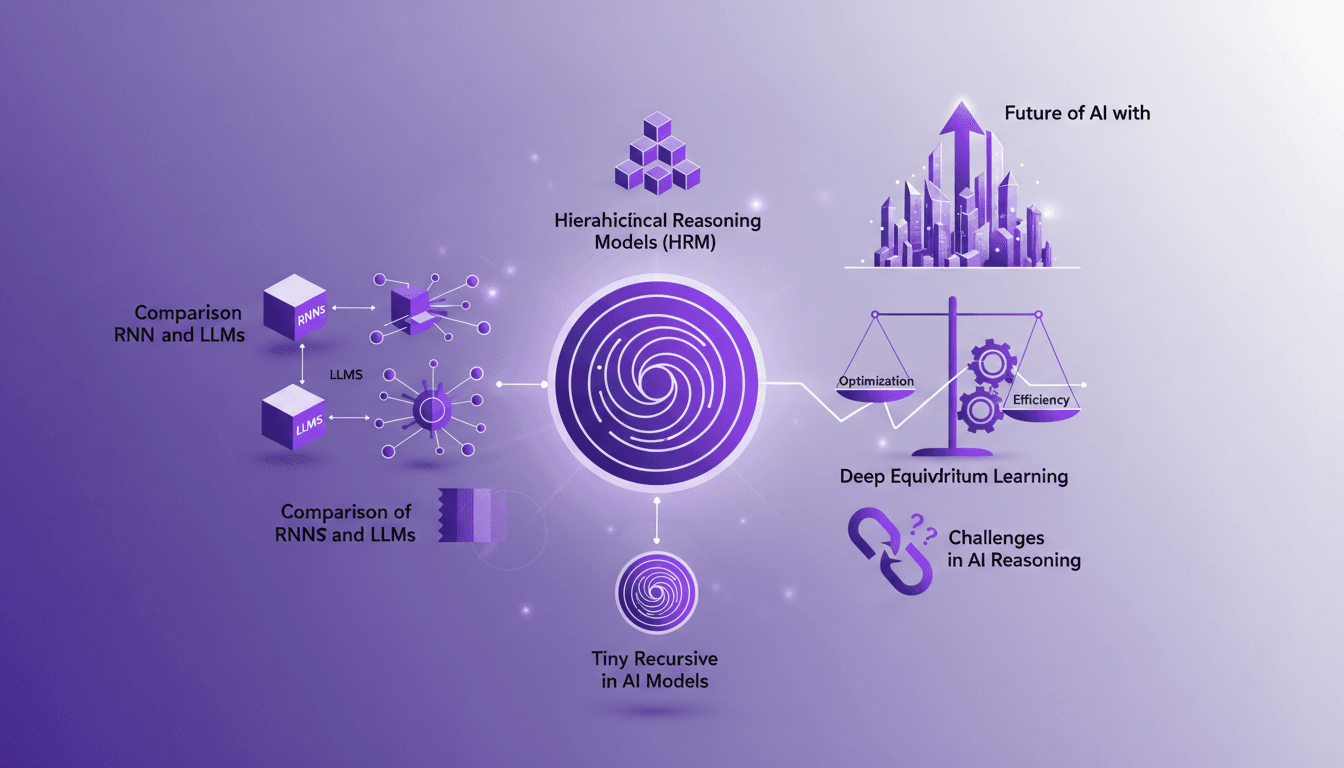
Recursion in AI: Transforming Models
I've spent countless hours tweaking AI models, and let me tell you, recursion is the game changer we've been waiting for. Forget the race for more parameters; now it's about intelligence. While traditional models hit scaling walls, recursion offers a fresh perspective. We're diving into how it could redefine AI efficiency and capability. We'll discuss hierarchical reasoning models, tiny recursive models, deep equilibrium learning, and the challenges of optimization. If you've ever been frustrated by scalability limits, you're going to love this new paradigm.