Gemma 4: Open Models and Accessibility
I dove into Gemma 4, the latest gem from Google DeepMind's open models, and it's like stepping into a new realm of possibilities. With its 26B and 31B models, we're talking about performance that's potentially a game changer (especially with its Apache 2.0 licensing making all this super accessible). Let me walk you through how I leveraged its architecture and why it matters for us builders. We'll discuss Oure architecture, multimodal capabilities, memory optimization with PLE, and even its audio processing prowess. Don't miss how these models can be deployed and made accessible for everyone.
I dove into Gemma 4, the latest open model from Google DeepMind, and it's like stepping into a new realm of possibilities. Picture a 26 billion parameter model ranking in the top six of all open-source models on the LM arena. Or go for the 31B behemoth with its cloud-hosted options – this thing is serious. But what really hooked me is its Apache 2.0 licensing, making these models incredibly accessible for developers like us. The Oure architecture allows for expert selection, and its multimodal capabilities handle variable resolutions like a breeze. Let's not forget the memory optimization with Per Layer Embedding (PLE), which is a must to avoid diving into the depths of resource consumption. And to top it all, there are audio processing and translation capabilities that left me impressed. I'll show you how to leverage these technologies for our daily projects without getting lost in unnecessary details.
Understanding Gemma 4's Architecture
As a practitioner, let me dive into the architecture of Gemma 4, which has been the talk of the town. We have two main models: 26B and 31B. To begin with, the 26B model ranks among the top six of all open-source models. That's a fact. But what really caught my attention is how the 31B model offers cloud-hosted options for handling larger models. This is where I noticed a real difference in performance. I found the Mixture of Experts model crucial for optimizing performance, especially when we're talking about the 3.9 billion active parameters needed for the 26B. It might sound huge, but that's where the magic lies: activating only what you need.
This architecture is a game changer in terms of cost reduction, especially when compared to older models. But beware, this flexibility comes at a price: you need to manage the active parameters well to avoid skyrocketing computation costs.
"The 26B model uses 3.8 billion active parameters during inference, providing performance close to the 31B dense model at significantly lower inference cost."
Developer Accessibility with Apache 2.0
Moving on to another crucial topic: developer accessibility through the Apache 2.0 license. I must say, this license has really made customizing and deploying models a breeze. Open-source is fertile ground for collaborative innovation, and I've seen it firsthand. But be mindful of the trade-offs: what you gain in flexibility, you sometimes lose in regular support and updates. And sometimes, it's faster to integrate an existing model than to build something from scratch.
- Apache 2.0 license for greater flexibility
- Fostered collaboration through open-source
- Caution: trade-offs in support
Multimodal Capabilities and Resolutions
Gemma 4 is also impressive in handling multiple modalities with variable resolutions. I've orchestrated multimodal tasks using Grouped Query Attention. This allows for handling different data types with flexibility I would call revolutionary. However, don't overuse the multimodal features, as they can exponentially increase complexity. Efficiency in processing really comes from understanding the workflow and precisely orchestrating tasks.
I've observed that proper management of resolutions and token budgets can truly optimize performance for different tasks. The flexibility is there, but you need to know how to handle it.
- Multimodal processing with grouped attention
- Avoid overusing multimodal features
- Optimize resolutions and token budgets
Memory Optimization with Per Layer Embedding
One of the innovations I found particularly useful is memory optimization with Per Layer Embedding (PLE). I wrapped PLE into my workflow to enhance model efficiency, and the memory savings are substantial. But watch out, there can be compatibility issues, especially in large-scale deployments. The balance between memory use and performance is key.
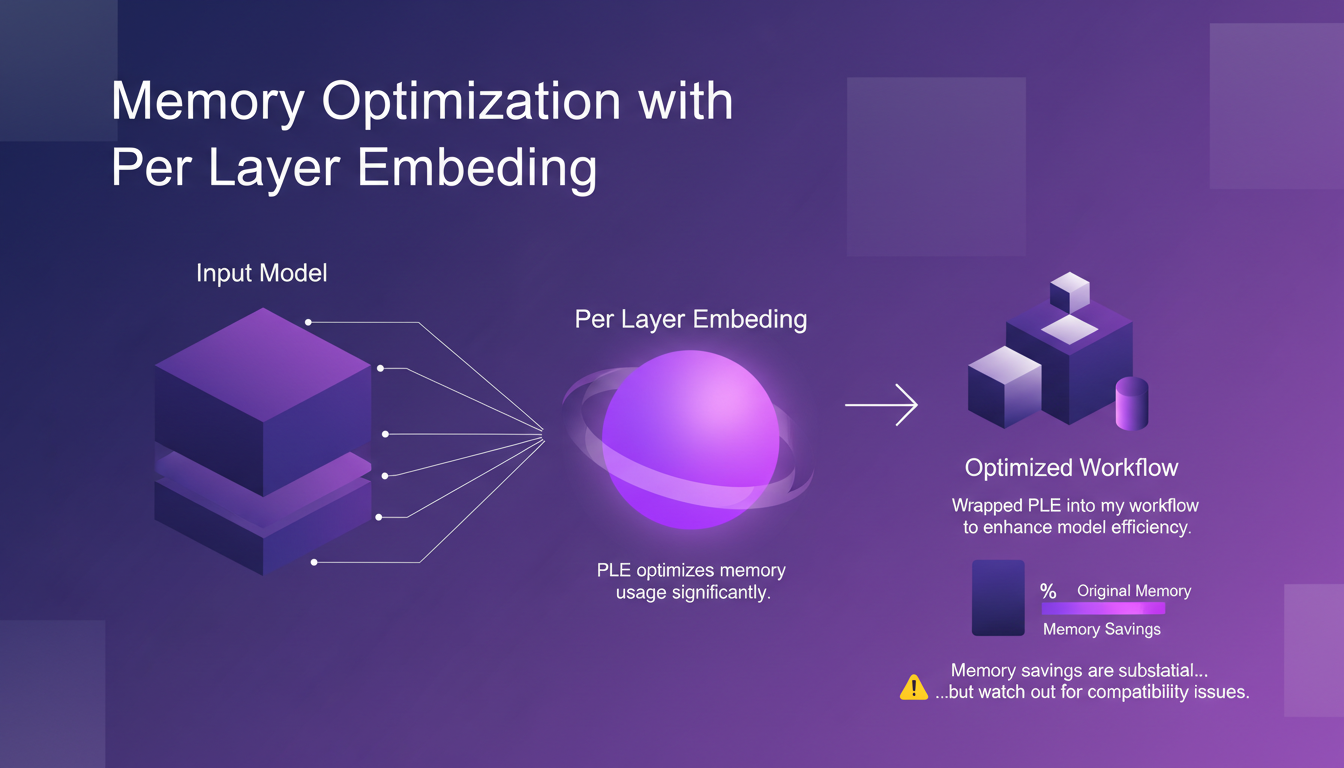
- PLE for significant memory optimization
- Beware of compatibility issues
- Importance of memory-performance balance
Audio Processing and Translation
Finally, let's talk about Gemma 4's impressive capabilities in audio processing. With a conformer of 35 million parameters, the model excels in this area. I used the MEL Spectrogram for accurate audio translation. The audio capabilities are robust, but require careful tuning to achieve optimal translation accuracy. Deployment options vary, and it's crucial to choose based on your specific needs.

- 35M conformer for audio processing
- Use of MEL Spectrogram for translation
- Varied deployment options based on needs
Gemma 4 is a true powerhouse for us builders. I've dived into it and seen how its architecture and models, especially the 26B that's ranked in the top six of all open-source models, can revolutionize our workflows. Here are my key takeaways:
- The 31B model is perfect for cloud-hosted options, ideal for large-scale projects.
- With 35 million parameters, the audio conformer is a beast for audio processing.
- Apache 2.0 licensing means unmatched developer accessibility. Next step? Dive into Gemma 4 and see how it can practically elevate your projects. Watch out for the limits in terms of accessibility and the resources needed to harness these models effectively. For a deeper dive, I recommend watching the full video 'Open Models at Google DeepMind' by Cassidy Hardin to truly grasp the essence of Gemma 4.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
Intelligent Agents: Revolutionizing Personalized Medicine
I've seen firsthand how intelligent agents are transforming personalized medicine. It's not just theory anymore; it's happening in real clinics, and it's cutting costs like never before. We're at a tipping point where technology and medicine converge. From genome sequencing to mRNA delivery, the landscape is rapidly evolving. Let me walk you through how this is reshaping healthcare. With Moore's Law in play, genome sequencing costs are plummeting, and N-of-1 genetic medicines are becoming more affordable than ever. Startups are playing a pivotal role in this ecosystem, and even the FDA is opening up to personalized procedures. As a practitioner, I'll take you behind the scenes of what's really happening.
Scaling GitHub's MCP Server: Key Lessons
I remember the first time I scaled GitHub's MCP server. It was a beast of a task, but through trial and error, I learned what works, what doesn't, and where the real value lies. In this article, I'll walk you through the journey of scaling GitHub's MCP Server, highlighting the challenges, optimizations, and security enhancements that made the difference. We'll dive into public contributions, context overload, OAuth implementation, and using Redis for stateless server setups. If you've ever juggled over 100 tools but want to cut it down by 49%, keep reading. This is field insight, not abstract theory.

Buying a Dream Car: The Real Cost
I bought my $200,000 dream car, but it wasn't the victory lap I expected. Let me share how this material obsession led me to discover a deeper purpose. We all think a purchase like this will change everything, but the real journey starts afterward. I share the story of building and selling my company, and how I found true meaning by helping others follow their dreams. This experience taught me that happiness doesn't come from material possessions, but from truly enjoying what we love to do.
Enterprise MCP Challenges: Practical Solutions
I remember the first time I had to scale MCP servers for an enterprise client. It was utter chaos — but once I found the right orchestration, everything clicked. Enterprises face unique challenges with MCPs, from scalability to security. In this article, let's break down how to tackle these challenges using gateways and other strategies. We'll also dive into security and access control, the importance of observability and credential management, and not to forget the future vision for agent technology deployment.

AI Native Services: Revolutionizing Industries
I've been knee-deep in AI for years, watching tools evolve into full-fledged AI native services. This isn't just a trend—it's a revolution. With AI models advancing at breakneck speed, we're witnessing a shift from traditional software tools to AI-native services. These aren't just buzzwords—real companies are emerging that leverage AI to replace entire service sectors. Industries like insurance and accounting are already feeling the impact. Let me walk you through how this unfolds and why it's a game changer. It's not just hype, it's happening.