Gemini 2.5 Pro: Performance and Comparisons
I dove into the Gemini 2.5 Pro with high expectations, and it didn't disappoint. From coding accuracy to search grounding, this model pushes boundaries. But let's not get ahead of ourselves—there are trade-offs to consider. With a score of 1443, it's the highest in the LM arena, and its near-perfect character recognition is impressive. However, excessive tool usage and a tendency to overthink can sometimes slow down the process. Here, I share my hands-on experience with this model, highlighting its strengths and potential pitfalls. Get ready to see how Gemini 2.5 Pro stacks up and where it might surprise you.

I dove into the Gemini 2.5 Pro with high hopes, and let me tell you, it delivered. This model isn't just grazing perfection in character recognition; it outright nailed it. And with a score of 1443, it's sitting at the top in the LM arena. But don't get too comfortable—there's a catch. I've noticed a bit of an overthinking issue that can eat up both time and budget. In this article, I'll walk you through my firsthand experience: performance, comparisons, coding capabilities, and where it might trip you up. Basically, I’m giving you a heads-up on where you might get burned like I did at first. It's definitely worth a look, especially if you're wondering whether this model is the right fit for your projects.
Benchmark Performance: Breaking Records
I've been amazed by Gemini 2.5 Pro, the first model to breach the 1443 mark in benchmarks, setting a new standard. It outperformed models like Claw 3.5 and 3.7 with an impressive 18.8% score according to Scale AI. But watch out, expectations can be overhyped—real-world performance can vary.
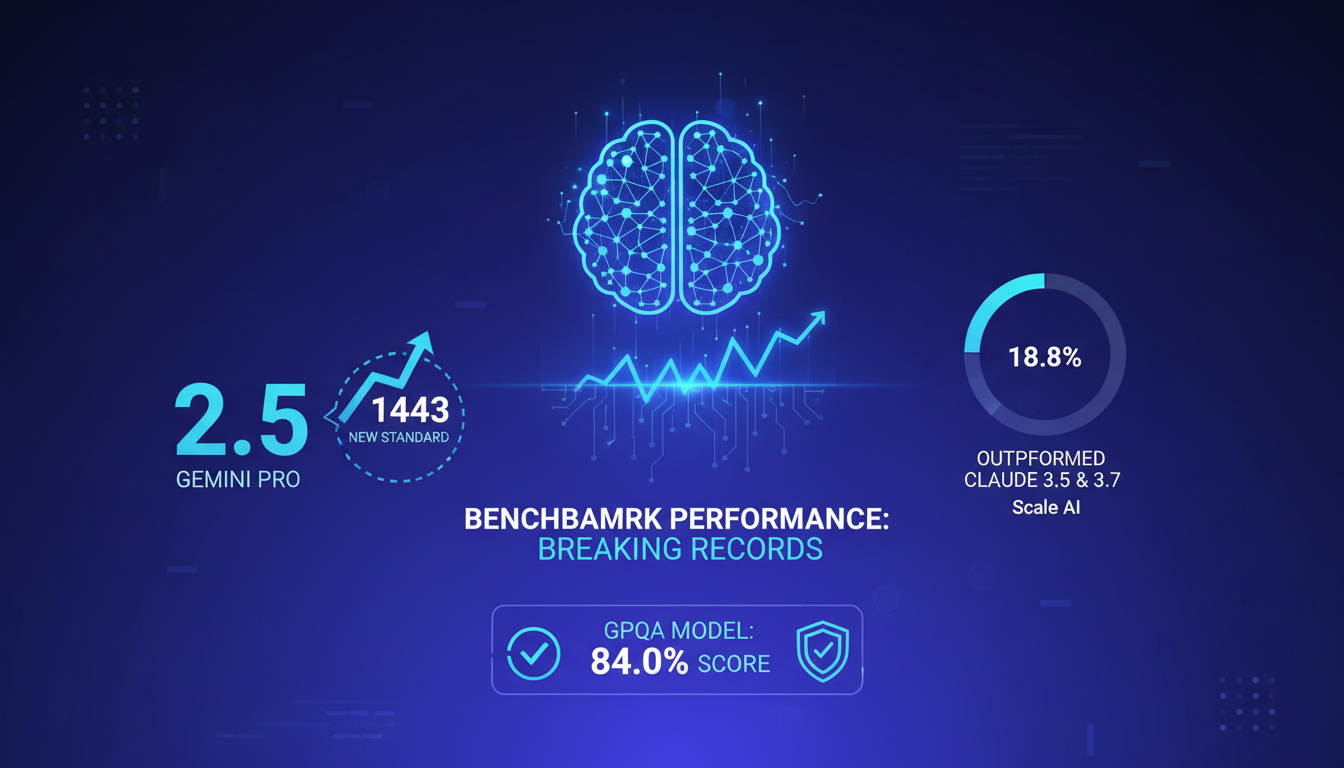
The GPQA model also scored 84.0%, showcasing its effectiveness. However, keep a critical eye on these numbers. In my tests, results can fluctuate depending on the task and context.
- 1443: First model to achieve this score, positioning Gemini 2.5 Pro at the top.
- 18.8%: Higher score than Claw 3.5 and 3.7 according to Scale AI.
- 84.0%: GPQA score, proving its effectiveness.
Search Grounding and Tool Usage
One of Gemini 2.5 Pro's strengths is its excellence in search grounding, significantly enhancing context relevance. When I integrated it into my existing toolset, the transition was smooth. The model offers contextual relevance I hadn't seen before.
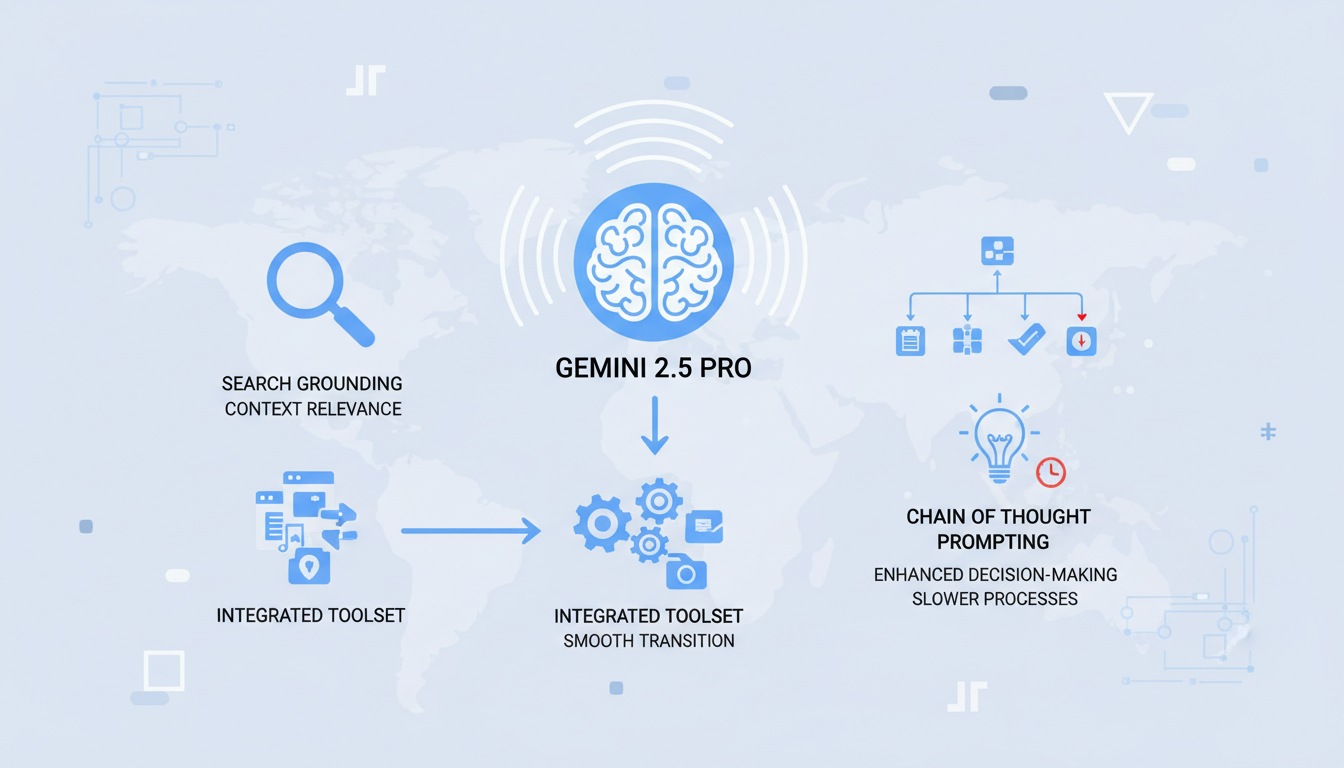
Chain of Thought Prompting is another asset, enhancing decision-making. But beware, it can slow processes if over-relied upon. Finding balance is crucial to avoid inefficiencies.
- Search grounding: Enhances response relevance.
- Smooth transition: Easy integration with existing tools.
- Chain of Thought: Useful but can slow down if overused.
Coding and Character Recognition: A Deep Dive
In coding benchmarks, Gemini 2.5 Pro scored 74%, solid for programming tasks. I've tested this myself, and the model handles complex code well. Character recognition is nearly flawless with only one noted mistake.

The model's multimodal understanding boosts its versatility. However, don't overuse it for simple tasks—a lighter model is sometimes faster and equally effective.
- 74%: Solid in coding benchmarks.
- Nearly flawless: Only one character recognition mistake.
- Versatility: Multimodal understanding.
Deep Thinking and Simulation Capabilities
Gemini 2.5 Pro's deep thinking and simulation capabilities are impressive. I've orchestrated several simulation tasks, and the model solved complex problems effortlessly. However, it tends to overthink, and time management is essential.
Reinforcement Learning enhances its adaptability but demands more resources. For straightforward problems, simpler models might be more efficient.
- Complex problems: Solved with ease.
- Reinforcement Learning: Enhances adaptability.
- Overthinking: Can slow down simple tasks.
Cost Implications and Future Potential
The high performance of Gemini 2.5 Pro comes with higher costs—budget accordingly. Its experimental nature means potential for future improvements. I constantly evaluate the cost versus benefit—sometimes a less powerful model is more cost-effective.
Stay tuned for updates—Gemini 2.5 Pro is continually evolving and could redefine standards in the future.
- High cost: Budget accordingly.
- Experimental nature: Potential for improvement.
- Constant evaluation: Watch for updates.
Gemini 2.5 Pro is a real powerhouse in the AI scene. First off, it made only one mistake in a character recognition task, showcasing its high accuracy. Then it breached the 1443 mark, putting it at the top of the LM's arena. Finally, it outperformed other models with an 18.8% score in a Scale AI benchmark test. But watch out, its high cost and tendency to overthink can be traps. Don’t jump in blindly, evaluate your specific needs. If you're ready to push the boundaries of AI, Gemini 2.5 Pro might be the tool for you. But remember, sometimes less is more. Check out the video "Gemini 2.5 Pro is here!" to deepen your understanding. Your next big AI breakthrough could be just a click away.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
StepFun AI Models: Efficiency and Future Impact
I dove into StepFun AI's ecosystem, curious about its text-to-video capabilities. Navigating through its models and performance metrics, I uncovered a bold contender from China. With 30 billion parameters and the ability to generate up to 200 frames per second, StepFun AI promises to shake up the AI landscape. But watch out, the Step video t2v model demands 80 GB of GPU memory. Compared to other models, there are trade-offs to consider, yet its potential is undeniable. Let's explore what makes StepFun AI tick and how it might redefine the industry.

Exploring Deep Seek R1: Reasoning AI in Action
I dove into Deep Seek's R1 light preview model, eager to see how it stacks up against OpenAI's 01 preview. Spoiler: there are some surprises! I didn’t expect the R1 to excel in math problem-solving and coding as much as it did. With its reasoning capabilities, it’s setting a new standard for AI expectations. But watch out, there are limits. For instance, Base 64 decoding revealed some unexpected challenges with model hallucinations. Then there's the test time compute scaling, which can quickly become a resource drain. Still, if you're looking to explore the potential of reasoning models, the R1 is a must-try. Don't underestimate it, but be aware of its constraints.
Deep Agents with LangChain: Introduction
I've spent countless hours in the trenches of AI development, wrestling with deep agents. When I first encountered LangChain, it felt like stumbling upon a goldmine. Imagine launching two sub-agents in parallel to supercharge efficiency. Let me walk you through how I optimize and debug these complex systems, leveraging tools like Langmith Fetch and Paulie. Deep agents are the backbone of advanced AI systems, yet they come with their own set of challenges. From evaluation to debugging, each step demands precision and the right set of tools.
Optimizing AI Agent Memory: Advanced Techniques
I've been in the trenches with AI agents, wrestling with memory patterns that can literally make or break your setup. First, let's dive into what Agent Memory Patterns really mean and why they're crucial. In advanced AI systems, managing memory and context is not just about storing data—it's about optimizing how that data is used. This article explores the techniques and challenges in context management, drawing from real-world applications. We delve into the differences between short-term and long-term memory, potential pitfalls, and techniques for efficient context management. You'll see, two members of our solution architecture team have really dug into this, and their insights could be a game changer for your next project.
AI Exploration: 10 Years of Progress, Limits
Ten years ago, I dove into AI, and things were quite different. We were barely scratching the surface of what deep learning could achieve. Fast forward to today, and I'm orchestrating AI projects that seemed like science fiction back then. This decade has seen staggering advancements—from historical AI capabilities to recent breakthroughs in text prediction. But watch out, despite these incredible strides, challenges remain and technical limits persist. In this exploration, I'll take you through the experiments, trials, and errors that have paved our path, while also gazing into the future of AI.