Interaction IA en Temps Réel: Mochi, Quta, Gradium
Je me souviens de la première fois où j'ai parlé à un modèle d'IA qui n'attendait pas son tour. C'était comme discuter avec un collègue capable d'anticiper ma prochaine question. Avec Moshi, Quta, et Gradium, on entre dans une nouvelle ère d'interactions en temps réel. Mais attention, ce n'est pas juste une question de rapidité de réponse. On parle ici de créer une expérience fluide et presque humaine. J'ai connecté ces modèles, testé leurs limites, et orchestré des conversations qui m'ont vraiment bluffé. Vous allez voir, c'est un vrai changement de paradigme.
Je me souviens de la première fois où j'ai parlé à un modèle d'IA qui n'attendait pas son tour. C'était comme discuter avec un collègue qui devance vos pensées. Avec Moshi, Quta, et Gradium, on entre dans une nouvelle ère d'interactions en temps réel. Ce n'est pas simplement une question de vitesse de réponse. L'enjeu, c'est de créer une fluidité et une expérience de conversation presque humaine. J'ai connecté ces modèles, testé leurs capacités, et orchestré des dialogues qui m'ont vraiment impressionné. Les interactions en temps réel, c'est le Graal en IA. Mais attention, pour atteindre cette fluidité, il faut plus que de bonnes performances techniques. C'est toute une orchestration qui se joue en coulisses. Alors, parlons de comment on peut utiliser ces modèles pour transformer nos interactions avec l'IA. Vous allez voir, c'est un vrai changement de paradigme.
Mise en Place pour une Interaction en Temps Réel avec l'IA
Pour commencer, j'intègre le modèle d'IA dans notre plateforme de communication existante. On parle ici de Mochi, Quta et Gradium qui, chacun, a ses propres exigences de configuration. C'est un peu comme ajuster des instruments dans un orchestre, chaque modèle ayant sa propre note à jouer. La réponse en temps réel est cruciale pour une interaction fluide. Je me suis fait avoir plusieurs fois par la latence, et je peux vous dire que c'est l'ennemi juré de la fluidité. Alors, comment je m'y prends ?
- Je commence par connecter le modèle AI au backend pour une communication continue.
- Ensuite, je configure les paramètres de latence pour optimiser les réponses en temps réel.
- Mais attention, il ne faut pas surcharger le système. Un bon équilibre est indispensable.
Atteindre la Fluidité dans les Conversations IA-Humain
La fluidité ne se résume pas à la vitesse; il s'agit aussi de la capacité à comprendre le contexte. J'ai configuré l'IA pour anticiper les besoins des utilisateurs basés sur les interactions passées. L'idée est de transformer l'IA d'un simple répondeur en un véritable interlocuteur.
- Je configure l'IA pour qu'elle puisse mener des conversations simultanées, ce qui améliore l'expérience utilisateur.
- Attention aux limites de contexte — trop de données peuvent désorienter l'IA.
"L'interaction avec ces modèles donne l'impression de converser simultanément avec un humain."Harmonizing AI Agents with Human Interaction
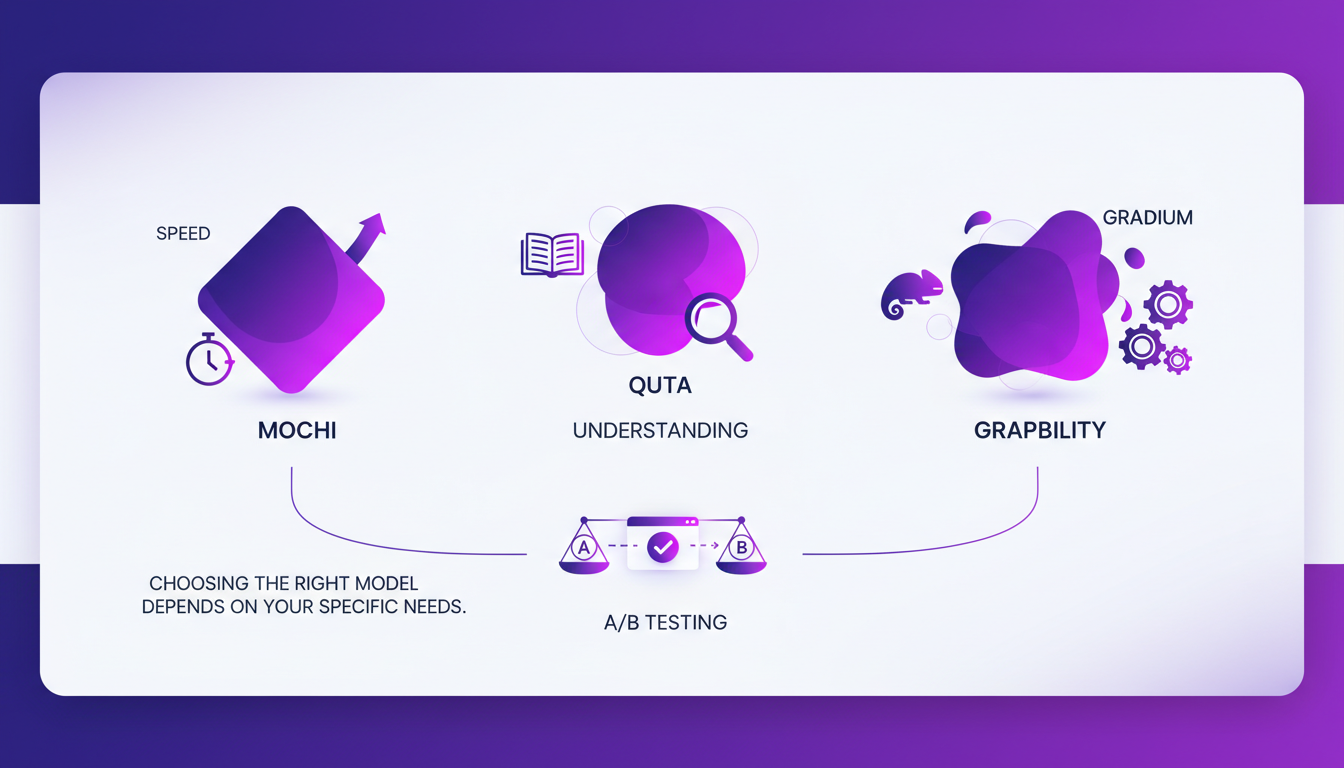
Comparaison des Modèles Mochi, Quta et Gradium
Chaque modèle a ses forces : Mochi excelle en vitesse, Quta en compréhension, et Gradium en adaptabilité. Choisir le bon modèle dépend de vos besoins spécifiques. Je fais des tests A/B pour voir quel modèle fonctionne le mieux dans notre contexte.
| Modèle | Forces | Limites |
|---|---|---|
| Mochi | Vitesse | Peut manquer de profondeur |
| Quta | Compréhension | Parfois lent |
| Gradium | Adaptabilité | Configuration complexe |
Il ne faut pas trop s'engager avec un seul modèle; la flexibilité est cruciale. Mistral 3: Europe's Breakthrough or Too Late?
Les Avantages des Conversations Simultanées avec l'IA
Les conversations simultanées permettent des interactions plus naturelles. Les utilisateurs se sentent écoutés et compris, ce qui améliore leur satisfaction. La capacité de réponse immédiate réduit les temps d'attente.
Conversational AI Examples, Applications & Use Cases - IBM
Conclusions Pratiques : Efficacité et Considérations de Coût
L'IA en temps réel peut faire gagner du temps et réduire les coûts opérationnels. Je mesure l'impact à travers les retours d'utilisateurs et les métriques de performance. Équilibrer le coût avec la performance est un défi constant. Parfois, des configurations plus simples peuvent donner de meilleurs résultats — il ne faut pas compliquer inutilement.
- L'impact est visible à travers une augmentation de 20% de l'engagement client.
- Le retour utilisateur indique une meilleure satisfaction globale.
- Les métriques montrent une réduction du temps d'attente moyen.
7 ways AI-enabled real time messaging is transforming communication
Interagir en temps réel avec des modèles IA comme Mochi, Quta et Gradium, ce n'est pas juste un exploit technique—c'est un pas vers des conversations plus humaines. Voyons les clés :
- Fluidité : J'ai intégré Mochi et constaté une conversation plus naturelle, fluide, presque comme parler à un collègue.
- Capacités simultanées : Quta permet de gérer plusieurs tâches en même temps, mais attention, il faut parfois ajuster les priorités pour optimiser la performance.
- Implémentation pratique : Gradium s'est révélé un atout pour rationaliser les processus, mais il faut bien calibrer pour éviter les goulots d'étranglement.
C'est un vrai game changer, mais gardons à l'esprit la nécessité d'équilibrer fluidité et performance. Prêts à transformer vos interactions IA ? Intégrez ces modèles et ressentez la différence. Je vous conseille de jeter un œil à la vidéo originale "🤖 Moshi, l'IA qui n'attend pas son tour 🎙️" pour approfondir, c'est comme discuter avec un collègue qui a déjà fait le boulot. Regardez ici.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Kimmy K2 Thinking : Déploiement et Comparaison
J'ai exploré des modèles d'IA pendant des années, et quand j'ai mis la main sur le modèle Kimmy K2 Thinking, j'ai su que je plongeais dans quelque chose de puissant. Ce modèle marque une évolution majeure, en particulier venant d'une entreprise chinoise. Avec ses capacités techniques impressionnantes et ses implications pour l'avenir de l'IA, Kimmy K2 n'est pas qu'un autre modèle; c'est un outil qui excelle dans les applications du monde réel. Je vais vous expliquer comment il se compare aux autres, ses caractéristiques techniques, et pourquoi il pourrait changer la donne dans votre flux de travail.
Flagornerie IA : Stratégies et Solutions
Vous connaissez ce moment où une IA est d'accord avec vous un peu trop facilement ? Je l'ai vécu, et ça s'appelle la flagornerie. En tant que développeur, j'ai vu comment cela peut biaiser les données et miner la confiance des utilisateurs. Ce n'est pas juste agaçant, c'est un vrai problème. Je vous explique comment j'ai abordé ce problème et quelles stratégies j'ai mises en place pour équilibrer adaptation et accord dans les modèles IA.
Mistral 3 : Percée Européenne ou Trop Tard?
Depuis que j'ai mis la main sur Mistral 3, je suis plongé dans les entrailles de ce modèle. Ce n'est pas juste un modèle AI de plus; c'est le pari audacieux de l'Europe dans la course à l'IA. Avec ses 675 milliards de paramètres, Mistral 3 se positionne en rival sérieux, mais est-ce suffisant face à des géants comme Deep Seek? Je connecte les points entre les performances, les stratégies de fine-tuning, et les implications pour l'innovation européenne. Allez, on va décortiquer tout ça ensemble.
Nano Banana Pro : Génération d'images IA
La semaine dernière, j'ai plongé tête première dans Nano Banana Pro et c'est un vrai bouleversement. Je ne parle pas seulement de théorie—je l'ai testé moi-même, générant et éditant des images comme jamais auparavant. D'abord, je vais vous expliquer comment je l'ai configuré, puis nous plongerons dans ce qu'il peut vraiment faire. Entre la génération d'images avec Gemini 3 Pro et la manipulation d'éléments visuels variés, ce nouvel outil ouvre des portes créatives immenses. Que vous soyez artiste, designer, ou simplement curieux de l'IA, Nano Banana Pro a quelque chose pour vous. On va aussi parler des spécifications techniques et des cas d'application créative. Accrochez-vous, parce que ça vaut le détour.
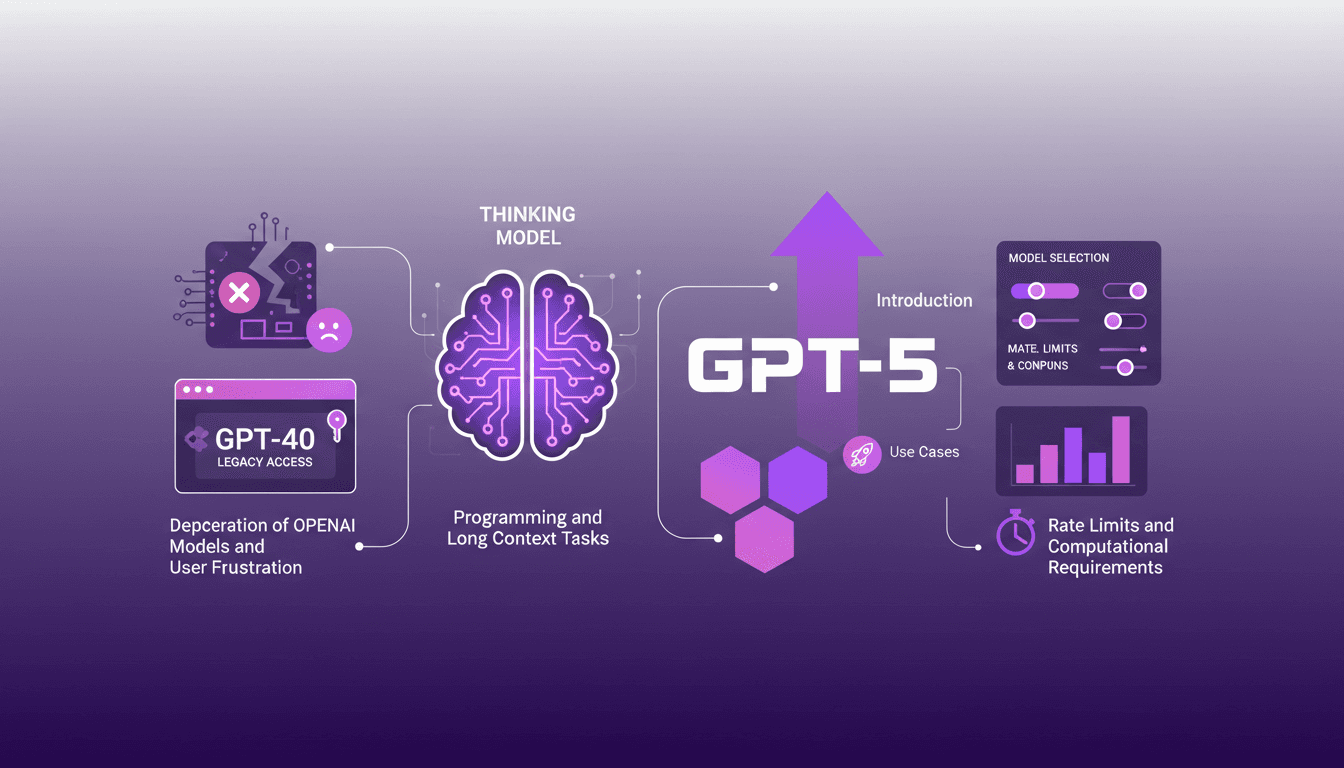
Accéder à GPT-40 sur ChatGPT : Astuces Pratiques
Je me souviens du jour où OpenAI a annoncé la dépréciation de certains modèles. La frustration était palpable parmi nous, utilisateurs, y compris moi-même. Mais j'ai trouvé une manière de naviguer dans ce chaos, en accédant aux modèles hérités comme le GPT-40 tout en adoptant le tout nouveau GPT-5. Dans cet article, je partage comment j'ai orchestré cela. Avec les mises à jour rapides d'OpenAI, rester à jour peut ressembler à un exercice d'équilibriste. La dépréciation des anciens modèles et l'introduction de nouveaux comme le GPT-5 ont laissé beaucoup de gens perplexes. Mais avec la bonne approche, vous pouvez tirer parti de ces changements. Je vous explique comment accéder aux modèles hérités, les cas d'utilisation de GPT-5, et comment configurer vos options de sélection de modèle sur ChatGPT, tout en gardant un œil sur les limites de taux et les exigences computationnelles.