Optimiser les circuits d'inférence pour IA
J'ai passé des heures à orchestrer des workflows d'agents IA, et je vous le dis, le bon processeur fait toute la différence. Mais quand je vois nos GPU actuels plafonner à 30-40% d'utilisation, c'est clair qu'on a besoin de silicium conçu sur mesure. Dans cet article, on plonge dans les défis et innovations du design de puces IA, avec un focus sur des solutions pratiques pour nous, les constructeurs. On parle de l'acquisition de Groq par Nvidia pour 20 milliards, du rôle des compilateurs, et des promesses du TPU v7 de Google. Bref, tout ce qu'il faut pour optimiser nos boucles d'agents IA.

J'ai passé des heures interminables à orchestrer des workflows d'agents IA, et croyez-moi, le bon processeur change vraiment la donne. Mais voilà, nos GPU actuels ne dépassent que rarement les 30-40% d'utilisation maximale. Alors, il est clair qu'on a besoin de silicium conçu spécifiquement pour ces tâches. C'est là qu'on entre dans les détails : l'acquisition de Groq par Nvidia pour 20 milliards, qui montre bien l'intérêt pour des solutions sur mesure, ou encore le TPU v7 de Google, un bijou taillé pour l'inférence. Mais attention, c'est pas qu'une question de matériel. Les compilateurs jouent un rôle énorme dans la performance des puces IA. En gros, si vous voulez optimiser vos boucles d'agents IA, il faut comprendre les défis actuels et savoir où investir. Ce que je vous propose ici, c'est une plongée dans le monde du silicium sur mesure pour nos agents, avec des solutions concrètes pour nous, les bâtisseurs du quotidien.
Les Limitations des GPU Actuels dans les Flux de Travail des Agents
Dans le monde des workflows des agents, les GPU traditionnels sont comme des piétons sur une autoroute. Je ne plaisante pas. Ils peinent à atteindre seulement 30 à 40 % de leur utilisation maximale, ce qui est ridicule quand on sait le potentiel de ces bêtes de course. Le problème ? C'est que ces workflows nécessitent des changements de contexte rapides (et le GPU moyen n'aime pas ça). Les agents ne suivent pas le modèle standard d'inférence - c'est plus un ballet complexe de changements de tâches qui laisse le GPU sur le carreau.
Alors, pourquoi les GPU ne sont-ils pas adaptés ? Pour une raison simple : ils sont conçus pour des tâches massives et continues, pas pour ces petits sauts de puce. Quand je pilote ces agents, je vois bien que les temps de traitement s'allongent et les coûts grimpent. C'est là que je me dis qu'il est temps de repenser notre approche.
- Utilisation : 30 à 40 % de l'utilisation de pointe.
- Changement de contexte : Faible capacité à gérer les commutations rapides.
- Coûts : Augmentation des coûts liés à l'inefficacité.
Pourquoi le Silicon Dédié Change la Donne
Le silicon dédié, c'est comme donner un GPS à un randonneur perdu. Avec l'acquisition par Nvidia de Groq pour 20 milliards, il est clair que l'industrie prend cette direction à cœur. Ces puces sont conçues spécialement pour ces boucles d'agents, et là, je dis bravo ! Pourquoi ? Parce qu'elles comprennent enfin ce que j'attends : une gestion efficace de ces boucles complexes.
Ces puces réduisent les coûts en optimisant l'utilisation et en améliorant les performances. Je l'ai vu de mes propres yeux. Quand j'ai intégré ces solutions dédiées, la différence était notable : moins de latence, plus de fluidité. Et franchement, c'est un soulagement.
- Acquisition : Nvidia a investi 20 milliards dans Groq.
- Optimisation : Meilleure gestion des boucles d'agents.
- Coût : Réduction des coûts grâce à une utilisation améliorée.
Le Rôle des Compilateurs dans la Performance des Puces
Je me suis fait avoir plusieurs fois avant de vraiment comprendre l'importance des compilateurs. Ces outils sont cruciaux pour tirer le meilleur de votre matériel. Ils optimisent l'exécution du code, permettant une utilisation plus efficace du hardware. Si vous négligez cet aspect, vous vous privez d'un boost de performance conséquent.
Pour maximiser vos résultats, il est essentiel de comprendre comment ces compilateurs fonctionnent. Je recommande de se plonger dans leur fonctionnement et de les intégrer dès que possible dans votre workflow. Mon conseil ? Ne sous-estimez pas leur pouvoir.
- Optimisation : Les compilateurs optimisent l'exécution du code.
- Performance : Amélioration significative des performances matérielles.
- Conseil : Investir du temps pour comprendre leur fonctionnement.
Explorer le TPU v7 de Google pour l'Inférence
Google a frappé fort avec son TPU v7, et honnêtement, je suis impressionné. Conçu spécifiquement pour l'inférence, il gère les changements de contexte à une vitesse folle. Et c'est là que le décodage spéculatif entre en jeu, un concept qui, bien utilisé, peut transformer votre manière de gérer les workflows des agents.
En intégrant ces TPU dans mes projets, le gain en rapidité et la réduction de la latence sont indéniables. C'est, littéralement, une nouvelle dimension qui s'ouvre à nous.
- Architecture : Optimisée pour des changements de contexte rapides.
- Décodage spéculatif : Améliore la gestion des workflows.
- Impact réel : Traitement plus rapide et latence réduite.
Combler les Lacunes de Conception et Innovations Futures
Je ne vais pas vous mentir, il y a encore des lacunes à combler dans la conception des puces AI pour les boucles d'agents. Mais l'innovation ne s'arrête jamais, et les solutions émergent. L'équilibre entre coût, performance et efficacité reste un défi constant, mais les stratégies pour y parvenir se perfectionnent.
Pour rester en tête, il faut piloter différemment. Je recommande d'explorer les nouvelles technologies et de s'adapter rapidement. C'est le seul moyen de rester compétitif dans ce paysage en constante évolution.
- Lacunes : Conception actuelle encore imparfaite.
- Innovations : Des solutions émergent pour combler ces lacunes.
- Stratégie : Adopter et intégrer les nouvelles technologies rapidement.
Pour en savoir plus sur l'avenir des semi-conducteurs, consultez notre article sur Supply Chain 2.0 : Revolutionizing Semiconductors.
Dans le monde des flux de travail des agents IA, choisir le bon processeur est un vrai levier de performance. Avec des solutions comme le TPU v7 de Google, on voit clairement que le silicium conçu sur mesure fait la différence. Mais attention, les GPU actuels n'atteignent que 30 à 40 % de leur capacité maximale pour ces tâches, ce qui peut être un frein. Nvidia a mis la main sur Groq pour 20 milliards, ce qui montre l'importance de ces avancées.
- Premièrement, pour optimiser vos workflows, commencez par évaluer l'utilisation actuelle de vos puces.
- Deuxièmement, explorez des solutions conçues spécialement pour vos besoins spécifiques.
- En troisième, restez à l'affût des nouvelles technologies comme le TPU v7 pour améliorer l'inférence.
À l'avenir, je suis convaincu que ces technologies vont redéfinir nos méthodes de travail. Prévoyez d'adapter vos infrastructures pour profiter de ces innovations.
Prêt à optimiser vos flux de travail ? Je vous encourage à revoir l'utilisation de vos puces actuelles et à envisager des solutions sur mesure. Pour une compréhension plus approfondie, regardez la vidéo originale : lien YouTube.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires

Chaîne d'approvisionnement 2.0 : Révolutionner les semi-conducteurs
J'ai passé des années plongé dans les chaînes d'approvisionnement des semi-conducteurs, et croyez-moi, ce n'est pas qu'une question de fabriquer des puces; c'est une véritable symphonie mondiale à orchestrer. On commence par les 1 400 étapes de processus, puis on navigue à travers une douzaine de pays. Mais que se passe-t-il quand une puce à 300 $ bloque une voiture à 50 000 $? C'est là que ça devient sérieux. Avec les puces AI en première ligne, chaque étape, de la fabrication à la livraison, doit être optimisée. Plongeons dans ces défis et découvrons où les opportunités se cachent.
Dipsic V4 : Révolution IA, défis OpenAI
J'ai passé des années dans les tranchées de l'IA, à observer l'évolution des modèles. Mais quand j'ai mis la main sur le Dipsic V4, j'ai su qu'on tenait quelque chose de révolutionnaire. Avec ses 1600 milliards de paramètres, ce modèle n'est pas simplement un autre outil dans le paysage; c'est un potentiel perturbateur face aux géants comme GPT 5.5 d'OpenAI. Je vais vous montrer pourquoi ce modèle fait tant de vagues et comment il redéfinit les règles du jeu. On parlera de ses caractéristiques innovantes, de sa stratégie de prix agressive, et de ce que cela signifie pour des acteurs comme Nvidia et OpenAI. Attention, ça peut changer la donne.
GPT-5.5 avec Databricks : Réduction d'erreurs
Je me suis plongé dans le monde du GPT-5.5 avec Databricks, et les améliorations ne sont pas que théoriques. Après avoir connecté cet outil à mes workflows, j'ai constaté une réduction d'erreurs de 46% par rapport au 5.4. L'optimisation des performances, notamment avec l'API Agent Supervisor, est bluffante. Avec GPT-5.5, le parsing et la qualité des tâches ont clairement passé un cap. Inutile de dire que mes agents personnalisés, grâce aux outils Databricks, ont gagné en efficacité. Mais attention, tout n'est pas parfait; il faut savoir manier ces nouveaux outils avec doigté pour éviter les pièges. Une mise à jour qui, je l'avoue, a directement impacté mes projets, et je ne compte pas m'arrêter là.
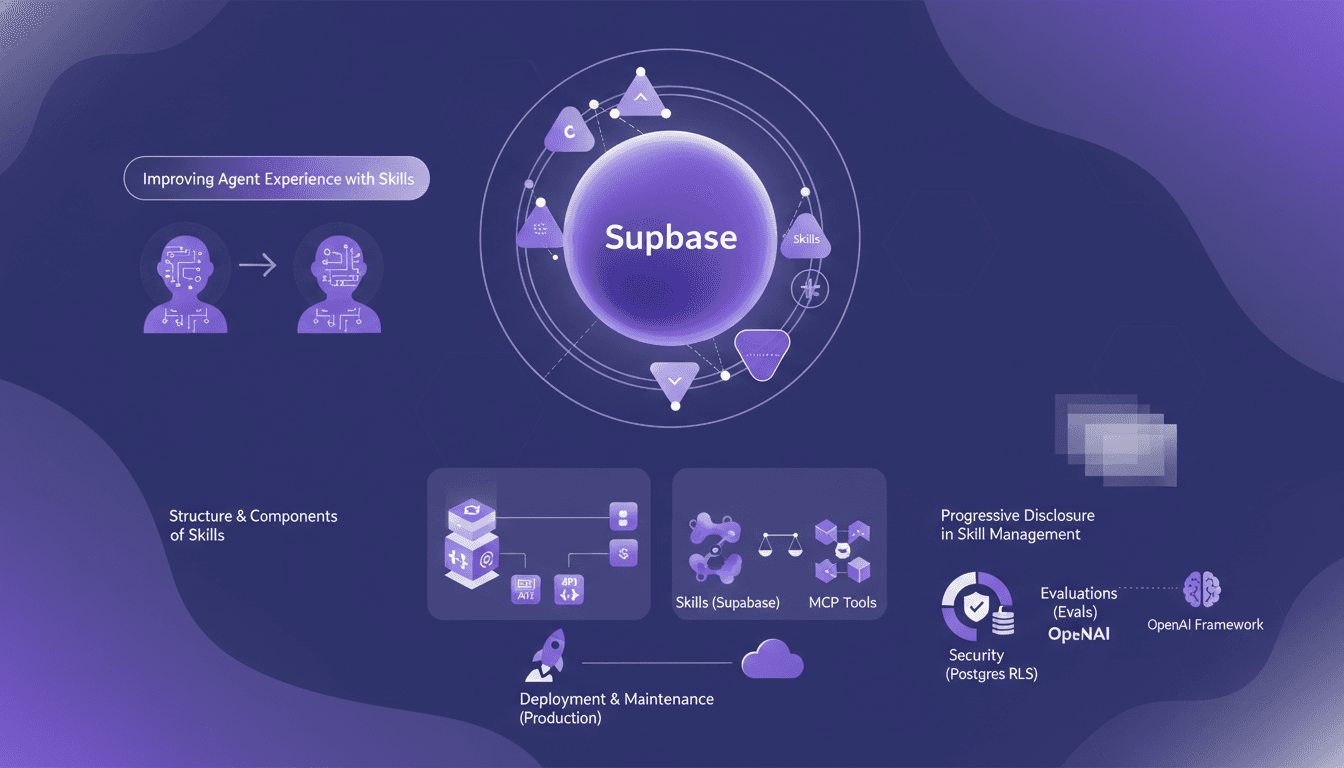
Améliorer les agents avec Supabase : notre méthode
J'ai passé deux mois les mains dans le cambouis de Supabase, à peaufiner les compétences de nos agents IA. Je vous emmène dans les coulisses de notre processus pour non seulement les rendre bons, mais réellement efficaces. Dans cet article, je partage notre approche pour améliorer l'expérience des agents avec Supabase, en examinant la structure et les composants des compétences, et en comparant celles-ci aux outils MCP. On a utilisé des évaluations pour tester le comportement des agents, sans oublier le rôle crucial du cadre d'OpenAI. RLS sur Postgres, déploiement en production — chaque étape avait ses défis. Je vous explique comment j'ai orchestré tout cela, et surtout, ce que j'aurais aimé savoir plus tôt.
Boucles Ralph : IA Simples et Efficaces
Je me souviens encore de la première fois que j'ai construit une Boucle Ralph. C'était comme trouver la pièce manquante dans le puzzle du développement piloté par l'IA. On parle ici d'un vrai workflow, pas juste de la théorie. Au lieu d'une complexité inutile, ces boucles simplifient l'automatisation en utilisant des modèles d'IA comme GPT 5.8. Imaginez pouvoir orchestrer des tâches de manière fluide et efficace, tout en tenant compte des défis et des avantages de l'IA dans le développement logiciel. Dans cet article, je vous emmène dans le monde des Boucles Ralph, leur application pratique, et comment elles peuvent véritablement transformer votre manière de travailler. On va explorer ensemble les limites à garder en tête, les considérations de sécurité et d'éthique, et comment faire évoluer ces processus dans des environnements d'équipe. Et oui, l'avenir de l'IA dans l'automatisation des workflows complexes est déjà là. Alors, prêt à plonger?