GPT 5.4 Mini : Performance et Coût Comparé
Je plonge tête baissée dans les modèles GPT 5.4 Mini et Nano, et ces versions sont de véritables game changers. Mais attention, il y a des compromis à gérer. Avec l'évolution rapide des modèles d'IA, la série GPT 5.4 propose des options intrigantes pour les développeurs cherchant à équilibrer performance et coût. D'abord, j'ai configuré le Mini pour voir comment il se compare. Ses scores de 54,4 % en performance montrent qu'il tient la route, surtout quand on pense au coût réduit. Ensuite, j'ai testé le Nano, qui affiche 52,5 %. Idéal pour les applications où chaque milliseconde compte. Mais attention aux latences. On verra comment ces modèles peuvent s'intégrer dans vos workflows et surtout, où ils se démarquent vraiment par rapport à la concurrence.
Je me suis plongé dans les modèles GPT 5.4 Mini et Nano, et laissez-moi vous dire, ils changent la donne. Mais comme toujours, il y a des compromis à naviguer. Avec l'évolution rapide des modèles d'IA, la série GPT 5.4 offre des options intrigantes pour les développeurs qui cherchent à équilibrer performance et coût. D'abord, j'ai connecté le Mini pour voir comment il se compare. Avec un score de performance de 54,4 %, il tient la route, surtout quand on pense au coût réduit. Ensuite, j'ai testé le Nano, qui affiche 52,5 %. C'est parfait pour les applications où chaque milliseconde compte. Mais attention aux latences. Dans ce tutoriel, nous allons explorer comment ces modèles peuvent s'intégrer dans vos workflows quotidiens, et surtout, où ils se démarquent vraiment de la concurrence. L'accès et les options d'utilisation du Mini, ses cas d'utilisation spécifiques, et la comparaison des coûts avec d'autres acteurs du marché, tout sera passé au crible. Préparez-vous à découvrir comment ces modèles peuvent transformer votre approche du développement.
Découvrir GPT 5.4 Mini et Nano
Je me suis plongé dans les capacités de GPT 5.4 Mini et Nano pour vraiment comprendre ce qu'ils apportent au quotidien. Ces modèles, avec des scores respectifs de 54,4% et 52,5%, m'ont surpris par leur efficacité malgré leur petite taille. Ils sont spécifiquement conçus pour des cas d'utilisation agentiques et des tâches de vision par ordinateur. Comprendre leurs forces est essentiel pour choisir le bon modèle selon les tâches à accomplir.
Ce qui frappe, c'est comment ces modèles gèrent des tâches complexes avec une efficacité que je n'avais pas anticipée. Leurs faibles coûts ne signifient pas pour autant une baisse de performance, loin de là. En tant que développeur, choisir entre Mini et Nano peut dépendre de la complexité de la tâche et du besoin de vitesse ou de précision.
Métriques de Performance : Ce que Disent les Chiffres
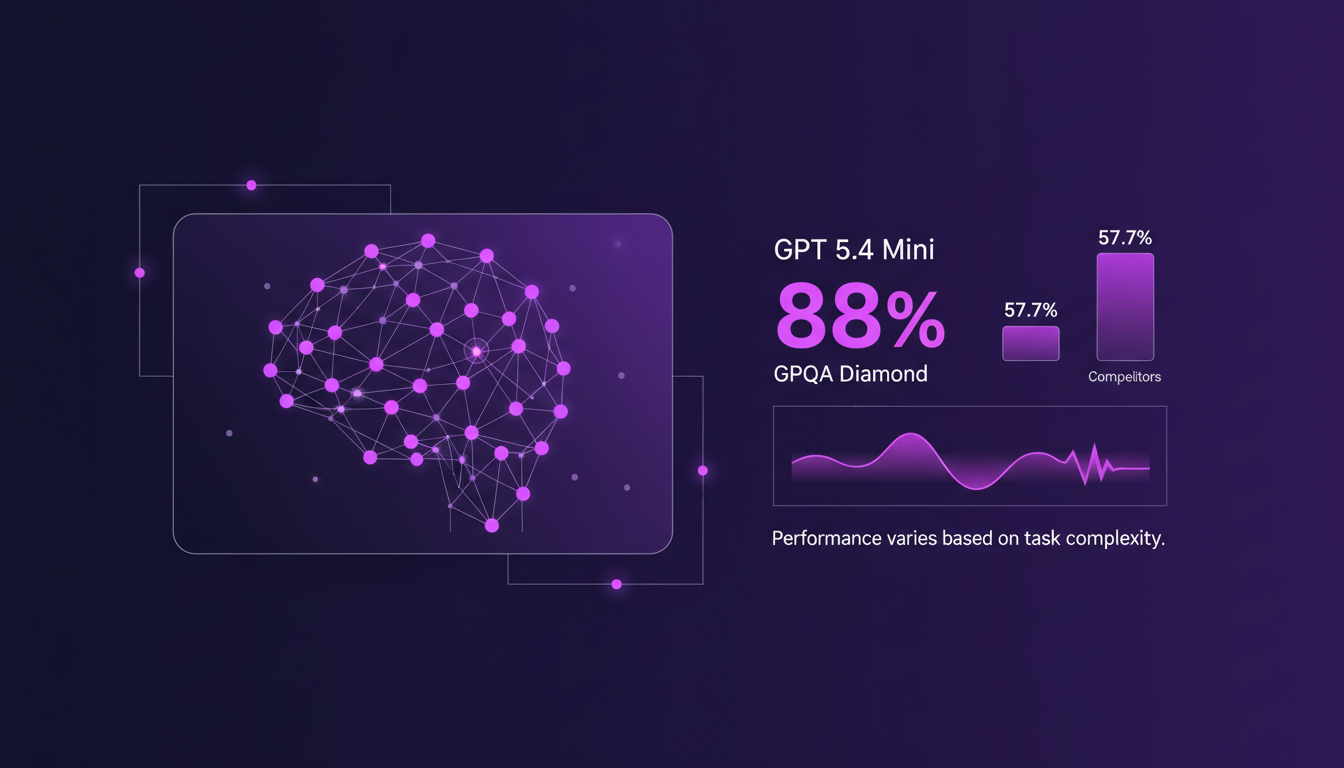
Quand j'ai commencé à benchmarker GPT 5.4 Mini, le score de 88% sur le GPQA diamond m'a vraiment impressionné. On est face à un modèle qui tient tête aux plus grands avec ses 57,7% de score global. C'est dans les tâches complexes que ces différences de performance deviennent cruciales. Un score plus élevé signifie généralement une meilleure efficacité pour des requêtes complexes.
J'ai testé ces modèles contre des concurrents, et voir GPT 5.4 Mini performer avec 54,4% sur le SWE bench pro m'a confirmé qu'il est taillé pour des tâches exigeantes en termes de réflexion. Pourtant, il faut se méfier des tâches trop complexes où même le plus petit écart de performance peut se faire sentir.
Efficacité Coût : Naviguer les Compromis
Le coût est toujours une préoccupation. Les modèles GPT 5.4 sont proposés à des prix très compétitifs. Comparé aux modèles plus grands, Mini et Nano offrent des économies substantielles dans certaines situations. Le prix des tokens et les sorties sont des éléments critiques à surveiller pour éviter les coûts cachés.

Parfois, dépenser un peu plus au départ peut vous éviter des maux de tête par la suite. En gros, GPT 5.4 Mini coûte 4,5$ par million de tokens de sortie, ce qui le rend bien moins onéreux que ses homologues plus grands. Mais attention à la tentation de sous-estimer le Nano : bien que moins cher, il peut ne pas toujours suffire pour des tâches complexes.
Cas d'Utilisation Réels : Où GPT 5.4 Excelle
J'ai utilisé GPT 5.4 Mini pour des applications en temps réel, et la latence est minimale. Les cas d'utilisation agentiques bénéficient énormément de l'efficacité du modèle. Pour les tâches de vision par ordinateur, on voit des améliorations notables en termes de vitesse de traitement.
L'efficacité dans ces scénarios se traduit directement par un impact business. Les gains en rapidité et précision dans des tâches comme le débogage de logiciels ou la revue de code sont palpables et justifient largement l'intégration de GPT 5.4 Mini dans des processus quotidiens.
Accès et Utilisation : Commencer avec GPT 5.4 Mini
La mise en place de GPT 5.4 Mini est simple, mais attention aux subtilités. J'ai trouvé les options d'utilisation flexibles, avec un accès API en plus. Les améliorations de latence signifient des résultats plus rapides dans des environnements à forte demande.
Pour commencer, il suffit de configurer votre accès via la plateforme d'OpenAI. Avec un contexte de 400k tokens et des coûts d'accès réduits, GPT 5.4 Mini est une option à considérer pour quiconque cherchant à optimiser ses coûts sans sacrifier la performance.
En résumé, GPT 5.4 Mini et Nano sont des outils puissants pour quiconque cherchant à équilibrer coûts et performance dans ses tâches d'IA. Ne sous-estimez pas l'importance de tester par vous-même pour voir où ces modèles peuvent s'intégrer dans vos workflows actuels. Ici un aperçu complet de ces modèles si vous voulez en savoir plus.
J'ai testé GPT 5.4 Mini et Nano, et franchement, je suis impressionné par l'équilibre entre performance et coût que ces modèles offrent. Quelques points clés à retenir :
- GPT 5.4 a atteint un score de 57,7%, ce qui en fait un choix robuste pour ceux qui cherchent à intensifier leurs outils IA.
- Pour des besoins plus légers, GPT 5.4 Mini et Nano sont tout aussi performants avec des scores respectifs de 54,4% et 52,5%.
- Côté budget, ces modèles restent compétitifs par rapport à d'autres options du marché. Alors oui, c'est un vrai game changer, mais attention à bien orchestrer vos projets pour maximiser l'efficacité.
Pour aller plus loin, je vous encourage à plonger dans vos propres projets avec GPT 5.4. C'est en expérimentant que vous verrez où cela peut vous mener. Regardez la vidéo complète "GPT 5.4 Mini en 5 minutes !" sur YouTube pour une vue d'ensemble : lien vidéo. L'efficacité et une orchestration intelligente sont vraiment la clé.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Mistral Small 4 : Déploiement et Cas d'Utilisation
J'ai récemment exploré le modèle Mistral Small 4, et laissez-moi vous dire, c'est une bête avec ses 119 milliards de paramètres. Mais ne vous laissez pas intimider ; tout dépend de la manière dont vous l'utilisez. Avec ses capacités multimodales et multilingues, ce modèle change vraiment la donne. Je vais vous guider à travers son déploiement, les compromis auxquels j'ai été confronté, et où il brille vraiment. Que vous compariez avec GPT-3 ou que vous cherchiez à comprendre les exigences matérielles, il y a ici de quoi optimiser votre approche AI. Attention, ne sous-estimez pas les spécifications techniques, car elles peuvent vous coûter cher en performance.
Grok TTS : Intégration API rapide et économique
Vous vous êtes déjà fait avoir par des solutions TTS hors de prix qui ne tiennent pas leurs promesses ? Moi aussi. C'est pourquoi j'ai opté pour Grok TTS. Rapide, économique et s'intègre comme un rêve. Avec plus de 20 langues supportées et des balises d'émotions intégrées, c'est un outil qui change la donne. Mais attention, ne vous laissez pas séduire uniquement par le prix, il est essentiel de comprendre comment l'intégrer efficacement dans vos applications. Comparons-le avec 11 Labs et voyons pourquoi Grok TTS pourrait être la solution que vous attendiez.
LangSmith Sandboxes : Exécution de Code Sécurisée
Je joue avec les LangSmith Sandboxes depuis un moment, et croyez-moi, réussir à lancer un environnement sécurisé en une ou deux secondes, c'est un vrai game changer. Mais ce n'est que la surface. Ces sandboxes sont essentielles pour l'exécution sécurisée du code. Que vous testiez de nouveaux segments de code ou réalisiez des simulations complexes, comprendre comment les configurer et les exploiter peut vous faire gagner du temps (et éviter bien des maux de tête). On va plonger dans les capacités des agents, les mesures de sécurité, et l'intégration avec des outils comme Docker et l'API OpenAI. Prêt à transformer votre workflow ?
Déployer des Agents avec Langraph CLI: Guide Pratique
Déployer des agents ne devrait pas être un casse-tête. Avec Langraph CLI, j'ai réduit mon temps de déploiement à quelques minutes. D'abord, je configure l'installation du CLI avec une simple commande 'uv tool install langraph cli'. Ensuite, je teste mes applications localement avec Langsmith Studio, ce qui me permet d'itérer rapidement (c'est crucial pour éviter les mauvaises surprises en production). Puis, je crée une nouvelle application Langraph avec 'langraph new' et je suis prêt pour le déploiement. Je vous explique comment j'ai intégré Langsmith, géré mes déploiements et utilisé les endpoints disponibles, tout ça en quelques commandes depuis le terminal. Croyez-moi, une fois que vous aurez goûté à cette simplicité, vous ne reviendrez plus en arrière.
Automatiser sans coder avec Claude Code
Je me souviens encore du moment où j'ai compris que je pouvais automatiser mes tâches sans écrire une seule ligne de code. C'était comme découvrir une arme secrète. Avec Claude Code, j'ai transformé des tâches répétitives en workflows efficaces, gagnant du temps et réduisant les erreurs. Dans cet article, je vais vous montrer comment j'ai fait, en passant en revue les cadres, les applications réelles et comment vous pouvez l'adapter à vos besoins uniques. Si l'efficacité est votre priorité, vous ne voudrez pas manquer ça.