Transformer dossier en LLM rapidement
Vous avez déjà regardé un amas de code en vous demandant comment le rendre intelligible en un claquement de doigts ? Eh bien, c'est exactement là qu'intervient Code to Prompt. J'ai traversé ça et voici comment j'ai fait fonctionner ce processus. On va plonger dans la transformation des dépôts GitHub en texte compatible avec les modèles LLM en utilisant cet outil, et tirer parti de Google Gemini. Il s'agit de rendre vos bases de code non seulement lisibles, mais exploitables. Je vous guide à travers l'intégration de Code to Prompt, l'optimisation de la gestion des tokens, et le déploiement de projets avec le code Gradio. Un vrai changement de jeu, mais attention aux limites des tokens.

Avez-vous déjà été face à une montagne de code, en souhaitant pouvoir le transformer en quelque chose d'intelligible d'un simple claquement de doigts ? Je connais bien cette situation. Avec Code to Prompt, j'ai réussi à transformer des répertoires GitHub en texte exploitable par LLM en un rien de temps. Ce n'est pas juste une question de lisibilité, mais de pouvoir agir sur votre base de code. Je vous emmène dans l'intégration de cet outil, et comment j'ai utilisé le modèle Google Gemini pour maximiser l'efficacité. Attention, la gestion des tokens est cruciale ici – j'ai appris à mes dépens que les limites de tokens peuvent vous jouer des tours. Une fois maîtrisé, vous pouvez personnaliser la génération de prompts et déployer vos projets en utilisant le code Gradio. On se lance ensemble dans ce processus, et je vous promets que ça va changer votre manière de travailler. Mais ne surutilisez pas les outils, car parfois, aller au plus simple est plus rapide.
Introduction à Code to Prompt : Donner du sens au chaos
Transformer du code en texte utilisable par des modèles de langage de grande taille (LLM) peut ressembler à une tâche titanesque. C'est là que Code to Prompt intervient. Cet outil, basé sur Rust, simplifie le processus de conversion de dépôts GitHub en texte LLM, ce qui est un véritable atout pour ceux d'entre nous qui cherchent à intégrer l'IA dans nos workflows quotidiens sans être submergés par la complexité technique. Je me souviens avoir converti mon dépôt 'coin market cap R', une vieille bibliothèque R que j'avais développée il y a 6 ans, en texte LLM pour Google Gemini. Ce fut un jeu d'enfant grâce à Code to Prompt, et j'ai immédiatement vu des gains en termes de temps et d'efficacité.
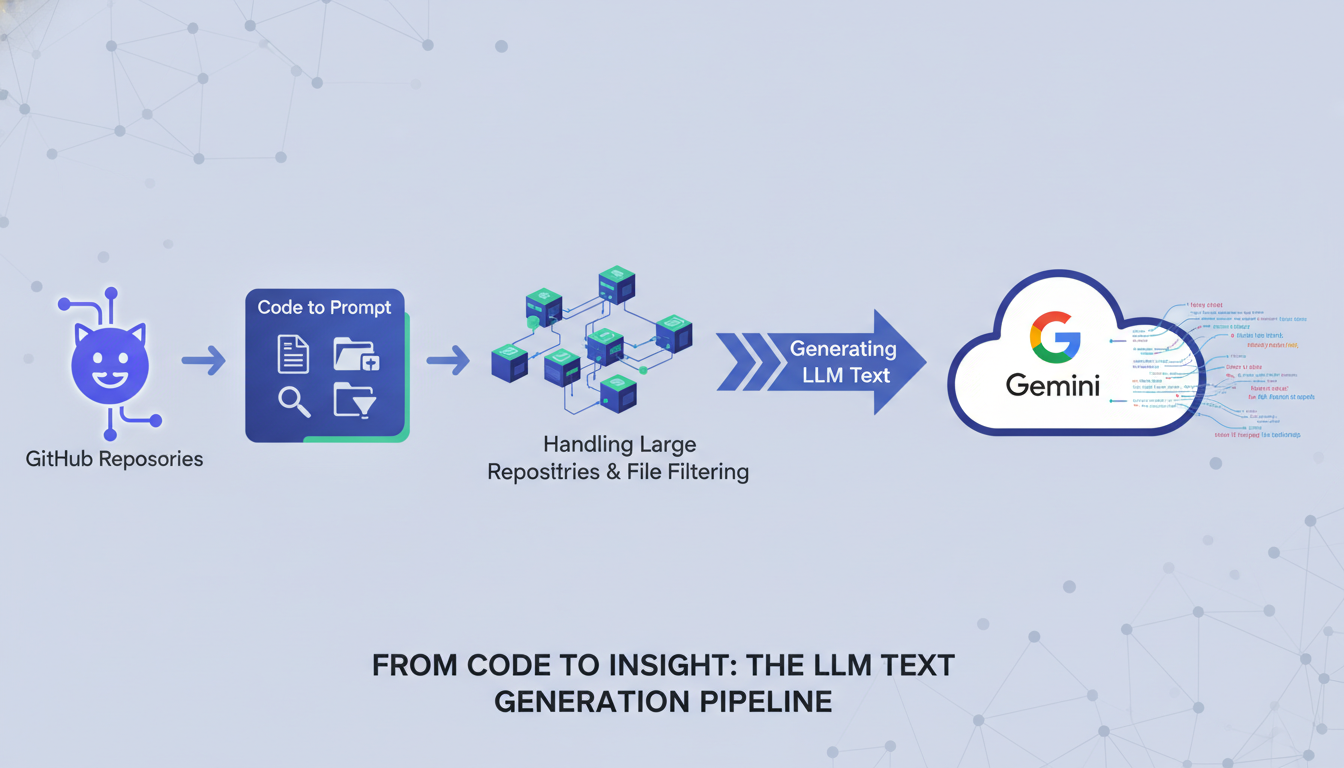
En intégrant cet outil dans votre flux de travail, vous pouvez non seulement économiser du temps mais aussi optimiser vos ressources. Le principal avantage ? La capacité de transformer un dépôt en texte LLM utilisable pour diverses applications. Cela change tout, surtout si vous êtes fatigué de la gestion manuelle des documents et souhaitez automatiser des tâches répétitives.
Conversion des dépôts GitHub en texte LLM
La conversion de dépôts GitHub en texte LLM est plus simple qu'elle n'y paraît. Avec Code to Prompt, le processus se fait en quelques étapes. D'abord, il faut installer l'outil via cargo install code-to-prompt. Ensuite, vous clonez le dépôt que vous souhaitez convertir. Pour mon dépôt 'coin market cap R', j'ai simplement exécuté code-to-prompt coin-market-cap-R, et en un rien de temps, mon code était transformé en texte LLM prêt à être utilisé avec le modèle Google Gemini.
Pour les dépôts de grande taille, un point crucial est de gérer le nombre de tokens. Avec Code to Prompt, j'ai pu déterminer que mon dépôt utilisait 85,3194 tokens, ce qui m'a permis d'optimiser l'utilisation des ressources. Attention toutefois aux limites de tokens, car elles peuvent rapidement devenir un goulot d'étranglement si l'on n'y prend pas garde.
Personnalisation de la génération de prompts pour de meilleurs résultats
Une des forces de Code to Prompt est sa capacité à personnaliser la génération de prompts. En utilisant des filtres de fichiers, on peut cibler précisément quelles parties du code convertir. Par exemple, ne convertir que les fichiers R. Cela permet non seulement d'économiser des tokens mais aussi d'optimiser la précision des prompts générés. La compréhension de la tokenisation dans les LLM est cruciale ici. Un prompt de 101,000 tokens sera beaucoup plus coûteux qu'un prompt optimisé à 16,000 tokens.

- Adapter les prompts à vos besoins spécifiques
- Optimiser les tokens pour équilibrer détail et performance
- Éviter les écueils courants en testant et ajustant continuellement
Déploiement avec Gradio : Donner vie à votre LLM
Une fois le texte LLM généré, l'étape suivante consiste à le déployer de manière efficace. C'est là que Gradio entre en jeu. Cet outil permet de créer des interfaces utilisateur conviviales pour vos applications LLM. En générant le code Gradio pour votre dépôt converti, vous pouvez rapidement mettre en place une application frontend complète. J'ai utilisé Gradio pour intégrer mon texte LLM dans une interface simple, permettant une interaction directe avec l'utilisateur.
Le langage de programmation Rust joue un rôle essentiel ici, grâce à sa performance et sa sécurité. Cependant, attention aux limites et compromis lors de l'utilisation de Gradio, notamment en ce qui concerne la compatibilité avec divers environnements de déploiement.
Gestion des tokens et optimisation des performances
Enfin, la gestion des tokens est un aspect clé pour garantir des performances optimales et des coûts maîtrisés. L'analyse du nombre de tokens utilisés par votre code est essentielle pour éviter des surprises désagréables. Des outils comme Code to Prompt permettent de comprendre et d'optimiser l'usage des tokens, impactant directement les performances et les coûts. Par exemple, j'ai pu ajuster mon dépôt pour utiliser 85,3194 tokens de manière plus efficace.
- Analyser et comprendre l'usage des tokens
- Mettre en place des stratégies de gestion efficace des tokens
- Utiliser des outils d'optimisation pour future-proof vos projets LLM
En somme, Code to Prompt offre une solution robuste et flexible pour convertir du code en texte LLM, déployable avec Gradio, tout en optimisant l'usage des tokens. En intégrant ces outils dans votre processus, vous pouvez non seulement améliorer vos workflows mais aussi anticiper les défis futurs, rendant vos projets LLM plus performants et économiquement viables.
Transformer le code en texte LLM exploitable, ce n'est pas un rêve, c'est un workflow que j'utilise. Avec Code to Prompt, je convertis mes dépôts en outils puissants, prêts à être déployés avec Gradio. D'abord, je configure mes prompts, puis j'optimise avec le modèle Google Gemini. Mais attention, il faut jongler entre efficacité, coût et performance.
- Concrètement, voici ce que j'ai appris :
- Code to Prompt transforme efficacement les dépôts GitHub en texte LLM.
- Utiliser le modèle Google Gemini améliore la personnalisation et la pertinence des prompts.
- La balance entre les 101 000 tokens utilisés et la performance doit être surveillée de près.
Je suis convaincu que cette approche peut vraiment changer la donne dans nos projets. Alors, essaie Code to Prompt lors de ta prochaine mission et partage tes découvertes. Ensemble, on peut optimiser et apprendre plus vite. Pour une compréhension plus approfondie, regarde la vidéo originale "Transforme n'importe quel dossier en connaissances LLM en SECONDES" sur YouTube.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Tracer les appels OpenRouter vers LangSmith
La première fois que j'ai essayé de suivre des appels API sans toucher une ligne de code, c'était mission impossible. Puis OpenRouter a lancé sa nouvelle fonctionnalité de diffusion. Je l'ai configurée avec LangSmith en un rien de temps, et ça a changé la donne. Pas besoin de perdre des heures à bricoler le code. Je connecte juste l'API d'OpenRouter, et en quelques clics, je trace les appels directement vers LangSmith. C'est vraiment efficace, mais attention à bien gérer les clés API et les coûts de LLM. Une solution pratique pour ceux qui cherchent à optimiser leurs workflows sans se compliquer la vie.
ChatGPT et Voix: Nouveautés et Astuces Pratiques
J'ai commencé à intégrer la voix dans mes applications de chat le mois dernier, et c'est vraiment un game changer. L'intégration de la voix n'est pas qu'un gadget ; elle transforme littéralement l'interaction utilisateur. Imaginez pouvoir demander à votre application de chat la météo en temps réel ou de vous indiquer les meilleures boulangeries du Mission District. On parle d'un niveau d'interaction complètement différent. Les fonctionnalités en temps réel, comme les cartes et la météo, ajoutent une dimension qui était autrefois inimaginable. Je vous explique comment j'ai mis ça en place et comment ça peut changer votre approche des plateformes de chat.
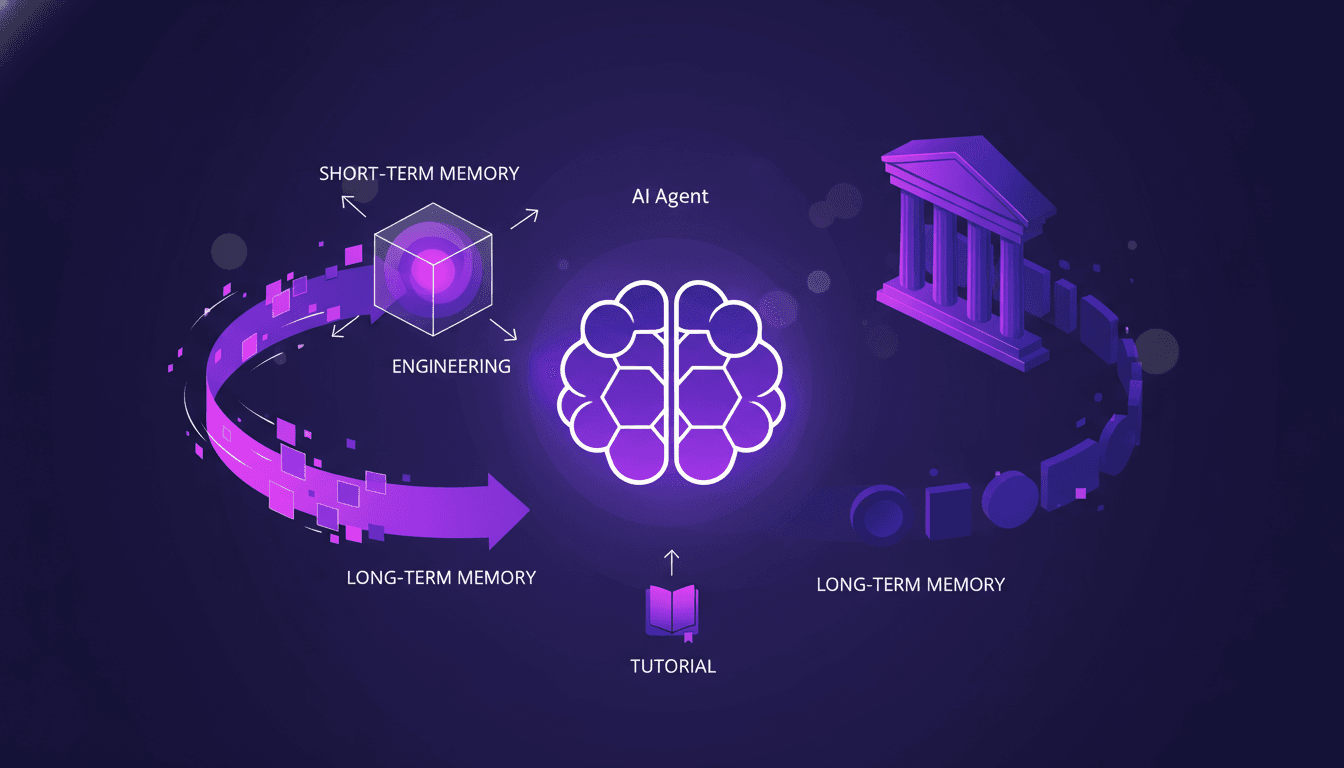
Optimiser la Mémoire des Agents IA: Techniques Avancées
J'ai passé des heures dans les tranchées avec des agents IA, à jongler avec des schémas de mémoire qui peuvent littéralement faire ou défaire votre setup. D'abord, plongeons dans ce que signifient vraiment les schémas de mémoire d'agent et pourquoi ils sont cruciaux. Dans les systèmes IA avancés, gérer la mémoire et le contexte ne se résume pas à stocker des données—c'est optimiser leur utilisation. Cet article explore les techniques et défis de la gestion du contexte, en s'appuyant sur des applications concrètes. On parle de différences entre mémoire à court et long terme, des écueils possibles, et des techniques pour une gestion efficace du contexte. Vous verrez, deux membres de notre équipe d'architecture ont vraiment creusé la question, et leurs insights pourraient changer la donne pour votre prochain projet.
Optimisez vos coûts avec Gemini 3 Flash OCR
J'ai plongé dans les tâches OCR depuis des années, et quand Gemini 3 Flash est arrivé, j'ai su que je devais tester ses promesses de réduction de coûts et de performances. Imaginez un modèle qui coûte quatre fois moins cher que le Gemini 3 Pro, à seulement 0,50 $ par million de tokens en entrée et 3 $ pour ceux en sortie. Je vous explique comment ce modèle se compare aux gros calibres et pourquoi c'est un véritable atout pour l'OCR multilingue. De la rentabilité aux capacités multilingues, en passant par les benchmarks techniques, je vous livre mes découvertes pratiques. Ne vous laissez pas avoir par le battage, venez découvrir comment Gemini 3 Flash transforme le jeu pour les tâches OCR.

Fonction Gemma : Appels de Fonction à la Périphérie
J'ai plongé dans la Fonction Gemma pour voir comment elle pouvait révolutionner les appels de fonction à la périphérie. En mettant la main sur le modèle Gemma 3270M, le potentiel est devenu immédiatement clair. Avec ses 270 millions de paramètres et un entraînement sur 6 trillions de tokens, ce modèle est conçu pour gérer efficacement des tâches complexes. Mais comment en tirer le meilleur parti ? Je l'ai affiné pour des tâches spécifiques et déployé avec Light RT. Attention, il y a des pièges à éviter. Allons-y, je vous explique tout.