Gemma 4 & MLX : IA sur iPhone à 40 tok/s
J'ai passé un bon moment à essayer de faire tourner des modèles d'IA sur des iPhones, mais atteindre 40 tokens par seconde avec Gemma 4 grâce à MLX, c'était vraiment un tournant. Dans cet article, je vous emmène à travers le processus, étape par étape, pour optimiser l'utilisation de Gemma 4 sur iPhone avec le framework MLX. On parle des optimisations pour le silicium d'Apple, de la quantification en 4 bits et 6 bits, et des défis que j'ai rencontrés avec la compatibilité des modèles. En gros, c'est du concret, pas de la théorie. Et si vous avez déjà essayé de faire tourner un LLM sur un iPhone et avez trouvé ça lent ou compliqué, ce guide est pour vous.
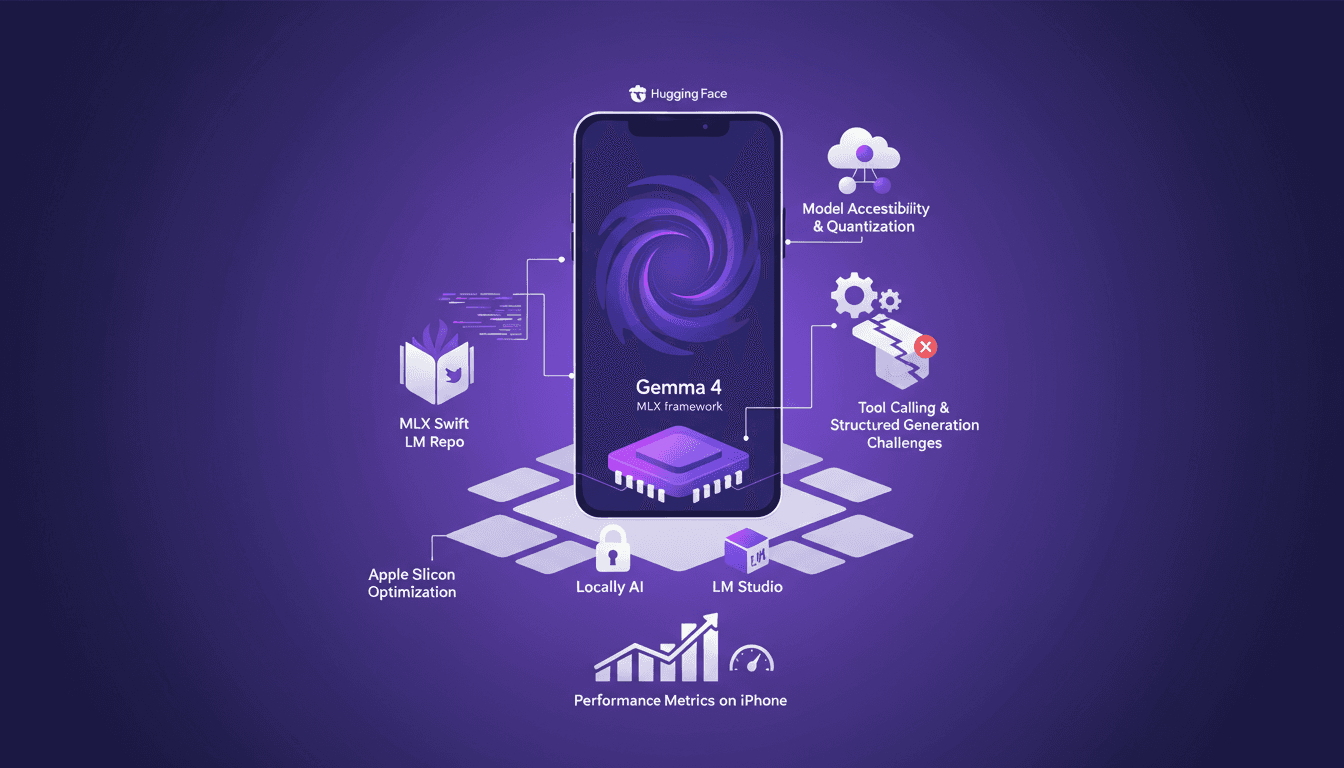
J'ai passé des nuits à bidouiller des modèles d'IA sur iPhone, mais là où j'ai vraiment pris mon pied, c'est quand Gemma 4 a atteint 40 tokens par seconde avec MLX. Ça change la donne, et je vais vous montrer comment. D'abord, on plonge dans l'optimisation de Gemma 4 sur iPhone avec MLX. Pas de blabla théorique ici, juste du concret. On va parler du framework MLX et de ses optimisations pour le silicium d'Apple, des quantifications en 4 et 6 bits, et de la manière dont j'ai navigué dans la compatibilité des modèles sur les iPhones. Sans oublier l'acquisition de Locally AI par LM Studio, et comment ça joue sur notre capacité à appeler des outils et à supporter des générations structurées. Bref, si vous avez déjà tenté de faire tourner un modèle sur iPhone et que vous avez trouvé ça lent ou limité, restez dans le coin, ça vaut le coup.
Mise en place de Gemma 4 avec MLX sur iPhone
Commençons par le commencement : installer le cadre MLX optimisé pour l'Apple Silicon. D'abord, téléchargez le framework depuis GitHub. C'est un passage obligé si vous voulez faire tourner Gemma 4 sur votre iPhone. Je me suis fait avoir une fois en pensant que c'était un simple clic, mais non, il faut vraiment suivre les instructions pour s'assurer que tout fonctionne avec le matériel de votre iPhone.

Ensuite, connectez-vous au dépôt MLX Swift LM. Pourquoi Swift LM ? Parce que c'est ce qui vous permet de développer des apps iOS en toute simplicité. J'ai appris à mes dépens que sauter cette étape peut entraîner des incompatibilités gênantes. Faites attention aux hiccups habituels lors de l'installation initiale, surtout avec les nouveaux frameworks comme celui-ci. Une fois tout configuré, testez les fonctionnalités de base avant de plonger dans les optimisations. Croyez-moi, ça vous évitera bien des maux de tête plus tard.
Comprendre le cadre MLX et l'optimisation Apple Silicon
Le cadre MLX est spécialement conçu pour l'Apple Silicon, ce qui booste considérablement les performances. C'est le genre de truc qui fait vraiment la différence. Le framework optimise l'allocation des ressources, ce qui est crucial pour les applications d'IA mobile. J'ai clairement vu la différence en termes de latence réduite sur mon iPhone. Mais attention, il y a des compromis : la vitesse peut parfois affecter la consommation de batterie.
"MLX est un cadre qui permet de faire tourner des modèles sur appareil, essentiel pour l'efficacité sur iPhone."
Comprendre la structure de base de MLX est essentiel pour maximiser l'efficacité. Je me suis brûlé les ailes plusieurs fois avant de vraiment intégrer comment fonctionne cette optimisation. Gardez à l'esprit que tout n'est pas parfait; il y a des limites qu'il faut savoir gérer. Si vous voulez en savoir plus sur l'optimisation de Gemma 4 avec MLX, je vous recommande cet article détaillé.
Accéder et quantifier les modèles avec Hugging Face
Pour accéder aux modèles, Hugging Face est une plateforme incontournable. J'y trouve la plupart des modèles que j'utilise. Vous avez des options de quantification : 4-bit, 6-bit, 8-bit. Personnellement, je préfère le 4-bit pour la vitesse, mais le 8-bit pour la précision. Cela dépend vraiment de la tâche. La quantification est cruciale pour la performance sur iPhone. Sachez qu'il peut y avoir des problèmes de compatibilité avec certains modèles, alors soyez prudent.

MLX permet de tourner des modèles quantifiés directement sur l’iPhone, ce qui est un atout majeur. Pour des détails plus techniques, vous pouvez consulter cette analyse comparative entre les performances 4-bit et 8-bit.
Appel d'outils et support de génération structurée
L'appel d'outils améliore la fonctionnalité des modèles, mais il faut l'intégrer judicieusement. La génération structurée est cruciale pour maintenir la qualité des sorties. Je vais vous montrer comment j'ai structuré mes appels pour optimiser les performances. Bien que les améliorations futures soient prometteuses, il existe des limites actuelles. Ne surchargez pas en appels d'outils, cela peut ralentir le traitement.
En utilisant les capacités d'appel d'outils de MLX Swift LM, j'ai pu améliorer la qualité des générés de manière significative. Pour ceux qui veulent automatiser la création de contenu technique en IA, je recommande de consulter cet article.
Gérer les défis liés à la taille et à la compatibilité des modèles
La taille du modèle peut vite devenir un goulot d'étranglement. Il est crucial d'optimiser l'utilisation du stockage. La compatibilité est un problème récurrent, donc testez minutieusement. J'ai rencontré plusieurs obstacles avec des modèles plus grands, mais je vais vous expliquer comment je les ai surmontés. Parfois, il est plus rapide de réduire la taille des modèles pour un usage mobile.
Restez à jour avec les mises à jour de MLX et iOS pour assurer la meilleure compatibilité. Pour des conseils sur l'optimisation et le déploiement mobile de Gemma 4, consultez cet article.
En résumé, travailler avec Gemma 4 et MLX sur iPhone nécessite une bonne compréhension des frameworks et des compromis techniques. Mais avec les bons outils et une bonne préparation, le potentiel est immense.
Alors, pour faire tourner Gemma 4 sur un iPhone avec MLX, ce n'est pas juste possible, c'est carrément efficace si on s'y prend bien. D'abord, je mets en place le framework MLX, optimisé pour l'Apple Silicon, puis je m'assure de son intégration fluide avec le dépôt MLX Swift LM pour le développement d'applications. Ensuite, les statistiques : atteindre 40 tok/s, c'est pas rien, mais il faut optimiser chaque étape pour y arriver, de la quantification en 4 bits ou 6 bits à l'accessibilité du modèle sur Hugging Face.
Points clés :
- Intégration fluide avec MLX pour Apple Silicon
- Modèle quantifié en 4 bits pour optimiser la performance
- Atteindre 40 tok/s avec des ajustements précis
Franchement, on est à un tournant pour les projets d'IA mobile. C'est le moment de s'y mettre, d'explorer ces astuces, de repousser ensemble les limites. Je vous invite à essayer vous-même, partagez vos expériences et regardez la vidéo complète d'Adrien Grondin sur YouTube pour plonger plus profondément. C'est comme ça qu'on avance, en échangeant et en explorant !
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires

Gemma 4 : Déploiement et Optimisation Mobile
J'ai plongé dans Gemma 4 dès sa sortie il y a seulement une semaine. Je l'ai intégré à mes workflows, en profitant de son design convivial pour les développeurs et de son optimisation mobile. Mais attention, il y a des compromis à considérer. Gemma 4, avec sa licence Apache 2 et son architecture E2B optimisée pour le mobile, redéfinit notre approche des modèles ouverts. Les capacités multilingues et multimodales de Gemma, ainsi que les contributions de la communauté, en font un acteur incontournable. Cependant, même avec ses 500 millions de téléchargements pour la famille Gemma, il est crucial de comprendre les limites techniques pour maximiser son potentiel.
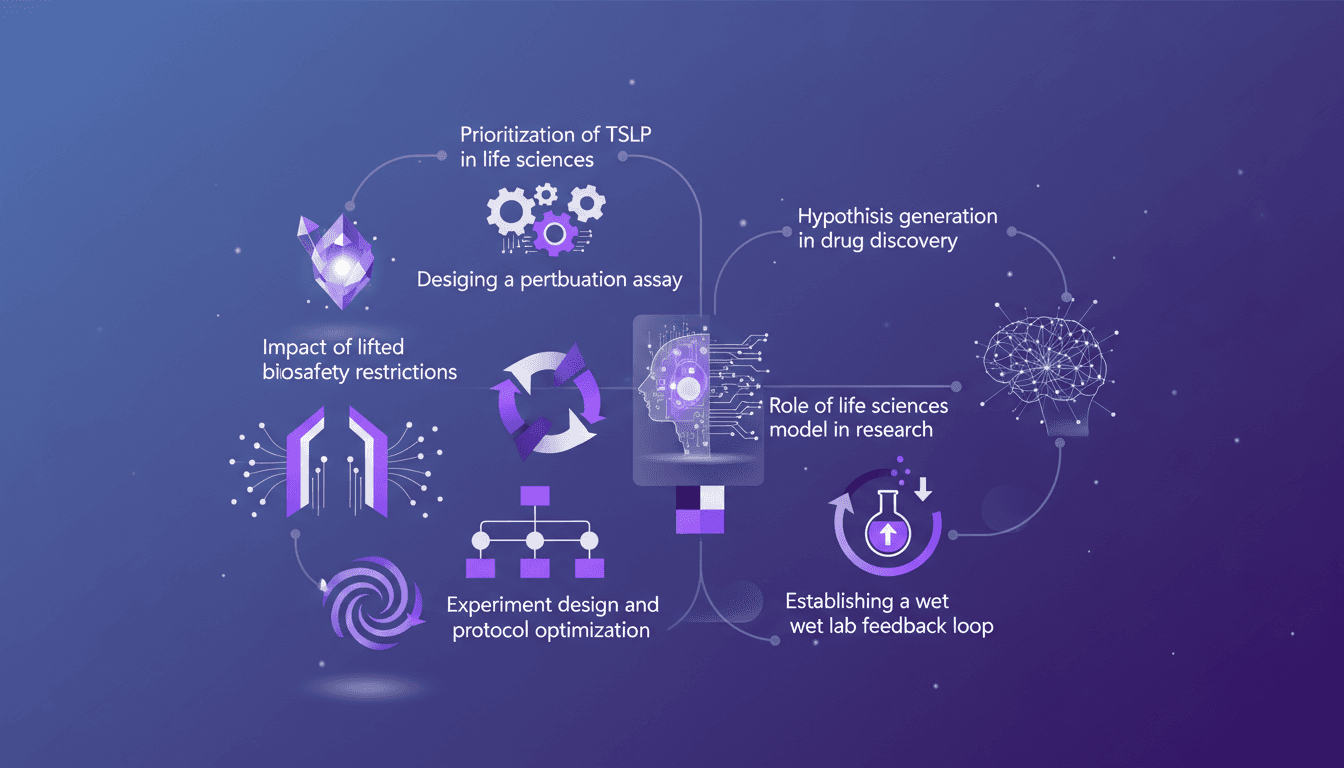
TSLP Priorisation : Accélérer la Recherche
Je me souviens du jour où nous avons finalement donné la priorité au TSLP dans notre modèle de sciences de la vie. C'était un véritable game changer. Nos expériences n'étaient pas seulement plus rapides, mais aussi plus intelligentes. Dans cet article, je vous explique comment nous avons fait et pourquoi c'est crucial. Dans le monde effréné des sciences de la vie, la conception d'expériences efficaces est essentielle. Avec la levée des restrictions de biosécurité, un nouveau champ de possibilités s'ouvre. Je vous guide à travers la priorisation du TSLP, la conception d'un test de perturbation, l'impact des nouvelles libertés en biosécurité, et l'optimisation des protocoles expérimentaux. Ne ratez pas comment établir une boucle de rétroaction en laboratoire humide et générer des hypothèses en découverte de médicaments.
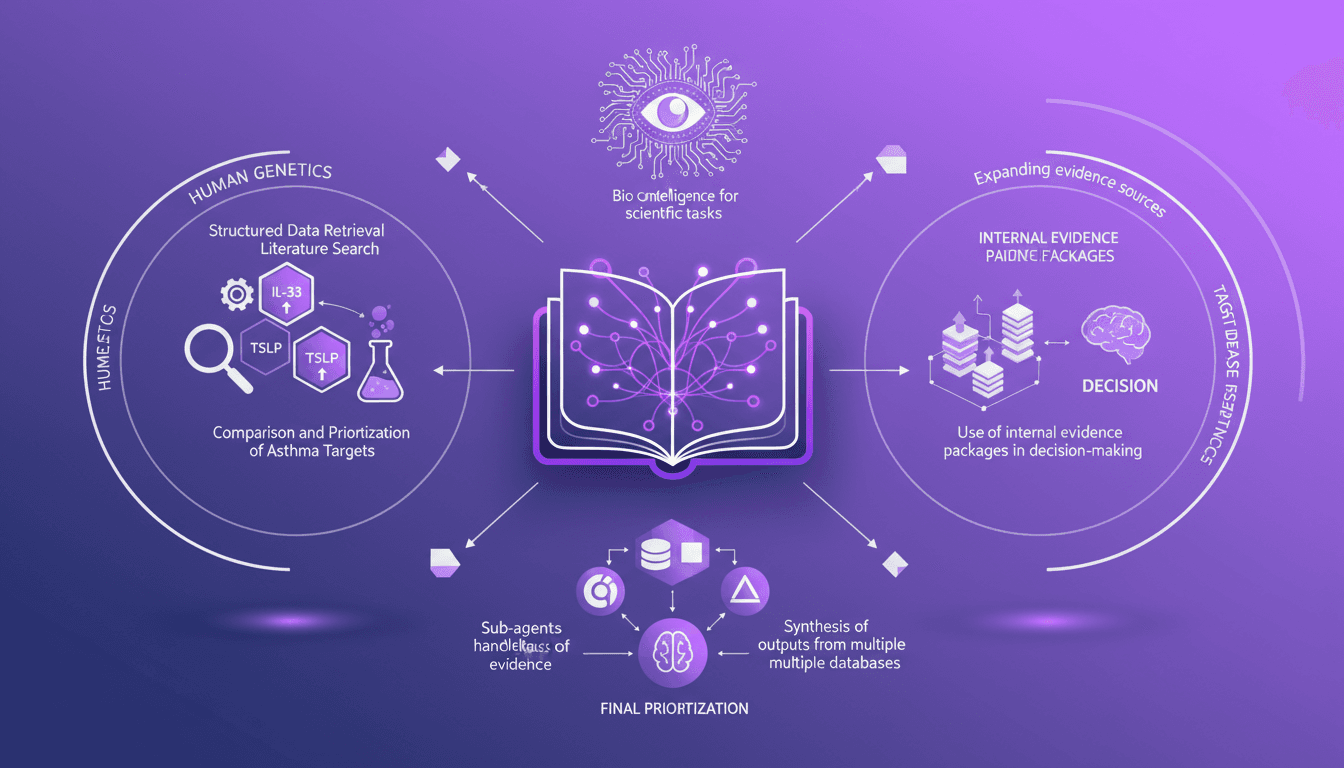
Intégration des données : cibles IL-33, TSLP
J'ai plongé dans le chaos des données, cherchant à démêler les preuves disparates en sciences de la vie. Avec Codex, j'ai transformé ce désordre en insights actionnables. Dans cette vidéo, je vous montre comment j'ai intégré la recherche de données structurées avec l'analyse scientifique pour comparer les cibles de l'asthme comme IL-33, TSLP et IL-1 RA1. Je partage mon workflow, en utilisant des packages de preuves internes pour prendre des décisions éclairées. C'est une plongée technique, mais je suis là pour vous guider à travers chaque étape.
Automatiser la Création de Contenu Technique en IA
J'ai passé plus de quatre ans à enseigner l'IA, et si j'ai bien appris une chose, c'est que construire ses propres agents de recherche approfondie peut tout changer. Mais attention, il ne suffit pas de balancer du code à l'aveuglette; il s'agit de créer des workflows cohérents et efficaces. Dans cet article, je vous emmène dans les coulisses de mes agents de recherche, des stratégies pour éviter le surapprentissage et atteindre des scores F1 élevés, tout en intégrant ces systèmes dans vos opérations quotidiennes. Nous aborderons aussi l'automatisation de la création de contenu technique et l'optimisation des évaluateurs IA. C'est un équilibre entre autonomie et contrôle, et je vous montrerai comment je l'ai atteint.
Créer l'urgence: Concept 'Ed My Life' en pratique
Dans le monde des ventes, créer un sentiment d'urgence peut être le facteur décisif qui scelle une affaire. Le concept 'Ed My Life', loin de n'être qu'une théorie, est un véritable coup de maître. Je l'applique systématiquement pour concrétiser plus de deals. Imaginez que vous discutiez avec un prospect et que vous lui faites réaliser, en à peine 60 secondes, ce qu'il pourrait perdre s'il ne prend pas de décision rapide. Ce n'est pas une question de pression, mais une démonstration claire des opportunités manquées. Dans cet article, je vous montre comment je mets en pratique cette stratégie pour transformer les hésitations en actions et pourquoi cela a un impact direct sur les résultats d'affaires.