Minimax M2.5 : Atouts et Limites Décryptés
J'ai eu entre les mains le Minimax M2.5, et croyez-moi, ce n'est pas juste un modèle de plus sur l'étagère. Je l'ai intégré à mon workflow, et son prix m'a fait repenser toute ma configuration. Mais attention, il ne s'agit pas que de l'étiquette de prix. Ce modèle se distingue par ses spécificités techniques et son efficacité. Alors, pourquoi le Minimax M2.5 mérite-t-il votre attention ? On va plonger dans ses atouts, ses limites, et comment il se compare à ses concurrents. Parlons aussi des stratégies d'apprentissage par renforcement et des cas d'utilisation potentiels. Préparez-vous, car ce modèle pourrait bien secouer votre façon de travailler.
J'ai plongé tête baissée dans le Minimax M2.5, et dès que je l'ai connecté à mon workflow, j'ai su que ce n'était pas un modèle comme les autres. À 120$ seulement pour 50 tokens par seconde, il m'a fait réévaluer ma config entière. Mais ne vous y trompez pas, ce n'est pas qu'une question de prix. Ce qui se cache sous le capot est tout aussi impressionnant. Dans un paysage où les modèles d'IA foisonnent, le Minimax M2.5 sort du lot grâce à ses prouesses techniques et son tarif abordable. Parlons donc des forces et des limites de ce modèle : la stratégie d'apprentissage par renforcement, les spécifications techniques, et comment il se mesure face à la concurrence. Je vais aussi partager mes insights tirés des benchmarks d'OpenHands et discuter des défis dans la formation et le déploiement de ce modèle. Restez avec moi, car ce modèle pourrait bien transformer votre approche du travail.
Accessibilité et Prix du Minimax M2.5
Quand j'ai découvert le Minimax M2.5, j'ai d'abord été frappé par son prix: un modèle à 120 $ offrant 50 jetons par seconde. Pour quelqu'un qui a déjà travaillé avec des modèles d'IA coûteux, c'était une aubaine. On a aussi le modèle lightning à 240 $ qui double le débit. Comparé aux 15 à 20 $/heure pour des modèles comme Frontier AI, c'est presque donné.

Avec un coût opérationnel aussi bas que 1 $/heure, le M2.5 est parfait pour les projets soucieux de leur budget. Dans mon agence, où chaque dollar compte, cette économie est cruciale. Le rapport qualité-prix est tel qu'il devient accessible même pour les startups avec peu de moyens.
- Modèle à 120 $ avec 50 jetons/sec
- Modèle lightning à 240 $ doublant le débit
- Coût opérationnel de 1 $/heure
- Idéal pour les projets à budget limité
Comparaison du Minimax M2.5 avec ses Concurrents
Pour comprendre où le M2.5 se situe, j'ai comparé ses performances avec des modèles comme Claude Opus et ceux de Google. Le M2.5 brille par son efficacité-coût. Là où ses concurrents peuvent coûter jusqu'à 15-20 $/heure, le M2.5 propose une performance semblable pour une fraction du prix.
Sa vitesse, son coût et son débit de jetons sont ses points forts. Mais attention, il y a un compromis entre le prix et certaines fonctionnalités. Les recommandations d'OpenHands et de Carnegie Mellon ajoutent à sa crédibilité, mais chaque projet a ses besoins spécifiques.
- Comparaison avec Claude Opus et Google
- Efficacité-coût sans sacrifier la vitesse
- Endossements par OpenHands et Carnegie Mellon
Stratégies d'Apprentissage par Renforcement et Spécifications Techniques
Plongeons dans l'apprentissage par renforcement (RL). Le M2.5 utilise des stratégies d'apprentissage sur-politiques et hors-politiques, ce qui optimise ses performances. J'ai expérimenté avec des stratégies d'ordonnancement asynchrones pour une performance optimisée, et le modèle Mixture of Experts trouve un équilibre entre complexité et efficacité.
Les spécifications techniques montrent un débit de jetons impressionnant et une puissance de traitement robuste. Cependant, attention aux pièges potentiels lors de l'entraînement. J'ai souvent vu des configurations mal optimisées entraîner des performances médiocres.
- Apprentissage par renforcement (on-policy vs off-policy)
- Stratégies d'ordonnancement asynchrones
- Modèle Mixture of Experts
- Débit de jetons et puissance de traitement
Benchmarking d'OpenHands et Cas d'Utilisation
Les benchmarks d'OpenHands offrent des aperçus précieux sur les performances du monde réel. Le M2.5 se distingue dans des cas d'utilisation variés, de la recherche en IA aux applications commerciales. Les recommandations mettent en évidence ses impacts pratiques et ses limites.
Il excelle dans certains scénarios mais peut être limité dans d'autres. J'ai constaté que dans des environnements variés, il faut bien considérer les particularités de chaque déploiement.
- Benchmarking d'OpenHands
- Cas d'utilisation variés
- Impacts pratiques et limitations
Sortie, Disponibilité et Défis de Déploiement
Le M2.5 est actuellement disponible, mais comment le mettre en œuvre? Les défis de déploiement incluent l'intégration dans les systèmes existants. La courbe d'apprentissage peut être raide, mais avec les bonnes ressources, les économies à long terme valent l'investissement initial.
Restez à l'affût des mises à jour et du support de Minimax et de ses partenaires. J'ai souvent vu des projets échouer faute de maintenance continue.
- Disponibilité et obtention du M2.5
- Défis d'intégration et de déploiement
- Équilibre entre coûts initiaux et économies à long terme
Le Minimax M2.5, ce n'est pas seulement un modèle économique. C'est une véritable centrale électrique. J'ai testé ses stratégies efficaces d'apprentissage par renforcement et, franchement, pour un prix de départ de 120 $, il n'y a pas mieux. Par exemple, le modèle à 50 jetons par seconde offre une vitesse de traitement impressionnante pour son prix. Mais attention, si vous voulez encore plus de punch, le modèle à 240 $ avec 100 jetons par seconde est un vrai changement de jeu.
- Rapport qualité-prix imbattable : Pour 120 $, c'est un excellent point de départ pour les projets AI sans casser la tirelire.
- Performance ajustable : Les versions de 50 et 100 jetons par seconde vous permettent de choisir en fonction de vos besoins.
- Stratégies d'apprentissage efficaces : Les méthodes d'apprentissage par renforcement sont optimisées pour une utilisation quotidienne.
Honnêtement, c'est le moment de l'intégrer dans votre flux de travail. Si vous êtes prêt à voir comment cela peut transformer vos projets AI, foncez. Mais comme toujours, testez-le dans votre contexte pour voir comment il se comporte. Découvrez-le plus en profondeur dans la vidéo originale. Votre prochaine étape ? Plongez dans l'univers du Minimax M2.5 ici : lien vidéo.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
WebM MCP : Cas d'usage et perspectives futures
Quand j'ai entendu parler du WebM MCP pour la première fois, j'étais sceptique. Mais une fois que j'ai plongé dedans, décortiqué ses API, et vu son potentiel, j'ai compris que c'était un vrai game changer pour le déploiement des agents IA. Développé par Google et Microsoft, WebM MCP propose une nouvelle approche pour gérer le traitement des médias avec des agents IA. Dans cet article, je partage mon expérience pratique, les pièges à éviter, et comment j'ai intégré cet outil dans mon workflow quotidien. Imaginez gérer des milliers de tokens pour chaque image traitée, avec seulement deux API à maîtriser. Je vous guide à travers les avantages, les cas d'utilisation et les perspectives futures de cet outil puissant.
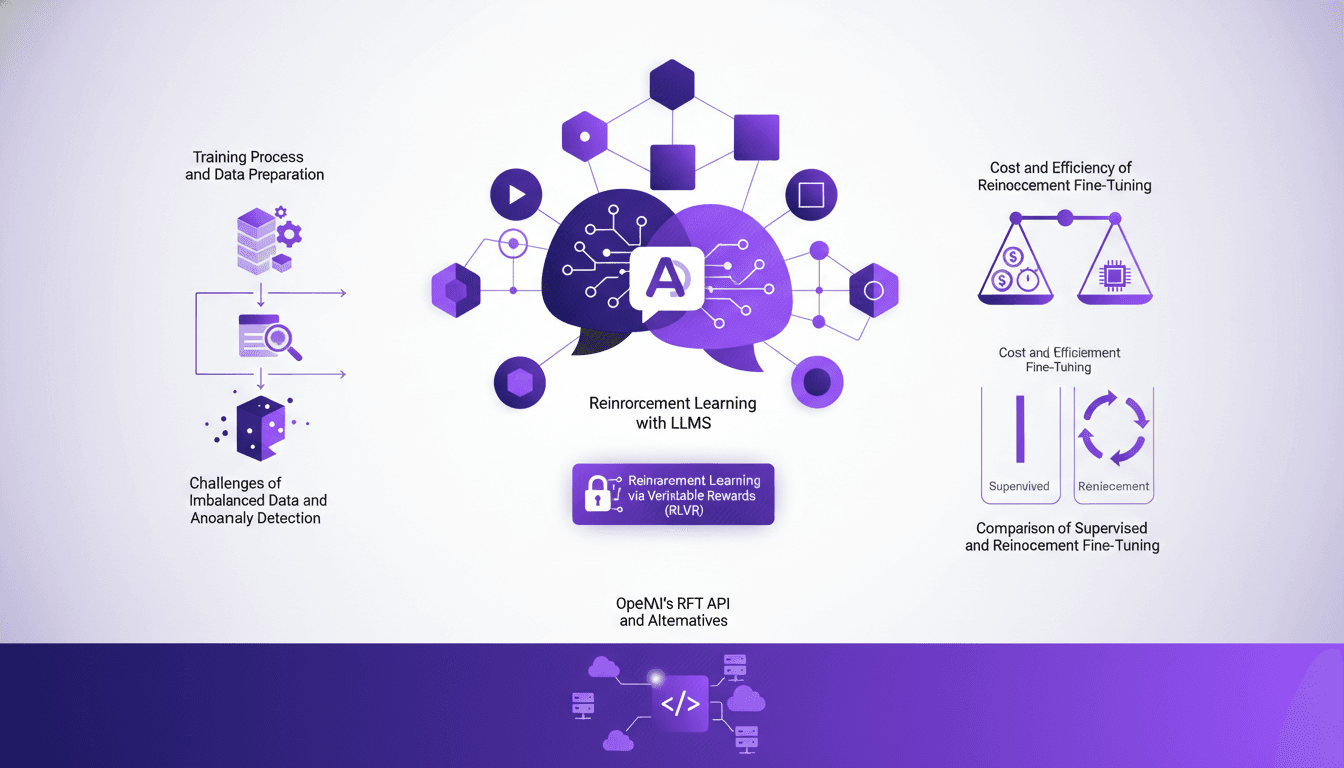
Optimisation des LLMs: RLVR et API OpenAI
Je suis plongé jusqu'au cou dans l'affinage des modèles de langage (LLMs) grâce à l'apprentissage par renforcement via des récompenses vérifiables (RLVR). Pas de théorie ici, juste des jeux d'efficacité et de coûts, avec l'API RFT d'OpenAI comme principal outil. Dans cette vidéo, je vous montre comment je m'y prends. On va plonger dans le processus de formation, s'attaquer aux données déséquilibrées et comparer les méthodes d'affinage, tout en gardant un œil sur les coûts. C'est notre troisième épisode sur l'apprentissage par renforcement avec les LLMs, et on va aussi parler des alternatives à l'API d'OpenAI. Petit avertissement : à 100 dollars de l'heure, ça grimpe vite !
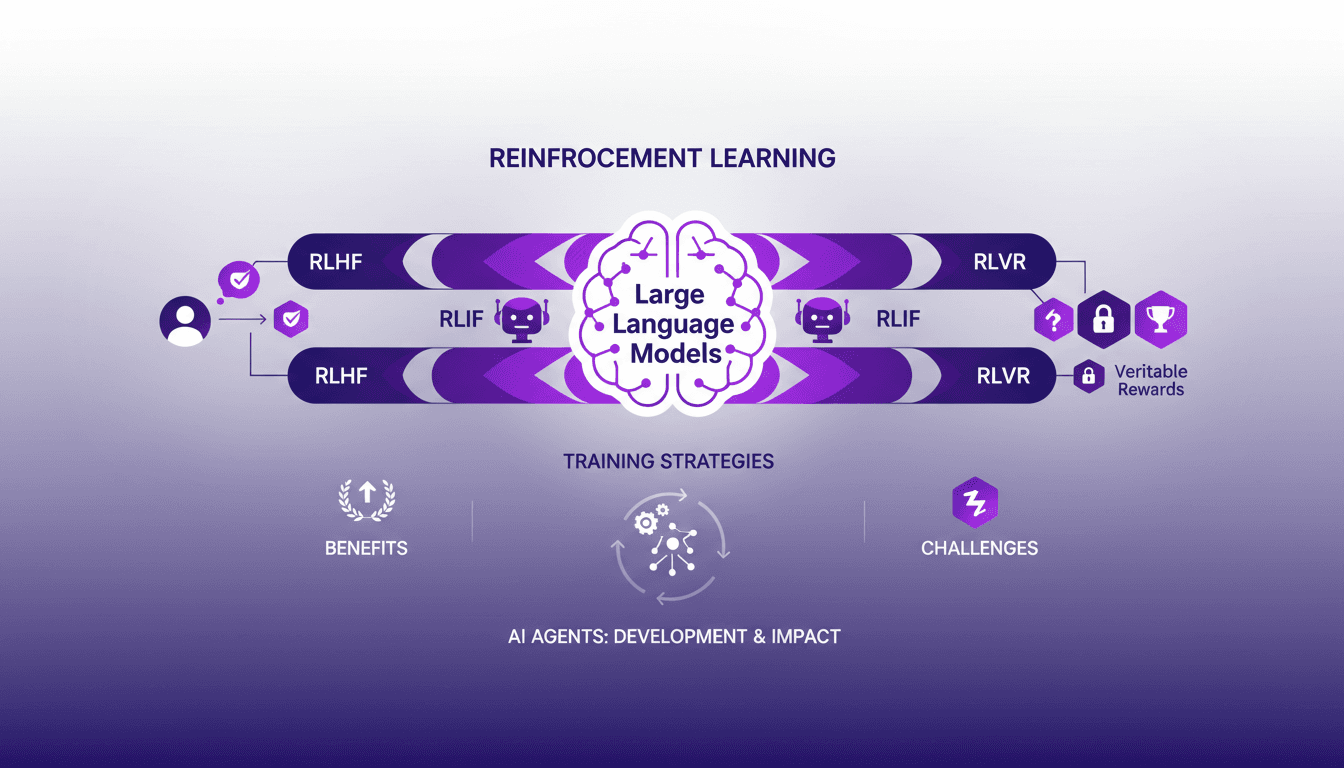
Apprentissage Renforcé pour LLMs: Nouveaux Agents IA
Je me souviens encore de la première fois où j'ai intégré l'apprentissage renforcé dans la formation des modèles de langage de grande taille (LLMs). C'était en 2022, et avec le développement de ChatGPT encore frais en mémoire, j'ai compris que c'était un véritable game changer pour les agents IA. Mais attention, il y a des compromis à prendre en compte. L'apprentissage renforcé révolutionne la façon dont nous formons les LLMs, offrant de nouvelles méthodes pour améliorer les agents IA. Dans cet article, je vous emmène avec moi dans mon aventure avec l'AR dans les LLMs, partageant des aperçus pratiques et les leçons apprises. Je vais parler de l'apprentissage renforcé avec feedback humain (RLHF), feedback IA (RLIF), et récompenses vérifiables (RLVR). Préparez-vous à découvrir comment ces approches transforment notre manière de concevoir et d'entraîner les agents IA.
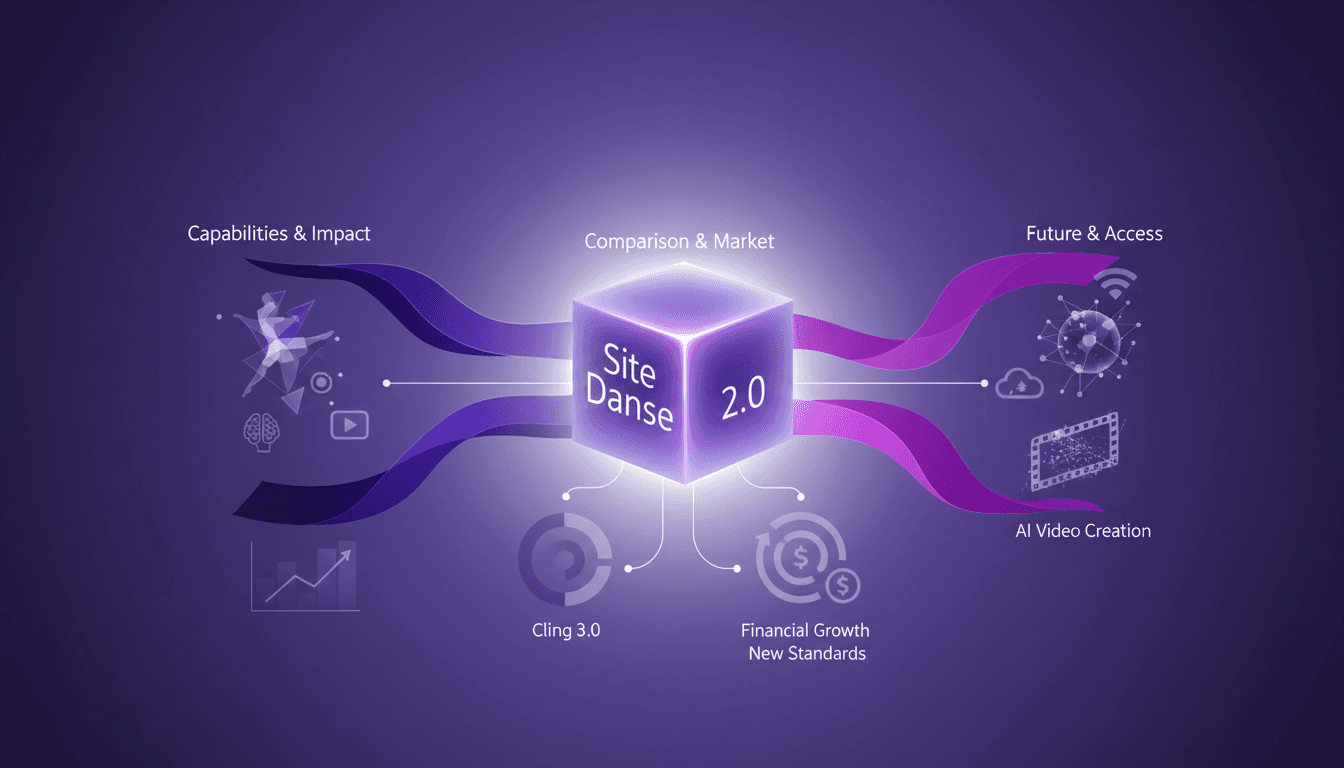
Seedance AI 2.0 : Révolution Vidéo Création
Je me suis plongé dans Seedance AI 2.0 en pensant découvrir un outil d'IA parmi tant d'autres, mais j'ai trouvé un véritable bouleversement. Ce n'est pas juste du hype technologique—c'est un vrai changement dans la création vidéo. Avec Seedance AI 2.0, on assiste à une révolution de notre façon d'exploiter l'IA pour le contenu vidéo. Ce n'est pas seulement une question de fonctionnalités tape-à-l'œil; c'est un impact concret sur les flux de production. En comparaison avec Cling 3.0 et d'autres modèles, Seedance AI 2.0 se distingue par ses capacités techniques et son impact sur le marché. Les entreprises chinoises ont vu leurs actions augmenter de 10 à 20 % en une seule journée. Et cette résolution native de 2048 x 1080, ça change tout! Je vous explique comment je l'ai intégré dans mon workflow et les implications financières à envisager. Soyez prêts à découvrir comment cette technologie pourrait redéfinir le futur de la création vidéo.
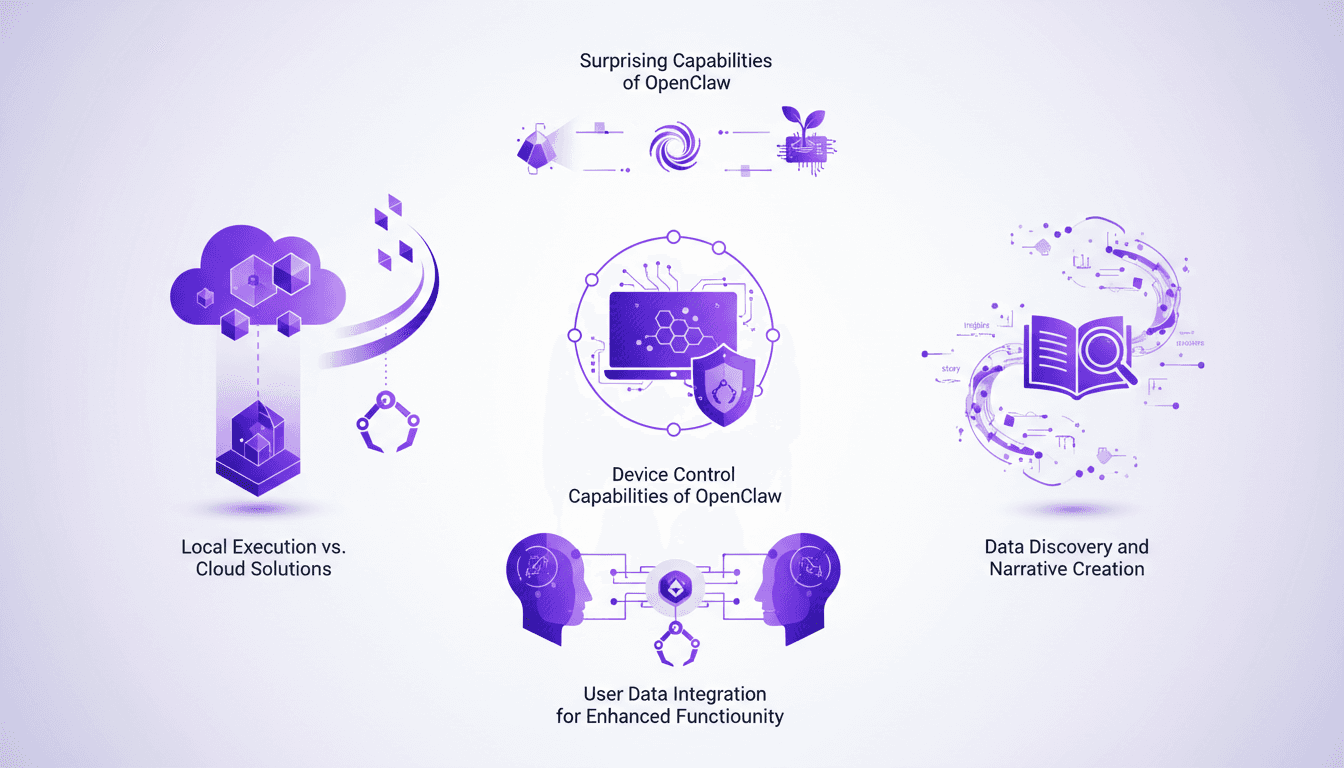
OpenClaw : Exécution locale vs solutions cloud
Je me souviens encore de la première fois où j'ai lancé OpenClaw sur ma machine locale. C'était comme libérer une bête capable de tout faire, du contrôle des appareils à la découverte des données. Ce qui m'a vraiment surpris, c'est la manière dont il rivalise avec les solutions cloud. Dans ce billet, je vais partager comment OpenClaw perturbe le paysage technologique avec son exécution locale. On va plonger dans son potentiel de contrôle d'appareil, de découverte de données, et d'intégration utilisateur. Croyez-moi, OpenClaw change la donne, mais attention aux pièges et aux contextes où il peut vous surprendre.