Gemini 2.5 Pro : Performances et Comparaisons
J'ai plongé dans le Gemini 2.5 Pro avec des attentes élevées, et il n'a pas déçu. De l'exactitude en codage à l'ancrage de recherche, ce modèle repousse les limites. Mais il y a bien sûr des compromis à envisager. Avec un score de 1443, le plus élevé dans l'arène des LM, et une précision quasi parfaite dans les tâches de reconnaissance de caractères, Gemini 2.5 Pro impressionne. Cependant, l'utilisation excessive des outils et la tendance à sur-analyser peuvent parfois ralentir le processus. Je partage ici mon expérience pratique avec ce modèle, mettant en lumière ses forces et ses pièges potentiels. Préparez-vous à découvrir comment Gemini 2.5 Pro se compare et où il pourrait vous surprendre.

Je me suis lancé dans le test du Gemini 2.5 Pro avec une certaine impatience, et autant vous le dire, il a tenu ses promesses. Ce modèle ne se contente pas de frôler la perfection en reconnaissance de caractères, il a carrément fait un sans-faute. Et avec son score de 1443, il se place en tête du classement dans l'arène des LM. Mais attention, tout n'est pas rose. J'ai remarqué une certaine tendance à sur-analyser qui peut coûter du temps (et de l'argent). Dans cet article, je vous partage mon expérience directe : performances, comparaisons, capacités en codage, et où le bât blesse. En gros, je vous préviens là où vous pourriez vous faire avoir comme moi au début. Ça vaut vraiment le coup d'œil, surtout si vous cherchez à savoir si le jeu en vaut la chandelle pour vos projets.
Performance de Référence : Battre des Records
J'ai été bluffé par Gemini 2.5 Pro, le premier modèle à avoir franchi la barre des 1443 dans les benchmarks, établissant ainsi un nouveau standard. Il a surpassé des modèles comme Claw 3.5 et 3.7 avec un score impressionnant de 18,8 % selon Scale AI. Mais attention, les attentes peuvent être surévaluées—la performance dans le monde réel peut varier.
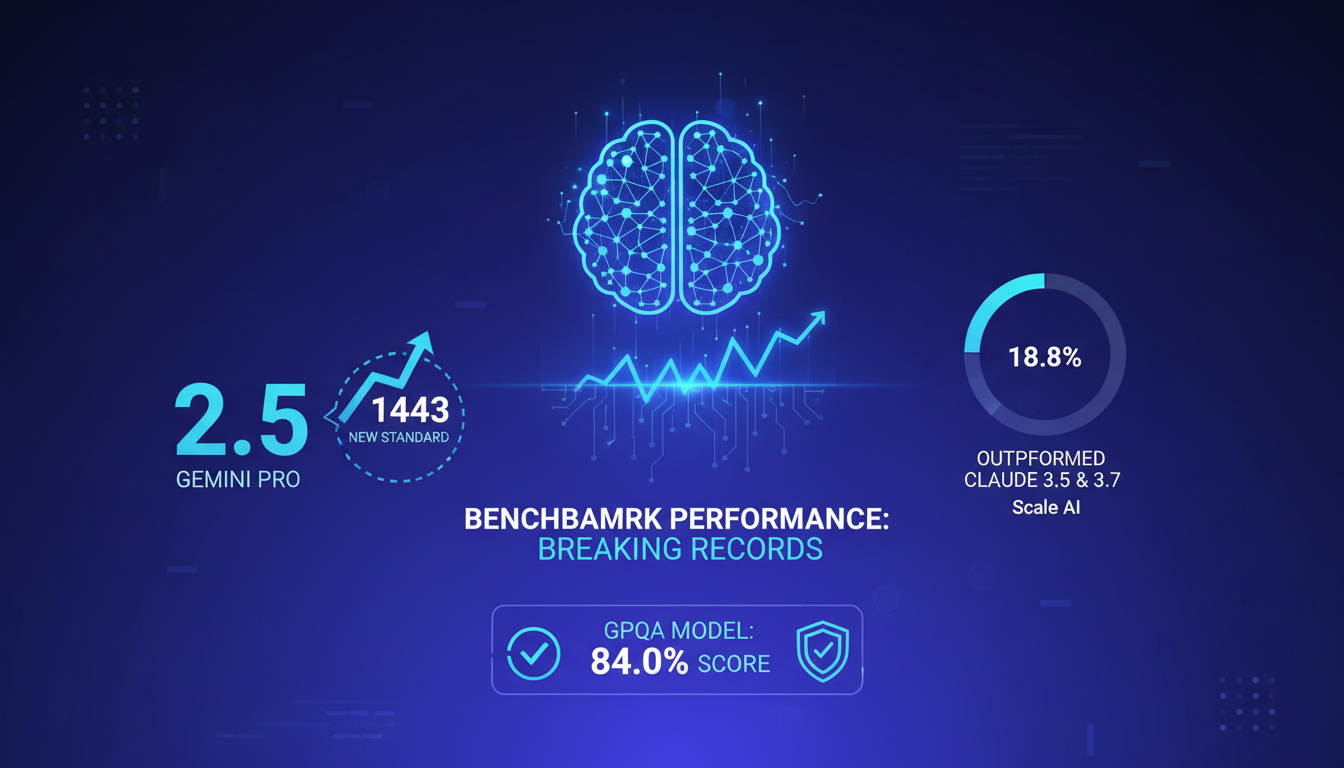
Le modèle GPQA a également obtenu un score de 84,0 %, démontrant son efficacité. Cependant, il faut garder un œil critique sur ces chiffres. Dans mes tests, les résultats peuvent fluctuer en fonction de la tâche et du contexte.
- 1443 : Premier modèle à atteindre ce score, positionnant Gemini 2.5 Pro au sommet.
- 18,8 % : Score supérieur à Claw 3.5 et 3.7 selon Scale AI.
- 84,0 % : Score GPQA, prouvant son efficacité.
Ancrage de Recherche et Utilisation des Outils
L'une des forces de Gemini 2.5 Pro est son excellence en ancrage de recherche, ce qui améliore considérablement la pertinence contextuelle. Quand je l'ai intégré à mon ensemble d'outils existant, la transition a été fluide. Le modèle offre une pertinence contextuelle que je n'avais pas vue auparavant.
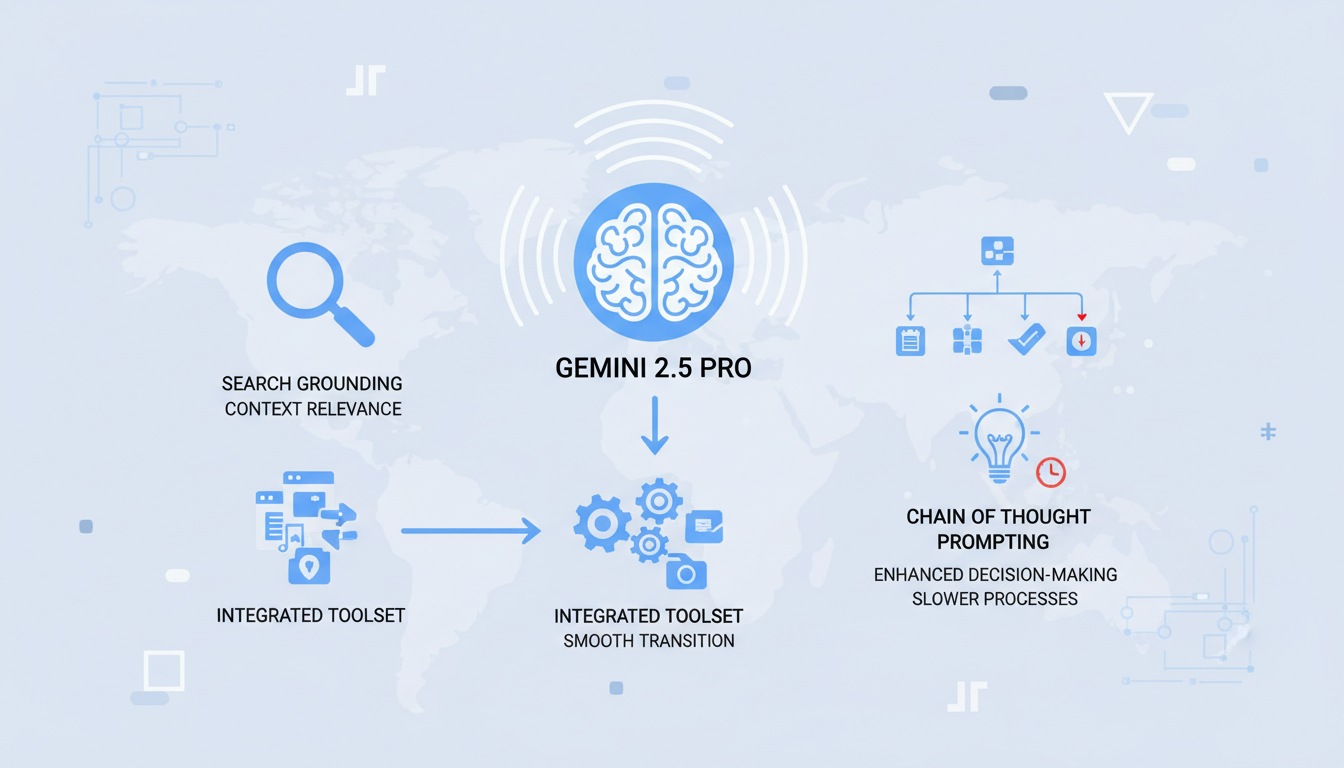
Chain of Thought Prompting est un autre atout, améliorant la prise de décision. Mais attention, cela peut ralentir les processus si on s'y fie trop. Trouver l'équilibre est crucial pour éviter les inefficacités.
- Ancrage de recherche : Améliore la pertinence des réponses.
- Transition fluide : Facile à intégrer aux outils existants.
- Chain of Thought : Utile mais peut ralentir si surutilisé.
Codage et Reconnaissance de Caractères : Une Exploration Approfondie
Dans les benchmarks de codage, Gemini 2.5 Pro a marqué 74 %, ce qui est solide pour les tâches de programmation. J'ai testé cela moi-même, et le modèle gère bien le code complexe. La reconnaissance de caractères est presque parfaite avec une seule erreur notée.

L'understanding multimodal du modèle renforce sa polyvalence. Cependant, pour les tâches simples, n'en abusez pas—un modèle plus léger est parfois plus rapide et tout aussi efficace.
- 74 % : Solide dans les benchmarks de codage.
- Presque parfait : Une seule erreur de reconnaissance de caractères.
- Polyvalence : Compréhension multimodale.
Capacités de Réflexion Approfondie et de Simulation
Les capacités de réflexion approfondie et de simulation de Gemini 2.5 Pro sont impressionnantes. J'ai orchestré plusieurs tâches de simulation, et le modèle a résolu des problèmes complexes avec brio. Cependant, il a tendance à surpenser, et une gestion du temps est essentielle.
L'apprentissage par renforcement améliore son adaptabilité, mais demande plus de ressources. Pour des problèmes simples, des modèles plus simples peuvent être plus efficaces.
- Problèmes complexes : Résolu avec facilité.
- Apprentissage par renforcement : Améliore l'adaptabilité.
- Surpensée : Peut ralentir les tâches simples.
Implications Coût et Potentiel Futur
La haute performance de Gemini 2.5 Pro a un coût élevé—il faut prévoir un budget en conséquence. Son caractère expérimental signifie un potentiel d'améliorations futures. J'évalue constamment le rapport coût-bénéfice—parfois, un modèle moins puissant est plus rentable.
Restez à l'affût des mises à jour—Gemini 2.5 Pro évolue constamment et pourrait bien redéfinir les standards à l'avenir.
- Coût élevé : Prévoir un budget adéquat.
- Nature expérimentale : Potentiel d'amélioration.
- Évaluation constante : Surveillez les mises à jour.
Gemini 2.5 Pro est vraiment une bête sur le marché de l'IA. D'abord, il a fait une seule erreur dans une tâche de reconnaissance de caractères, ce qui montre une précision impressionnante. Ensuite, il a franchi la barre des 1443, ce qui le place au sommet de l'arène des LM. Enfin, il a surclassé d'autres modèles avec un score de 18,8 % dans un test de benchmark de Scale AI. Mais attention, son coût élevé et sa tendance à suranalyser peuvent être des pièges. Ne l'utilisez pas aveuglément, mais évaluez bien vos besoins spécifiques. Si vous êtes prêt à repousser les limites de l'IA, Gemini 2.5 Pro pourrait être l'outil qu'il vous faut. Mais souvenez-vous, parfois moins c'est plus. Regardez la vidéo "Gemini 2.5 Pro est là!" pour approfondir votre compréhension. Votre prochaine grande avancée en IA pourrait être à un clic.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Modèles StepFun AI : Efficacité et Impact Futur
J'ai plongé dans l'écosystème de StepFun AI, intrigué par ses capacités de génération de vidéo à partir de texte. En explorant ses modèles et ses métriques de performance, j'ai découvert un acteur ambitieux venu de Chine. Avec 30 milliards de paramètres et la capacité de générer jusqu'à 200 images par seconde, StepFun AI promet de secouer le paysage de l'IA. Mais attention, le modèle Step video t2v nécessite 80 Go de mémoire GPU. Comparé à d'autres modèles, il y a des compromis à considérer, mais son potentiel est indéniable. Découvrons ensemble ce qui fait la force de StepFun AI et comment il pourrait redéfinir l'industrie.

Découverte de Deep Seek R1: IA de Raisonnement
Je me suis plongé dans le modèle R1 light preview de Deep Seek, curieux de voir comment il se compare au 01 preview d'OpenAI. Et là, surprise! Je ne m'attendais pas à ce que le R1 excelle dans la résolution de problèmes mathématiques et le codage à ce point. Avec ses capacités de raisonnement, il redéfinit ce qu'on attend d'une IA. Mais attention, il y a des limites. Par exemple, le décodage en Base 64 a révélé des défis surprenants avec des hallucinations de modèle. Et puis, il y a la question de l'échelle de calcul pendant les tests qui peut vite devenir un gouffre. Pourtant, si vous cherchez à explorer le potentiel des modèles de raisonnement, le R1 est une étape incontournable. Ne le sous-estimez pas, mais soyez conscient de ses limites.
Agents Profonds avec LangChain: Introduction
J'ai passé des heures interminables dans les tranchées du développement d'IA, à jongler avec des agents profonds. Dès que j'ai découvert LangChain, c'était comme tomber sur une mine d'or. Imaginez orchestrer deux sous-agents en parallèle pour décupler l'efficacité. Je vous montre comment j'optimise et débugge ces systèmes complexes, en utilisant des outils comme Langmith Fetch et Paulie. Les agents profonds sont la colonne vertébrale des systèmes d'IA avancés, mais attention, ils viennent avec leur lot de défis. Chaque étape, de l'évaluation au débuggage, exige précision et bons outils.
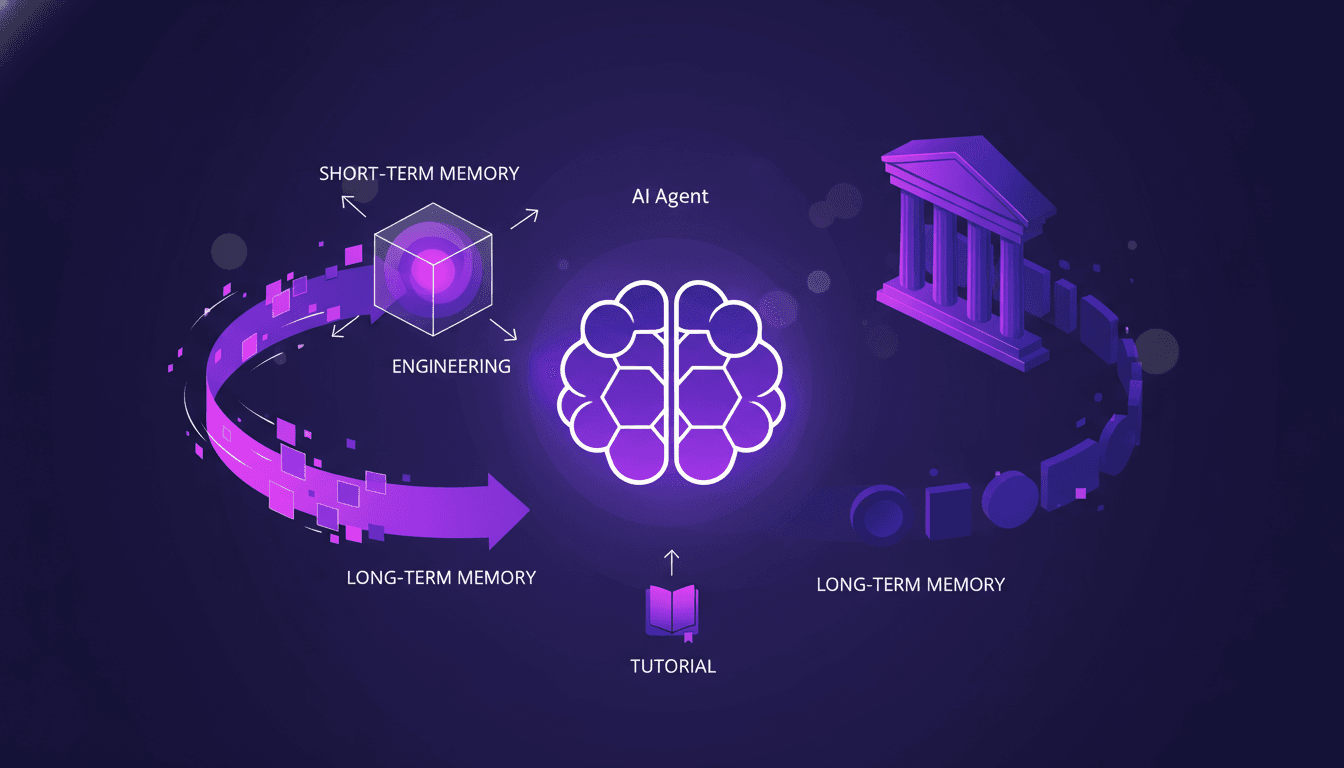
Optimiser la Mémoire des Agents IA: Techniques Avancées
J'ai passé des heures dans les tranchées avec des agents IA, à jongler avec des schémas de mémoire qui peuvent littéralement faire ou défaire votre setup. D'abord, plongeons dans ce que signifient vraiment les schémas de mémoire d'agent et pourquoi ils sont cruciaux. Dans les systèmes IA avancés, gérer la mémoire et le contexte ne se résume pas à stocker des données—c'est optimiser leur utilisation. Cet article explore les techniques et défis de la gestion du contexte, en s'appuyant sur des applications concrètes. On parle de différences entre mémoire à court et long terme, des écueils possibles, et des techniques pour une gestion efficace du contexte. Vous verrez, deux membres de notre équipe d'architecture ont vraiment creusé la question, et leurs insights pourraient changer la donne pour votre prochain projet.
Exploration AI: 10 ans de progrès, limites
Il y a dix ans, j'ai plongé dans l'IA, et les choses étaient bien différentes. On commençait à peine à gratter la surface de ce que l'apprentissage profond pouvait accomplir. Aujourd'hui, j'oriente des projets d'IA qui semblaient appartenir à la science-fiction à l'époque. Cette décennie a été marquée par des progrès fulgurants : des capacités historiques de l'IA aux percées récentes dans la prédiction de texte. Mais attention, malgré ces avancées incroyables, les défis persistent et les limites techniques demeurent. Dans cette exploration, je vous emmène à travers les expérimentations, les essais et les erreurs qui ont jalonné notre parcours, tout en regardant vers l'avenir de l'IA.