Edge AI : Avantages et Tiny LLMs en Périphérie
J'ai passé plus d'une décennie à plonger dans l'IA Edge, et laissez-moi vous dire, c'est un vrai bouleversement. Exécuter des modèles d'IA directement sur des appareils Edge n'est pas juste une tendance technologique—c'est une solution concrète aux défis du monde réel. Avec le lancement de Gemma 4 et les avancées dans les Tiny LLMs, nous assistons à un changement vers des solutions d'IA plus efficaces et fiables. En parlant de déploiement et de coût, l'IA Edge redéfinit la donne avec des gains en performance, confidentialité, et utilisation hors ligne. Pourtant, le véritable potentiel réside dans la personnalisation et l'architecture des compétences des modèles. Dans cette conférence, nous plongeons dans la structure technique nécessaire pour faire tourner l'IA sur des appareils Edge, les changements de déploiement et de licence, et comment les Tiny LLMs peuvent transformer nos approches actuelles.
Quand j'ai commencé à intégrer des modèles d'IA sur des appareils Edge, je ne réalisais pas à quel point cela allait changer la donne. Mais après plus de dix ans dans ce domaine, je peux affirmer avec certitude que c'est un tournant majeur. Exécuter des modèles d'IA directement sur des appareils Edge, c'est bien plus qu'une simple tendance technique—c'est une solution pratique à des problèmes réels comme la confidentialité et la réduction des coûts. Avec le lancement de Gemma 4 et les avancées dans les Tiny LLMs, on voit émerger des solutions d'IA plus efficaces et fiables. D'un point de vue technique, la capacité à déployer des modèles IA à l'échelle sur des appareils Edge transforme notre manière de penser la performance et l'utilisation hors ligne. Mais attention, ne sous-estimez pas les défis liés à l'infrastructure technique et à la personnalisation des compétences des modèles. Dans cette conférence, nous explorerons comment ces technologies révolutionnent notre approche actuelle, la structure nécessaire pour implémenter ces solutions et les implications des changements de déploiement et de licence.
Comprendre l'IA Edge et ses avantages
J'ai passé les dernières années à plonger tête baissée dans l'IA Edge, et je peux vous dire que c'est un véritable game changer pour plusieurs raisons. D'abord, l'un des plus grands avantages est la réduction de la latence. Traiter les données localement signifie que vous répondez presque instantanément. Imaginez une traduction vocale en direct sur votre téléphone sans jamais dépendre du cloud – c'est ce que nous avons réalisé sur le Pixel l'an dernier.
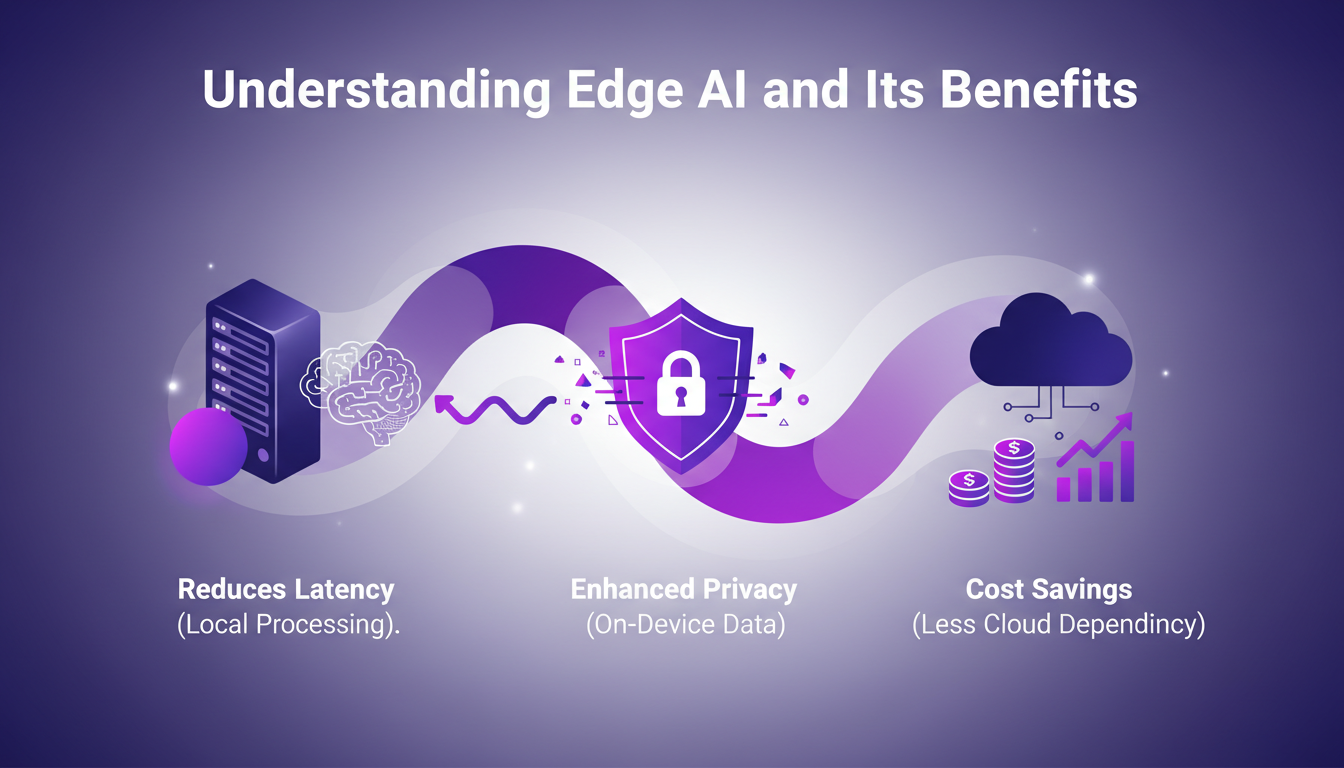
Ensuite, parlons confidentialité. Les données qui restent sur l'appareil, c'est une bénédiction pour les applications sensibles comme les messageries. Et je ne parle même pas des économies réalisées en réduisant la dépendance au cloud. Les entreprises économisent gros en minimisant les coûts de transfert et de traitement des données.
Mais attention, tout n'est pas rose avec l'IA Edge. Les appareils ont des ressources limitées, et les contraintes de puissance peuvent être un casse-tête. Cela dit, nous voyons déjà des applications réelles dans l'IoT et les appareils mobiles, là où ces limites sont gérables.
- Amélioration de la latence et de l'expérience utilisateur
- Meilleure confidentialité des données
- Réduction des coûts liés au cloud
- Applications pratiques dans l'IoT et mobile
- Défis liés aux ressources limitées
Tiny LLMs et compétences d'agent sur appareils Edge
Avec les Tiny LLMs, on entre dans une nouvelle ère d'optimisation pour les environnements à faibles ressources. J'ai souvent dû jongler entre la taille du modèle et la performance – un équilibre délicat. Les compétences d'agent permettent de personnaliser les modèles pour des tâches spécifiques, ce qui est crucial lorsque chaque milliseconde compte.
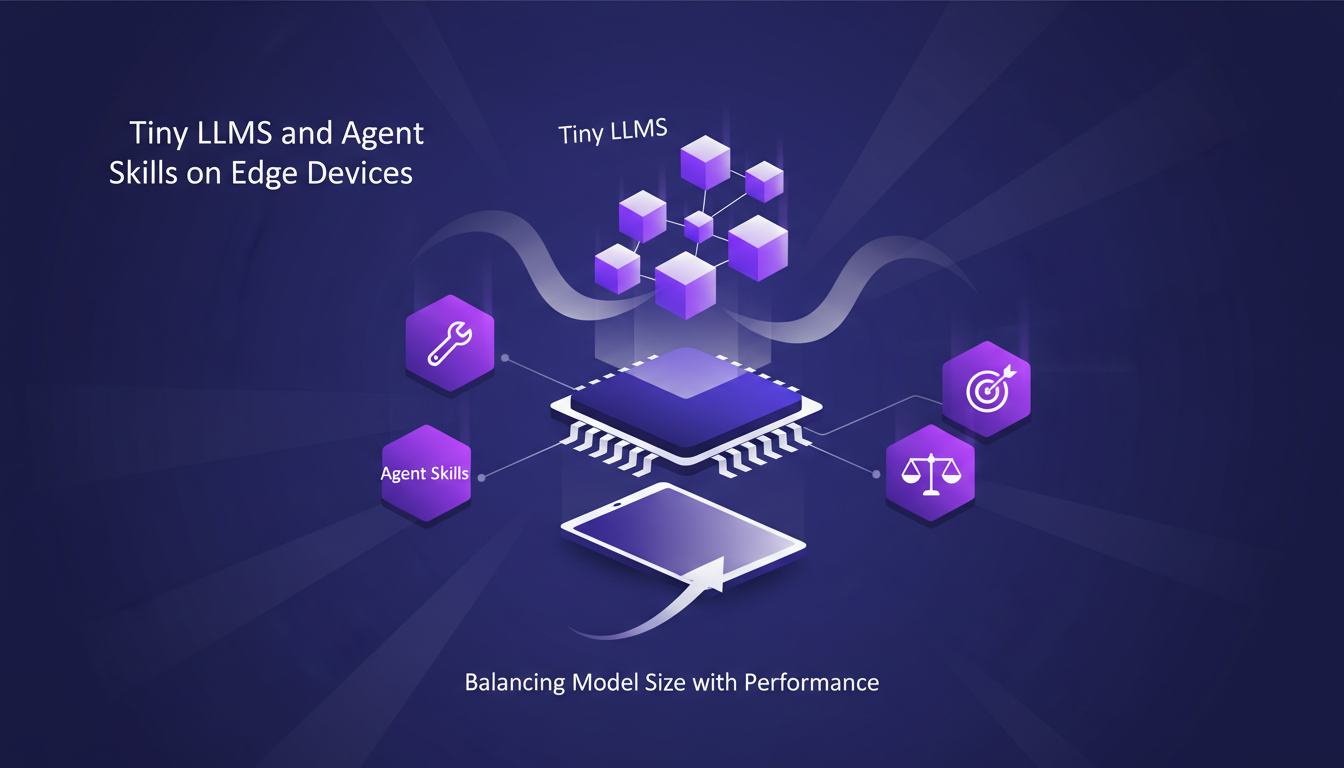
La clé est de personnaliser sans sacrifier la fiabilité. Par exemple, un modèle de 270 millions de paramètres dédié aux appels de fonction a atteint 85 à 90 % de fiabilité dans nos évaluations internes — un exploit pour un modèle aussi petit. Mais attention, les modèles de moins de 500 millions de paramètres nécessitent un fine-tuning pour atteindre une fiabilité de niveau production.
- Optimisation pour les environnements à faibles ressources
- Personnalisation des modèles pour des tâches spécifiques
- Équilibre entre taille du modèle et performance
- Fine-tuning essentiel pour la fiabilité
- Limites de complexité avec des modèles plus petits
Gemma 4 : lancement et modèles GenAI au niveau système
La semaine dernière, nous avons lancé Gemma 4, et cela marque un tournant pour les modèles d'IA générative au niveau système. Avec des modèles allant de 2 à 5 milliards de paramètres, l'accent est mis sur l'efficacité et l'évolutivité. Pour les industries qui dépendent des données en temps réel, c'est une avancée majeure.
Mais attention aux limitations de licence. Sous licence Apache 2.0, il est crucial de respecter les contraintes de déploiement. J'ai vu des implémentations échouer simplement parce que les règles de licence n'étaient pas suivies à la lettre.
- Modèles AI génératifs au niveau système
- Efficacité et évolutivité en déploiement
- Implications pour les industries en temps réel
- Stratégies de déploiement sous licence Apache 2.0
- Veille sur les limitations de licence
Infrastructure technique pour l'IA sur Edge
Quand on parle d'IA sur Edge, l'infrastructure est clé. Nous devons gérer des modèles de 100 à 500 millions de paramètres tout en optimisant la RAM et la taille des fenêtres de contexte. C'est un véritable défi, mais avec les bonnes plateformes et outils, c'est faisable.
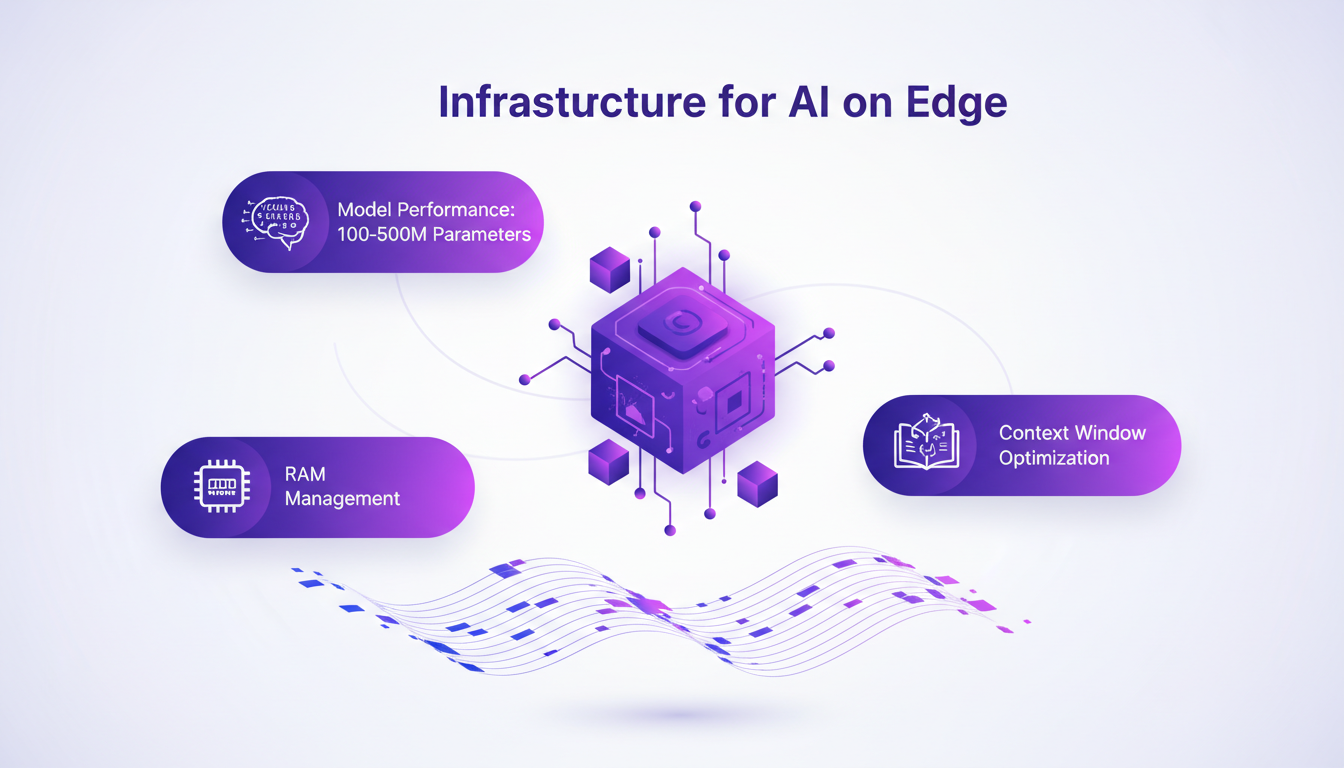
J'ai souvent utilisé des plateformes comme Dynamic Software Interfaces pour faciliter le déploiement. Mais attention aux problèmes de compatibilité des appareils et de maintenance, qui peuvent vite devenir des obstacles majeurs.
- Exigences d'infrastructure pour l'IA sur Edge
- Gestion de la performance des modèles
- Optimisation de la RAM et des fenêtres de contexte
- Outils et plateformes de support
- Pièges potentiels : compatibilité et maintenance
Architecture des compétences et personnalisation pour les modèles AI
L'architecture des compétences permet d'étendre les capacités des modèles AI, ce qui est crucial pour répondre aux besoins spécifiques des industries. Cependant, il faut savoir équilibrer personnalisation et stabilité du modèle. L'importance des mises à jour continues et du fine-tuning ne peut être sous-estimée.
J'ai vu des entreprises échouer en complexifiant trop leurs modèles sans tenir compte des performances. C'est un équilibre délicat : plus de complexité peut signifier des performances spécialisées, mais peut aussi rendre le modèle instable.
- Extension des capacités des modèles via l'architecture des compétences
- Compétences personnalisées pour des besoins industriels spécifiques
- Équilibre entre personnalisation et stabilité
- Importance des mises à jour continues
- Complexité accrue versus performance spécialisée
Avec Edge AI, l'intelligence artificielle se rapproche de là où se produit la donnée, et cela change la donne. J'ai intégré des Tiny LLMs dans nos systèmes, et voilà ce que j'ai appris :
- D'abord, pensez à la taille de modèle : avec 500 millions de paramètres, vous pouvez affiner pour une fiabilité en production. C'est le seuil critique.
- Ensuite, pour l'E2B, prévoyez 2 milliards de paramètres en RAM. Sans ça, l'efficacité tombe à l'eau.
- J'ai aussi découvert que les modèles de taille moyenne avec une fenêtre de contexte de 128K sont parfaits pour traiter des tâches complexes.
Mais attention, déployer ces modèles nécessite de jongler avec des compromis sur la confidentialité et le coût.
Le futur de l'IA est à la périphérie, et nous sommes aux premières loges. Si vous n'avez pas encore plongé, commencez petit, concentrez-vous sur vos besoins spécifiques, et itérez avec les retours du terrain. Pour une compréhension plus approfondie, je vous conseille de regarder la vidéo de Cormac Brick sur les Tiny LLMs. C'est une ressource inestimable pour quiconque veut se lancer dans l'Edge AI !
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Claude Co-work : Guide du Praticien
Je me souviens encore de la première fois où j'ai configuré Claude Co-work. C'était comme ouvrir une boîte à outils pleine de possibilités infinies. Mais soyons honnêtes, ce n'était pas un long fleuve tranquille. Après m'être embrouillé plusieurs fois, j'ai finalement orchestré la configuration, les fonctionnalités et la personnalisation de Claude Co-work pour en faire un véritable atout dans mes projets. Que vous soyez novice ou que vous ayez déjà un peu de bouteille, comprendre comment tirer le meilleur parti de cet assistant AI est crucial. On y va, je vous montre comment faire de Claude Co-work un allié redoutable.
Dipsic V4 : Révolution IA, défis OpenAI
J'ai passé des années dans les tranchées de l'IA, à observer l'évolution des modèles. Mais quand j'ai mis la main sur le Dipsic V4, j'ai su qu'on tenait quelque chose de révolutionnaire. Avec ses 1600 milliards de paramètres, ce modèle n'est pas simplement un autre outil dans le paysage; c'est un potentiel perturbateur face aux géants comme GPT 5.5 d'OpenAI. Je vais vous montrer pourquoi ce modèle fait tant de vagues et comment il redéfinit les règles du jeu. On parlera de ses caractéristiques innovantes, de sa stratégie de prix agressive, et de ce que cela signifie pour des acteurs comme Nvidia et OpenAI. Attention, ça peut changer la donne.
Récursion en IA: Révolutionner les Modèles
J'ai passé des heures à peaufiner des modèles d'IA, et franchement, la récursion est le game changer qu'on attendait. Finies les courses à plus de paramètres, place à l'intelligence. Quand les modèles traditionnels butent sur des limites, la récursion offre une perspective nouvelle. On va explorer comment elle pourrait redéfinir l'efficacité et les capacités de l'IA. On parlera de modèles de raisonnement hiérarchique, de modèles récursifs miniatures, d'apprentissage d'équilibre profond et des défis de l'optimisation. Si vous avez déjà été frustré par les murs de la scalabilité, vous allez adorer ce nouveau paradigme.
Évolution des Interfaces Logicielles Dynamiques
J'ai vu les interfaces logicielles évoluer, passant de statiques à dynamiques, et c'est fascinant. En tant qu'ingénieur déployé sur le terrain, je vois comment la personnalisation redéfinit notre façon de penser les logiciels. On ne parle plus de solutions uniques pour tous. On façonne des interfaces qui s'adaptent à chaque utilisateur grâce aux agents de codage et à une livraison logicielle repensée. C'est un vrai tournant pour l'industrie, mais attention aux limites : il faut une orchestration fine et éviter la surcharge de personnalisation qui peut embrouiller l'utilisateur. Ne vous laissez pas piéger par les vieilles méthodes, il est temps d'adopter une approche plus flexible et centrée sur l'utilisateur. Explorez avec moi comment ces transformations changent notre quotidien de développeur.

Améliorations GPT-5.5 : Performances et Précision
Je me suis retrouvé jusqu'au cou dans les défis de parsing quand GPT-5.5 est arrivé, et laissez-moi vous dire, c'est un vrai game changer. Mais attention, ce n'est pas sans quelques pièges. Dans l'environnement complexe de Databricks, la configuration stratégique est clé. Avec des améliorations de performance impressionnantes et une précision accrue, GPT-5.5 redéfinit les standards, mais il faut savoir l'apprivoiser. Je vais vous montrer comment j'ai exploité cette puissance, en passant par des techniques de parsing personnalisées et des configurations multi-agents. Préparez-vous à plonger dans les détails techniques et à découvrir comment Codex 5.5 s'impose comme le modèle ultime!