Gemma 4 : Déploiement et Optimisation
Quand Gemma 4 a débarqué, je me suis dit qu'il était temps de plonger dedans. Avec sa licence Apache 2, ce n'est pas seulement l'accès qui est en jeu, mais ce que l'on peut construire. Je vais vous emmener dans mon parcours avec Gemma 4, du déploiement à l'optimisation. Les nouvelles fonctionnalités, les capacités multi-modalité, et les innovations architecturales héritées de Gemini 3, tout y est. Mais attention, les fenêtres de contexte de 128K et les 26 milliards de paramètres nécessitent un vrai savoir-faire pour être maîtrisés. Je vous partagerai comment j'ai navigué ces eaux, de l'implémentation des modèles Gemma pour postes de travail jusqu'à l'optimisation pour les modèles edge.
Quand Gemma 4 est arrivé sur la scène, je savais que c'était le moment de m'y plonger. Avec sa licence Apache 2, ce n'est pas seulement une question d'accès, mais de ce que l'on peut réellement construire. J'ai commencé par déployer les modèles sur mes postes de travail (et là, j'ai tout de suite apprécié la capacité de fenêtre de contexte de 128K). Ensuite, j'ai jonglé avec les nouvelles capacités de multimodalité, qui m'ont permis d'intégrer des flux de données plus variés que jamais. Mais attention, les 26 milliards de paramètres du modèle de mélange d'experts ne se manipulent pas à la légère. J'ai dû affiner mes compétences en optimisation pour tirer le meilleur parti de ces innovations architecturales héritées de Gemini 3. Et franchement, la chaîne de raisonnement long est un vrai atout, mais elle nécessite des ajustements précis pour rester efficace. Si vous êtes prêt à explorer jusqu'où Gemma 4 peut vous mener, suivez-moi dans ce voyage technique.
Comprendre la Licence Apache 2 et la Sortie de Gemma 4
Déjà, parlons de la licence Apache 2. Si vous êtes dans le développement depuis un certain temps, vous savez que c'est un vrai cadeau. Avec Gemma 4, Google a décidé de faire les choses bien en l'adoptant. Pas de restrictions bizarres, pas de clauses du genre « on vous surveille ». Vous pouvez prendre le modèle, le modifier, le déployer commercialement, bref, en faire ce que vous voulez. C'est un vrai changement de jeu pour le déploiement de l'IA, surtout pour ceux qui veulent intégrer ça dans des produits à grande échelle. C'est une liberté qu'on n'a pas souvent avec des modèles aussi puissants.
"Pour la première fois, vous pouvez prendre le meilleur modèle ouvert de Google, le modifier, l'affiner, le déployer commercialement, faire ce que vous voulez avec, sans conditions."
Un autre point à ne pas négliger, c'est l'aspect open-source. Ça veut dire que la communauté peut contribuer, et ça, ça change tout. On parle de 400 millions de téléchargements pour les versions précédentes. Ça crée un écosystème riche, un vrai Gemmaverse avec plus de 100 000 variantes. Alors, si vous avez des idées novatrices, c'est le moment de les mettre en œuvre.
Multi-modalité et Niveaux de Modèles : Une Nouvelle Ère
Gemma 4 introduit des capacités de multi-modalité qui sont vraiment impressionnantes. Imaginez un modèle qui peut gérer de l'audio, de la vision, et qui a des capacités de raisonnement intégrées. On a deux niveaux de modèles ici : les modèles workstation et les modèles edge. Les premiers sont faits pour des environnements lourds, avec un modèle dense de 31 milliards de paramètres et un modèle de mélange d'experts (MoE) de 26 milliards de paramètres avec 4 milliards actifs. Les modèles edge, eux, sont optimisés pour des appareils comme les téléphones et les Raspberry Pis. C'est une flexibilité qui permet de répondre à des besoins très variés.
Ce qui est fascinant, c'est la capacité à raisonner sur de longues chaînes de pensée, pas seulement en texte, mais aussi en images et en audio. Ça change la donne quand on pense aux applications pratiques, que ce soit pour de la reconnaissance optique de caractères ou des assistants vocaux intelligents.
Innovations Architecturales : De Gemini 3 à Gemma 4
Alors là, c'est le moment de passer aux choses sérieuses avec les innovations architecturales. Gemma 4 reprend les recherches de Gemini 3, mais en mieux. On parle d'un modèle dense de 31 milliards de paramètres, c'est énorme. Mais ce qui est vraiment bluffant, c'est l'efficacité qu'on a pu extraire de l'encodage audio et vision. Les paramètres de l'encodeur audio ont été réduits de 50%, ce qui libère 303 mégaoctets sur disque. Les nouveaux encodeurs de vision, eux, passent à 150 millions de paramètres, contre 300-350 millions auparavant. C'est un gain de place qui permet de garder les performances sans exploser les ressources.
Ces améliorations permettent à Gemma 4 d'être non seulement plus performant en termes de calcul mais aussi plus léger, ce qui est crucial pour les déploiements sur le terrain. Et avec un support intégré pour l'appel de fonctions, on peut orchestrer des flux d'agents multi-tournures plus efficacement que jamais.
Support Linguistique Amélioré et Fenêtres de Contexte
Gemma 4 a aussi étendu son support linguistique à 140 langues pour l'entraînement, ce qui ouvre des portes énormes pour les applications globales. Et la fenêtre de contexte ? Elle atteint maintenant 128K pour les plus petits modèles, ce qui est un vrai plus pour le traitement de texte et la compréhension de contexte complexe. Imaginez la différence dans des applications comme la traduction en temps réel, où la compréhension du contexte est essentielle.
En ayant une fenêtre de contexte plus large, les modèles peuvent faire du raisonnement de manière plus efficace, ce qui est crucial pour des tâches nécessitant une compréhension approfondie du texte en entrée. Ce n’est pas juste un gadget, c’est une avancée qui a un impact direct sur les performances.
Déploiement et Ajustement des Modèles Gemma 4
Finalement, parlons du déploiement et de l'ajustement. Pour tirer le meilleur de Gemma 4, il faut comprendre les subtilités du Quantized Aware Training (QAT). Cela permet d’optimiser les performances tout en maintenant une précision élevée. Mais attention, il y a des compromis à faire. Parfois, il vaut mieux ne pas abuser des ajustements pour ne pas dégrader les performances. Le processus de déploiement est assez direct mais nécessite quelques étapes de configuration des modèles pour le fine-tuning.
Le déploiement sur des plateformes comme Google Cloud ou Hugging Face est un choix judicieux. Mais gardez en tête que chaque configuration a ses spécificités. Par exemple les modèles plus petits fonctionnent bien sur des T4 GPUs, tandis que les plus grands bénéficient de la prise en charge serverless via Cloud Run. N'oubliez pas de tester vos configurations pour éviter les surprises. Et si vous cherchez à comparer les coûts et performances, jetez un œil à notre article sur le GPT 5.4 Mini.
En conclusion, Gemma 4 est une avancée majeure pour les développeurs cherchant à déployer des solutions IA performantes et flexibles. Mais comme toujours, il est essentiel de bien comprendre les outils avant de les appliquer à grande échelle.
Avec Gemma 4, on ne parle pas simplement d'une mise à jour, mais d'une véritable boîte à outils pour l'innovation. D'abord, ses capacités multi-modales changent vraiment la donne. Imaginez un contexte de 128K pour les modèles plus petits - c'est immense pour l'agilité et l'optimisation. Ensuite, les 26 milliards de paramètres dans le modèle 'mixture of experts' ouvrent des portes à des performances que je n'avais pas encore vues. Mais, attention, avec toute cette puissance vient la nécessité d'une orchestration soignée - c'est facile de se perdre dans les détails.
Prenez ça comme une invitation à explorer ces nouvelles possibilités. Déployez Gemma 4 et voyez par vous-même comment vos capacités IA s'élargissent.
Pour ceux qui veulent aller plus loin, je vous encourage vivement à regarder la vidéo "Gemma 4 Has Landed!" sur YouTube pour vraiment saisir l'ampleur des innovations. C'est crucial pour comprendre comment tout orchestrer au mieux.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
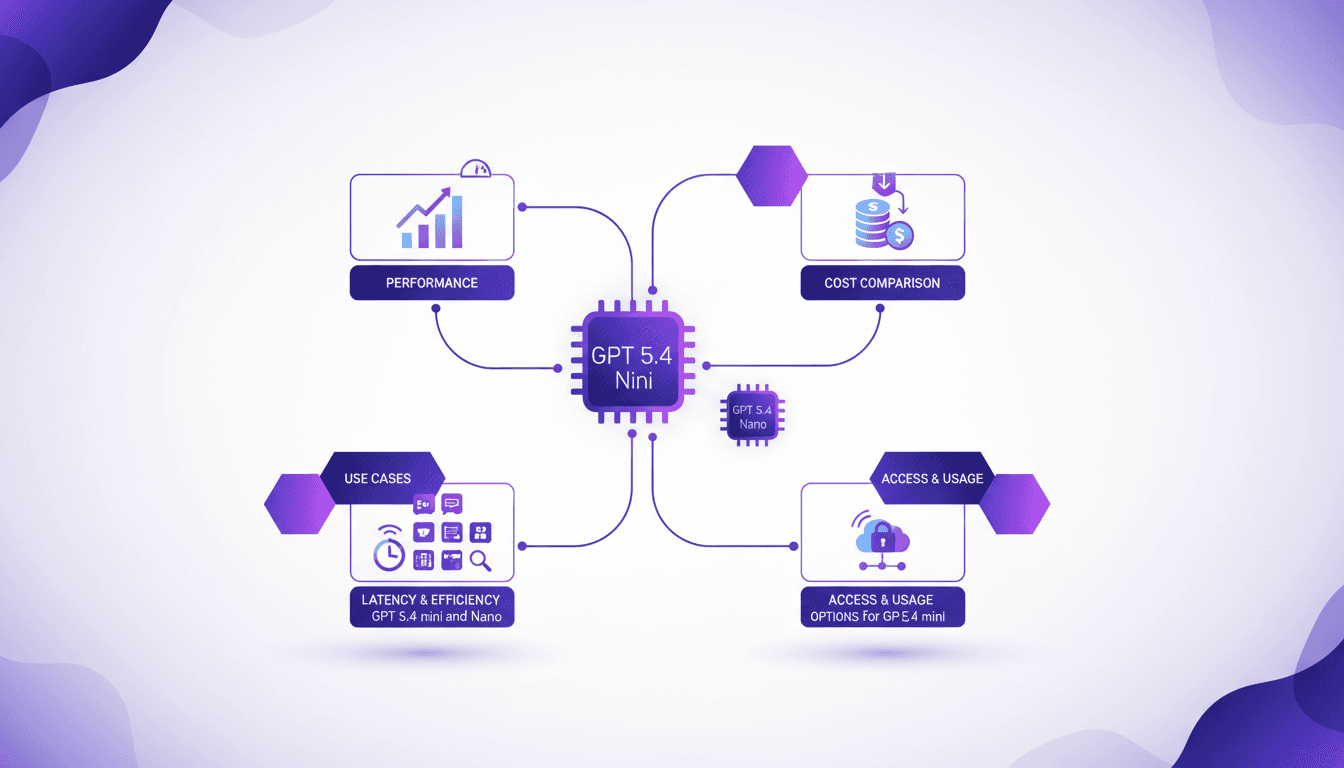
GPT 5.4 Mini : Performance et Coût Comparé
Je plonge tête baissée dans les modèles GPT 5.4 Mini et Nano, et ces versions sont de véritables game changers. Mais attention, il y a des compromis à gérer. Avec l'évolution rapide des modèles d'IA, la série GPT 5.4 propose des options intrigantes pour les développeurs cherchant à équilibrer performance et coût. D'abord, j'ai configuré le Mini pour voir comment il se compare. Ses scores de 54,4 % en performance montrent qu'il tient la route, surtout quand on pense au coût réduit. Ensuite, j'ai testé le Nano, qui affiche 52,5 %. Idéal pour les applications où chaque milliseconde compte. Mais attention aux latences. On verra comment ces modèles peuvent s'intégrer dans vos workflows et surtout, où ils se démarquent vraiment par rapport à la concurrence.

AI en Vente: Pourquoi l'IA Dépasse les Humains
J'ai passé plus d'une décennie dans la vente, jonglant avec des détails clients jusqu'à ce que l'IA transforme complètement mon approche. Imaginez, je pouvais garder en tête quatre informations à la fois, mais l'IA, elle, peut en gérer des milliers. C'est un véritable game changer. Dans cet article, je vais vous montrer comment les capacités cognitives de l'IA et son exécution précise transforment les stratégies de vente, tirant de mes expériences et d'experts du secteur. On va explorer ensemble les contraintes cognitives humaines face à l'IA, la mémoire de l'IA, et sa capacité à traiter les nuances du langage.
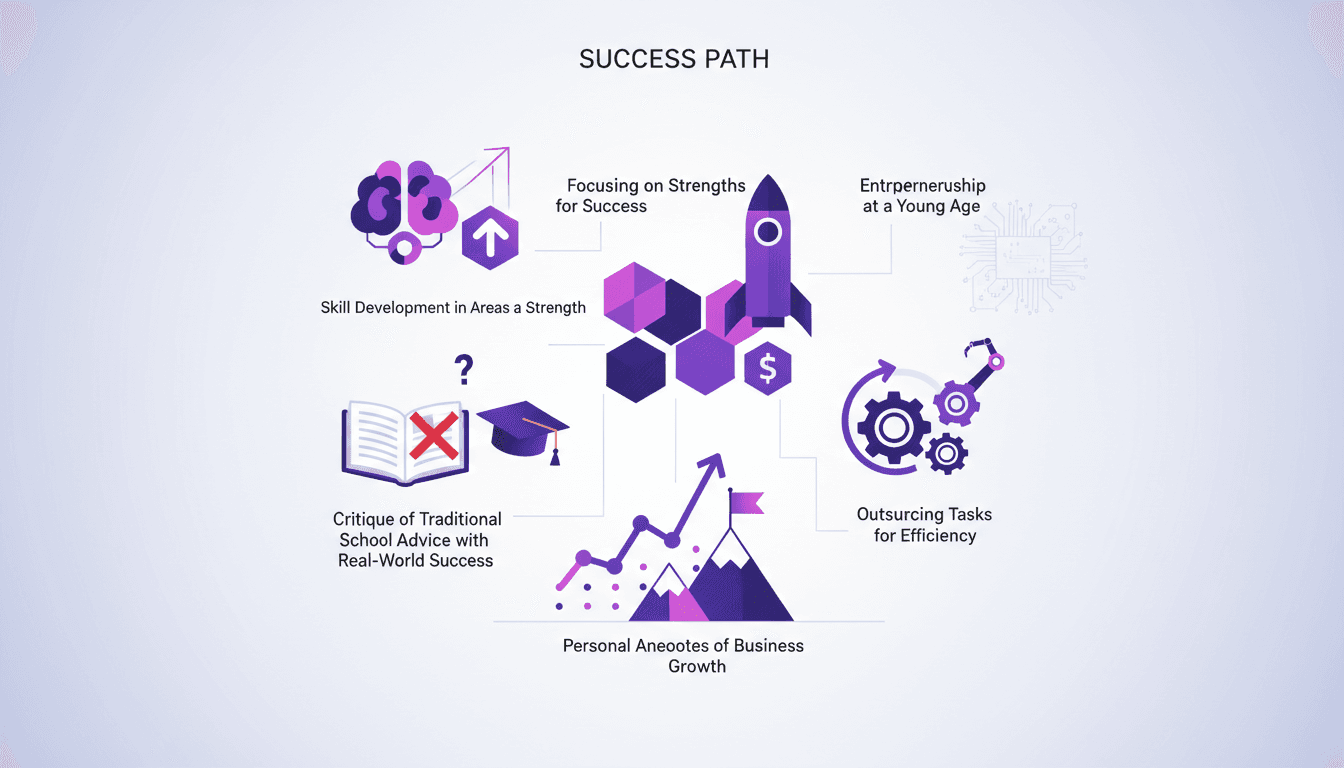
Concentrez-vous sur vos forces : Stratégies gagnantes
À 15 ans, j'ai lancé ma première entreprise. Tandis que l'école me notait sur mes faiblesses, j'ai décidé de me concentrer sur ce que je faisais de mieux. Cette décision a été un véritable game changer. Dans le monde réel, miser sur ses forces peut transformer votre parcours. Je vais vous montrer comment l'entrepreneuriat et l'externalisation peuvent booster votre efficacité. Vous allez apprendre à développer vos compétences là où elles comptent vraiment, et pourquoi les conseils scolaires traditionnels peuvent vous freiner.
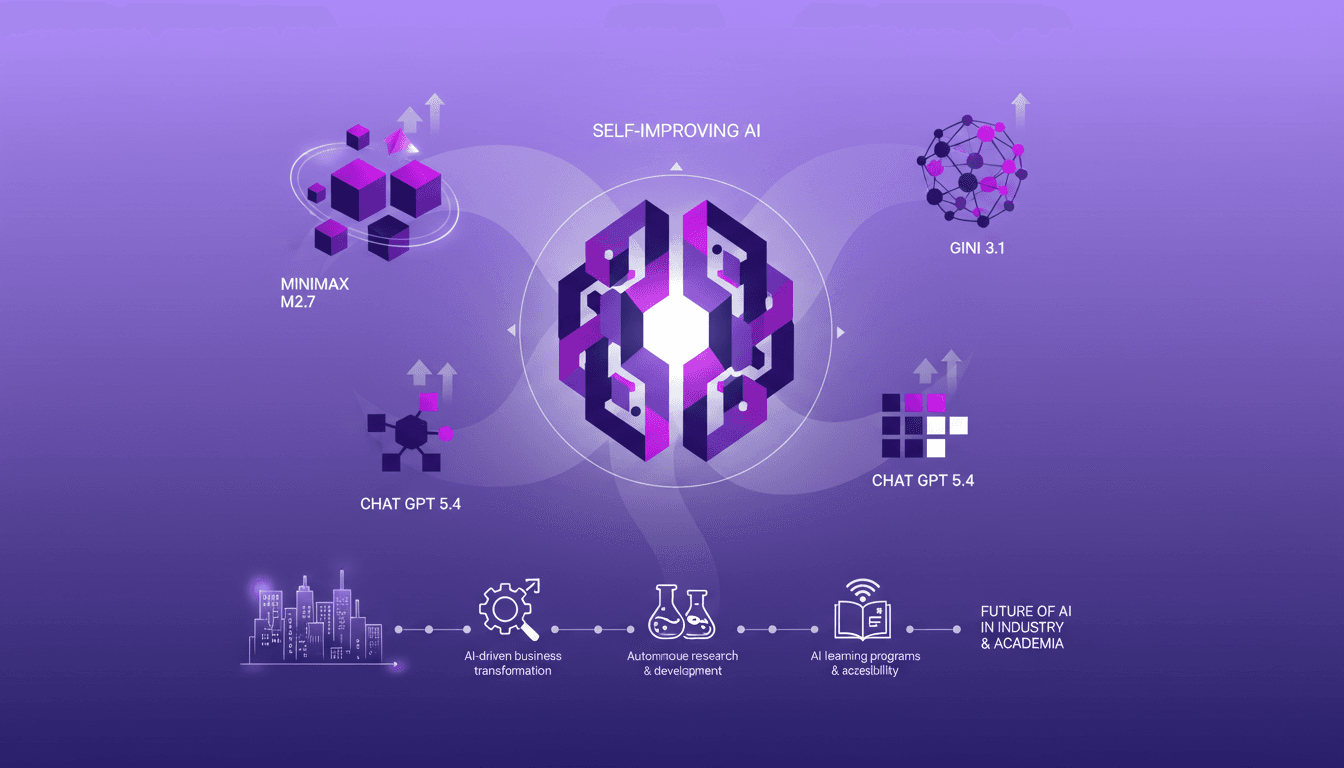
Modèles IA auto-améliorants : Révolution ou Risque ?
Je suis plongé dans le développement de l'IA depuis longtemps, et croyez-moi, les modèles auto-améliorants comme le M2.7 de Minimax bouleversent tout. D'abord sceptique, j'ai pourtant intégré M2.7 dans nos flux de travail, et l'impact est indéniable. Ces modèles ne se contentent pas de changer la donne, ils redéfinissent les règles du jeu. Alors que l'industrie de l'IA est en effervescence, comment ces modèles se comportent-ils vraiment dans des applications concrètes ? On va explorer cela ensemble, en comparant avec d'autres modèles comme le Gini 3.1 et le Chat GPT 5.4, et en analysant leur rôle dans la transformation des entreprises.
Construire des relations durables avec acheteurs
Je ne me contente plus d'envoyer des offres aux acheteurs. Maintenant, je construis des relations solides et je comprends leurs objectifs. Ce changement a transformé ma façon d'aborder les ventes. Dans l'immobilier, il est facile de se perdre dans les chiffres et les transactions. Mais j'ai découvert que le véritable succès réside dans la compréhension des besoins des acheteurs et l'utilisation de l'IA pour améliorer nos tactiques de vente. En passant moins de temps à pousser des offres et plus à écouter, j'ai pu forger des relations à long terme qui apportent une réelle valeur. Si vous voulez vraiment percer dans ce domaine, il est temps de repenser votre stratégie. Plutôt que d'envoyer des deals, connectez-vous avec vos clients et mettez en avant leurs besoins. Vous verrez, l'impact sur vos ventes sera significatif.