Voice Cloning: Efficient Model for Commercial Use
I dove into voice cloning out of necessity—clients needed unique voiceovers without the hassle of endless recording sessions. That's when I stumbled upon this voice cloning model. First thing I did? Put it against Eleven Labs to see if it could hold its ground. Voice cloning isn't just about mimicking tones—it's about creating a scalable solution for commercial applications. In this article, I'll take you behind the scenes of this model: where it shines, where it falters, and the limitations you need to watch out for. If you've dabbled in voice cloning before, you know technical specs and legal considerations are crucial. I’ll walk you through the model's nuances, its commercial potential, and how it really stacks up against Eleven Labs.

I dove into voice cloning out of necessity—clients needed unique voiceovers without the hassle of endless recording sessions. That's when I stumbled upon this voice cloning model. First thing I did? Put it against Eleven Labs to see if it could hold its ground. Voice cloning isn't just about mimicking tones—it's about creating a scalable solution for commercial applications. If you're like me, a practitioner looking to optimize workflows, this article is for you. I'll walk you through the technical specs, highlight the strengths, and point out the pitfalls to avoid. Have you considered commercial licensing? Or how to handle accent and language support? Be careful, because beyond a certain point, the model's limits become apparent, and that's where you might get burned. So come along and let's see how this model really stacks up against Eleven Labs.
Voice Cloning Model Overview
I recently got hands-on with a voice cloning model that might just be a game changer for industry professionals. First off, we're talking about a model with 500 million parameters, licensed under the MIT License, which means you can commercially exploit it without endless legal headaches. Unlike traditional text-to-speech systems, this model excels in voice cloning. I was struck by the depth and naturalness of the generated voices, even compared to already established solutions. I got burned a few times by how closely it resembles real voices.
This model doesn't just read text; it mimics the vocal nuances of a given person. If you've ever used tools like Eleven Labs, you'll be interested to know that in a survey, 31 out of 50 people preferred this model over Eleven Labs.
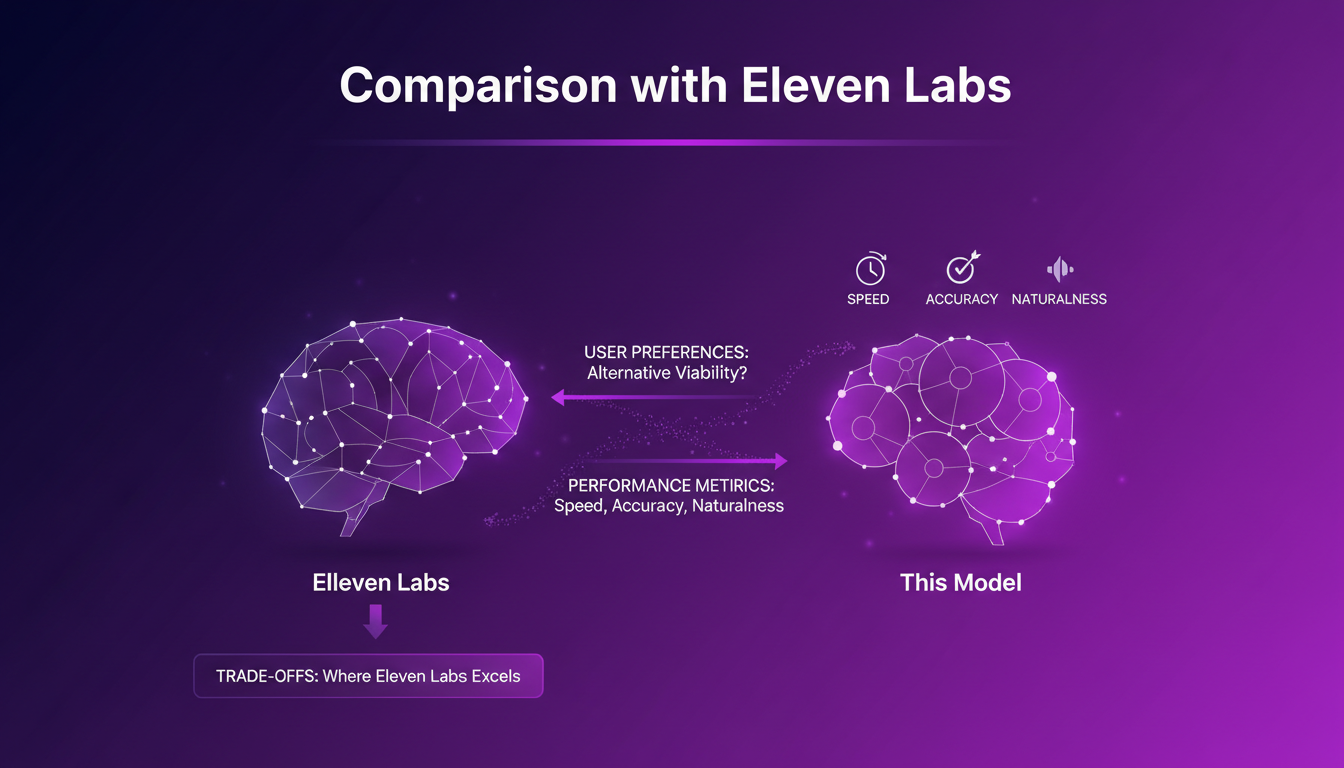
Comparison with Eleven Labs
Exploring user preferences, I found that this model is often chosen for its speed and accuracy. While Eleven Labs has its qualities, notably in intonation and emotion, this model steps up with sound quality and fluidity that really impressed me. The sound generation time is faster on the configurations I tested.
Here's a snapshot of the comparisons:
| Criterion | Voice Cloning Model | Eleven Labs |
|---|---|---|
| Speed | 8 seconds for a 12-second clip | Variable |
| Accuracy | Very accurate | Good |
| Naturalness | High | High |
Despite its advantages, Eleven Labs retains an edge in some emotional aspects, but that's a matter of personal preference in my view.
Technical Specifications and Parameters
Now, let's dive into the technical details. This model uses Classifier Free Guidance (CFG), a key parameter that steers voice generation without a classifier. By adjusting this parameter, I was able to influence the model's expressiveness, which is crucial for more dynamic voices. Watch out, though, excessive exaggeration can lead to instability. I got burned by pushing certain parameters too far, resulting in distorted sound.
To optimize voice profiles, I iteratively tuned the settings:
- Start with moderate CFG values to test stability.
- Gradually adjust exaggeration for more expressiveness.
- Avoid pushing beyond 0.8 if you don't want to risk quality degradation.
Accent and Language Support
This model is not only versatile in terms of accents, but it also handles multiple languages with impressive efficiency. I've tested with English, French, and even Spanish voices, and the quality remains consistent. However, I've noticed that some more exotic accents can lack refinement. This is where the model shows its limits, but in most common use cases, it works very well.

For a client, I orchestrated a multilingual advertising campaign that received positive feedback, thanks notably to this linguistic flexibility.
Model Training, Data Sourcing, and Legal Considerations
The model was trained on 500 million hours of cleaned data. It sounds colossal, and it is. This means there's a vast database fueling every vocal nuance. However, it's crucial to be mindful of the legal aspects, particularly watermarking outputs to avoid copyright issues. I strongly advise following these practices to protect your work.
Regarding the license, commercial use is facilitated by the MIT license, but be vigilant about the legal implications in your specific sector.
In summary, this voice cloning model represents a significant advancement for content creators and businesses looking to integrate more natural and precise voice solutions. However, mastering the parameters and understanding the legal restrictions are essential to getting the most out of it.
Navigating the world of voice cloning isn't just about tech specs; it's about finding the tool that fits your workflow and meets your clients' needs. I tried this model as a robust alternative to Eleven Labs, but watch out, every tool has its quirks. Key takeaways:
- 500 million hours of cleaned data speak to the power behind this model.
- Compared to the 11 labs I've used before, this one brings interesting nuances.
- A small caveat, the commercial licensing can be a bit tricky to navigate.
Looking ahead, this voice cloning model could really change the game for our audio projects, but let's stay alert to the technical parameter limits.
Ready to test it yourself? Dive in, tweak those parameters, and see how it transforms your projects. Share your experiences and let's refine our workflows together. For a deeper understanding, I encourage you to watch the full video here: YouTube link.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
Kokoro TTS: The New King of Text-to-Speech
I stumbled upon Kokoro TTS while searching for a robust, cost-effective Text-to-Speech solution. Unlike the overhyped options that drain your budget, Kokoro offers a refreshing alternative with its Apache 2.0 license. In this comparison with 11 Labs, I explain why Kokoro might be your next go-to tool. With 10 unique voice packs and an impressive ranking on the Hugging Face TTS Arena leaderboard, Kokoro doesn't just promise—it delivers. I dive into its technical specs, use cases, and implementation ease to show you how to integrate it effectively into your projects.

Kokoro TTS: Leading Open Source Text-to-Speech
I stumbled upon Kokoro TTS while hunting for a free alternative to pricey text-to-speech solutions like ElevenLabs. This open-source model isn't just a knockoff; it’s a genuine game changer in the TTS landscape. Packed with 82 billion parameters and an Apache 2.0 license, it's ideal for commercial applications. I compare its performance with ElevenLabs, especially in emotional expressiveness and pronunciation accuracy. You can easily integrate it into your projects thanks to its user-friendly nature and unique voice packs. Join me as we explore how this model can transform your audio applications.
Manus AI: Reinventing Automation and Creativity
I dove into Manus AI, expecting just another tool, but it turned my workflow upside down. From coding games to planning trips, this AI agent is a real game changer. Developed by Meta GPT, it offers zero-shot task completion that cuts through the hype. I'm here to show you how I've integrated it into my daily projects. But watch out, you need to know its limits and orchestrate it effectively. And then there's Open Manis, the open-source alternative, which has already garnered 8,000 stars on its repo. Ready to discover what Manus can really do?
StepFun AI Models: Efficiency and Future Impact
I dove into StepFun AI's ecosystem, curious about its text-to-video capabilities. Navigating through its models and performance metrics, I uncovered a bold contender from China. With 30 billion parameters and the ability to generate up to 200 frames per second, StepFun AI promises to shake up the AI landscape. But watch out, the Step video t2v model demands 80 GB of GPU memory. Compared to other models, there are trade-offs to consider, yet its potential is undeniable. Let's explore what makes StepFun AI tick and how it might redefine the industry.

Turn Any Folder into LLM Knowledge Fast
Ever stared at a mountain of code wishing you could just snap your fingers and make it intelligible? That's where Code to Prompt comes in. I've been there, and here's how I made it work. We're diving into transforming GitHub repositories into LLM-friendly text using this tool, and leveraging the Google Gemini model. It's about making your codebases not just readable, but actionable. I'll guide you through integrating Code to Prompt, optimizing token management, and deploying projects with Gradio code. It's a real game changer, but watch out for token limits.