Deploying and Optimizing Gemma 4
When Gemma 4 landed, I knew it was time to dive in. With its Apache 2 license, it's not just about access but what you can build. Let me walk you through my journey with Gemma 4, from deployment to fine-tuning. The new features, multi-modality capabilities, and architectural innovations from Gemini 3 are all here. But watch out, those 128K context windows and 26 billion parameters require real expertise to master. I'll share how I navigated these waters, from deploying Gemma models for workstations to optimizing for edge models.
When Gemma 4 hit the scene, I knew it was time to dive in. With its Apache 2 license, it's not just about access; it's about what you can truly build. I started by deploying the models on my workstations (and there, I immediately appreciated the 128K context window capability). Then, I juggled the new multi-modality capabilities, which allowed me to integrate more varied data streams than ever before. But watch out, the 26 billion parameters in the mixture of experts model are not to be handled lightly. I had to sharpen my optimization skills to make the most of these architectural innovations inherited from Gemini 3. And honestly, the long chain of thought reasoning is a real asset, but it requires precise adjustments to remain effective. If you're ready to explore how far Gemma 4 can take you, join me in this technical journey.
Understanding the Apache 2 License and Gemma 4's Release
First off, let's talk about the Apache 2 license. If you've been in development for a while, you know it's a real gift. With Gemma 4, Google decided to do things right by adopting it. No weird restrictions, no "we're watching you" clauses. You can take the model, modify it, deploy it commercially, basically do whatever you want with it. It's a real game-changer for AI deployment, especially for those looking to integrate this into large-scale products. It's a freedom we don't often get with such powerful models.
"For the first time, you can take Google's best open model, modify it, fine-tune it, deploy it commercially, do whatever you want with it, no strings attached."
Another point not to overlook is the open-source aspect. It means the community can contribute, and that changes everything. We're talking about 400 million downloads for previous versions. It creates a rich ecosystem, a real Gemmaverse with over 100,000 variants. So, if you have innovative ideas, now's the time to implement them.
Multi-modality and Model Tiers: A New Era
Gemma 4 introduces multi-modality capabilities that are truly impressive. Imagine a model that can handle audio, vision, and has built-in reasoning capabilities. We have two model tiers here: workstation models and edge models. The former are made for heavy environments, featuring a 31 billion parameter dense model and a 26 billion parameter mixture of experts (MoE) model with 4 billion active. The edge models, on the other hand, are optimized for devices like phones and Raspberry Pis. It's flexibility that allows you to meet a wide range of needs.
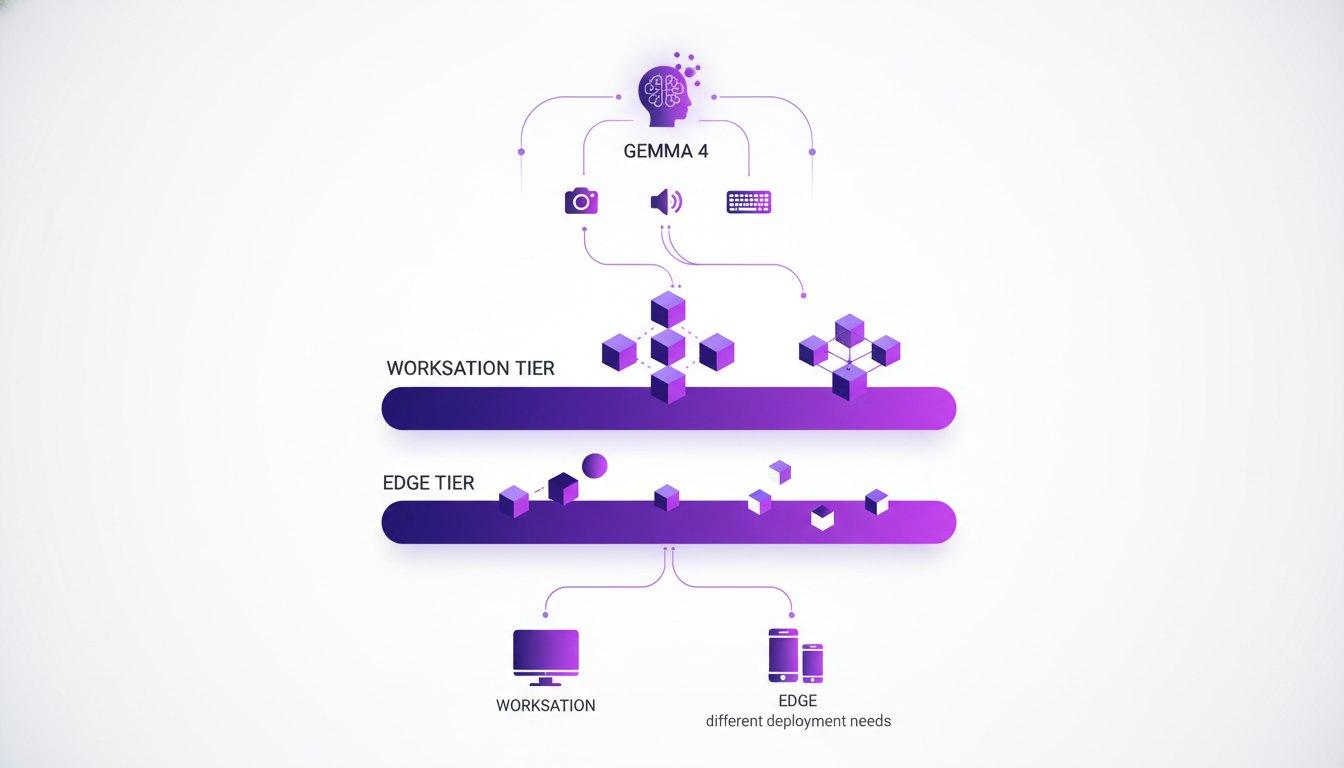
What's fascinating is the ability to reason on long chains of thought, not just in text but also in images and audio. It changes the game when you think about practical applications, whether for optical character recognition or intelligent voice assistants.
Architectural Innovations: From Gemini 3 to Gemma 4
Now, let's get to the serious stuff with architectural innovations. Gemma 4 carries over Gemini 3 research, but better. We're talking about a 31 billion parameter dense model, that's huge. But what's really impressive is the efficiency we've extracted from audio and vision encoding. Audio encoder parameters have been reduced by 50%, freeing up 303 megabytes of disk space. The new vision encoders, meanwhile, drop down to 150 million parameters, from 300-350 million previously. It's a space-saving move that keeps performance without exploding resources.
These improvements allow Gemma 4 to be not only more computationally powerful but also lighter, which is crucial for field deployments. And with integrated function calling support, orchestrating multi-turn agentic flows is more efficient than ever.
Enhanced Language Support and Context Windows
Gemma 4 has also expanded its language support to 140 languages for training, which opens huge doors for global applications. And the context window? It now reaches 128K for smaller models, which is a real plus for text processing and understanding complex context. Imagine the difference in applications like real-time translation, where understanding context is essential.
With a larger context window, models can reason more effectively, which is crucial for tasks that require a deep understanding of the input text. It's not just a gimmick, it's an advancement that has a direct impact on performance.
Deploying and Fine-tuning Gemma 4 Models
Finally, let's talk about deployment and fine-tuning. To get the most out of Gemma 4, you need to understand the subtleties of Quantized Aware Training (QAT). It allows for optimizing performance while maintaining high precision. But watch out, there are trade-offs to be made. Sometimes it's better not to overdo adjustments to avoid degrading performance. The deployment process is quite straightforward but requires a few model configuration steps for fine-tuning.
Deployment on platforms like Google Cloud or Hugging Face is a wise choice. But keep in mind that each configuration has its specifics. For instance, smaller models work well on T4 GPUs, while larger ones benefit from serverless support via Cloud Run. Don't forget to test your configurations to avoid surprises. And if you're looking to compare costs and performance, check out our article on GPT 5.4 Mini.
In conclusion, Gemma 4 is a major advancement for developers looking to deploy high-performance, flexible AI solutions. But as always, it's essential to fully understand the tools before applying them on a large scale.
Gemma 4 isn't just an update, it's a toolkit for real innovation. First, its multi-modality capabilities are a game changer. Imagine a 128K context window for the smaller models — that's massive for agility and optimization. Then, the 26 billion total parameters in the mixture of experts model open doors to performance levels I hadn't seen before. But remember, with such power comes the need for careful orchestration — it's easy to get lost in the details.
Consider this an invitation to dive into these new possibilities. Deploy Gemma 4 and watch your AI capabilities expand.
For those looking to go deeper, I strongly encourage you to watch the "Gemma 4 Has Landed!" video on YouTube to truly grasp the scope of innovations. It's crucial to understanding how to best orchestrate everything.
Frequently Asked Questions

Thibault Le Balier
Co-fondateur & CTO
Coming from the tech startup ecosystem, Thibault has developed expertise in AI solution architecture that he now puts at the service of large companies (Atos, BNP Paribas, beta.gouv). He works on two axes: mastering AI deployments (local LLMs, MCP security) and optimizing inference costs (offloading, compression, token management).
Related Articles
Discover more articles on similar topics
GPT 5.4 Mini: Performance and Cost Compared
I've been diving into the GPT 5.4 Mini and Nano models—talk about game changers. But, like always, there are trade-offs. With AI models evolving fast, the GPT 5.4 series offers intriguing options for devs who need to balance performance and cost. First, I set up the Mini to get a feel for its performance. Scoring 54.4%, it holds its own, especially considering the lower cost. Then I tested the Nano, which comes in at 52.5%. It's perfect for apps where every millisecond counts. But watch out for latency. We'll dive into how these models can fit into your workflows, and especially, where they truly stand out against competitors.

AI in Sales: Why AI Beats Humans
I've been in sales for over a decade, juggling client details until AI completely redefined my approach. Picture this: I could hold four things in my head, but AI can manage thousands. It's been a real game changer. In this article, I'll walk you through how AI's cognitive capabilities and precision execution are transforming sales strategies, drawing from my own experiences and industry experts' insights. We'll dive into the cognitive constraints of humans versus AI, AI's memory capacity, and its knack for language nuances.
Focus on Strengths: Winning Strategies
At 15, I launched my first company. While school focused on what I lacked, I chose to hone what I excelled at. This mindset shift was a game changer. In the real world, leveraging your strengths can redefine your path. I'll show you how embracing entrepreneurship and outsourcing can skyrocket your efficiency. You'll learn to develop skills where they truly matter, and why traditional school advice might actually hold you back.
Self-Improving AI Models: Revolution or Risk?
I've been on the front lines of AI development, and let me tell you, self-improving AI models like Minimax's M2.7 are shaking things up. Initially skeptical, I integrated M2.7 into our workflows, and the impact was undeniable. These models aren't just changing the game; they're redefining the rules. As the AI industry buzzes with excitement, how do these models really stack up in practical applications? We're diving into this, comparing them to other models like Gini 3.1 and Chat GPT 5.4, and analyzing their role in transforming businesses.
Building Lasting Buyer Relationships in Sales
I’ve stopped just sending deals to buyers. Now, I build strong relationships and truly understand their goals. This shift has transformed how I approach sales. In real estate, it’s easy to get lost in numbers and transactions. But I’ve found that real success comes from understanding buyer needs and leveraging AI to enhance our sales tactics. By spending less time pushing deals and more time listening, I’ve forged long-term relationships that deliver real value. If you really want to make it in this field, it's time to rethink your strategy. Instead of sending deals, connect with your clients and prioritize their needs. You’ll see, the impact on your sales will be significant.