Optimisation des LLMs: RLVR et API OpenAI
Je suis plongé jusqu'au cou dans l'affinage des modèles de langage (LLMs) grâce à l'apprentissage par renforcement via des récompenses vérifiables (RLVR). Pas de théorie ici, juste des jeux d'efficacité et de coûts, avec l'API RFT d'OpenAI comme principal outil. Dans cette vidéo, je vous montre comment je m'y prends. On va plonger dans le processus de formation, s'attaquer aux données déséquilibrées et comparer les méthodes d'affinage, tout en gardant un œil sur les coûts. C'est notre troisième épisode sur l'apprentissage par renforcement avec les LLMs, et on va aussi parler des alternatives à l'API d'OpenAI. Petit avertissement : à 100 dollars de l'heure, ça grimpe vite !
Quand j'ai commencé à affiner des modèles de langage massifs (LLMs) avec l'apprentissage par renforcement via des récompenses vérifiables (RLVR), j'étais loin de me douter du défi. Pas juste une question de théorie, mais de coûts et d'efficacité, surtout quand on utilise l'API RFT d'OpenAI. Je vous emmène dans les coulisses de mon processus : ça commence par la préparation des données (souvent déséquilibrées, ce qui complique tout), puis vient la comparaison entre les méthodes d'affinage supervisées et par renforcement. Attention aux pièges, parce qu'à 100 dollars de l'heure, l'erreur coûte cher. Dans cette troisième vidéo de notre série, je vous montre aussi quelques alternatives à l'API d'OpenAI. C'est un vrai parcours, mais une fois qu'on sait où regarder et comment ajuster, les résultats peuvent être spectaculaires. Suivez-moi, et je vous montre comment je fais.
Comprendre le RLVR dans les LLMs
Je vais être franc : quand on parle de renforcement learning (RL), on parle d’adaptation et de prise de décision intelligente. Les modèles de langage (LLMs) se nourrissent de ce concept pour s'améliorer en testant différentes solutions. La nouveauté ici, c'est le Reinforcement Learning via Verifiable Rewards (RLVR). Plutôt que de se baser uniquement sur des feedbacks humains ou des approximations, le RLVR utilise des récompenses vérifiables pour guider les LLMs vers des résultats concrets.
"Le RLVR ne forme pas simplement le modèle à générer de bonnes réponses, mais à atteindre des résultats."
Pourquoi cela importe-t-il? Parce que cela permet de structurer les sorties de manière cohérente. On peut ainsi améliorer les processus de décision adaptatifs des LLMs. Mais attention, trop de RLVR peut mener à un sur-ajustement. J'ai vu des modèles devenir trop rigides, perdant cette flexibilité qui fait leur force.
Processus de Formation : Préparation et Formatage des Données
Quand je commence un projet de formation, la première étape est toujours la division des données. On commence par un découpage en cinq étapes, très méthodique. D'abord, 80 % des données pour les exemples normaux et 20 % pour les anomalies. C'est un équilibre crucial pour obtenir une performance RLVR optimale. Ensuite, on formate les données.
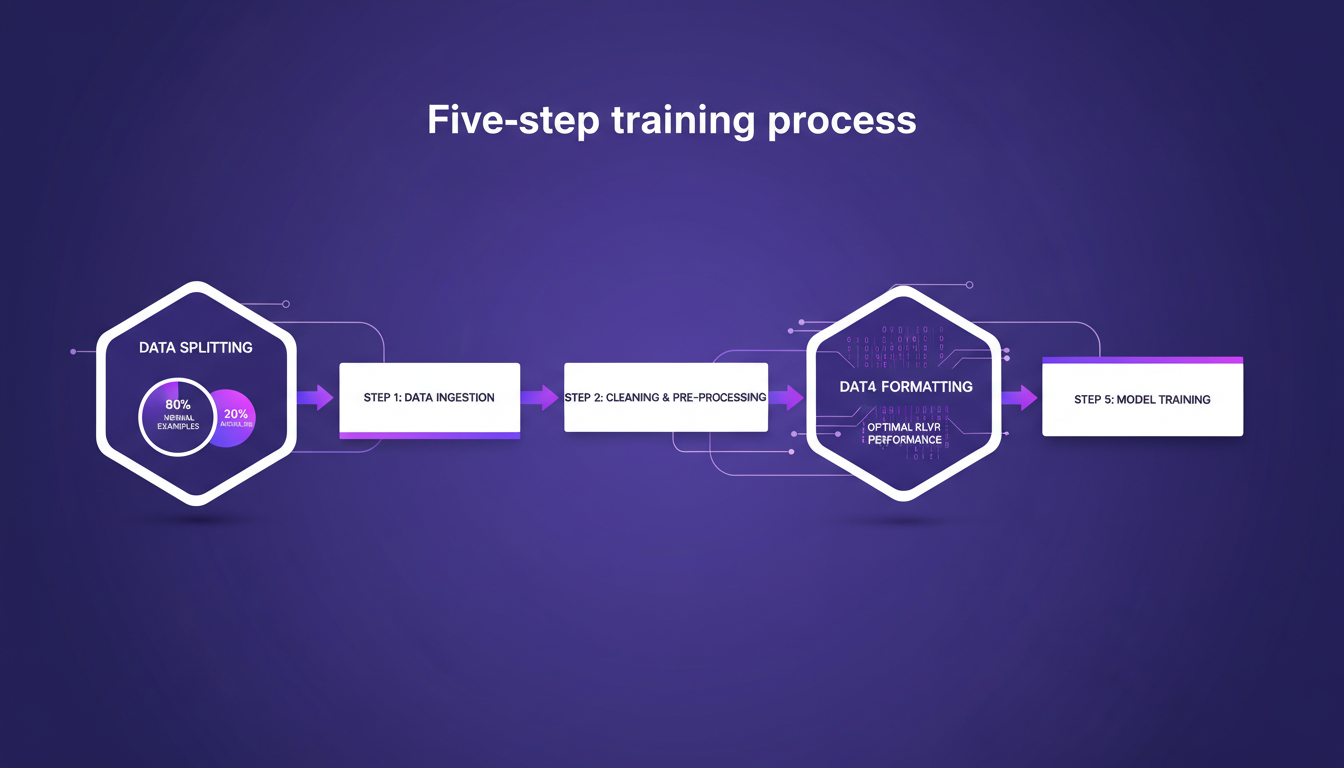
La validation est un autre point crucial. Après un rééchantillonnage, je m'assure toujours d'avoir au moins 50 exemples de validation. C'est là où le bât blesse souvent : on veut être précis, mais cela demande du temps. Il faut jongler entre investissement en temps et précision – un vrai jeu d'équilibriste.
Gérer les Données Déséquilibrées et les Anomalies
Les données déséquilibrées sont le cauchemar des spécialistes du ML. J'ai souvent dû faire face à des jeux de données où les anomalies étaient rares (2% dans certains cas). Pour remédier à cela, j'utilise des techniques de rééchantillonnage. Cela permet de donner au modèle plus de chances d'apprendre. Cependant, cela peut affecter l'efficacité du RLVR.
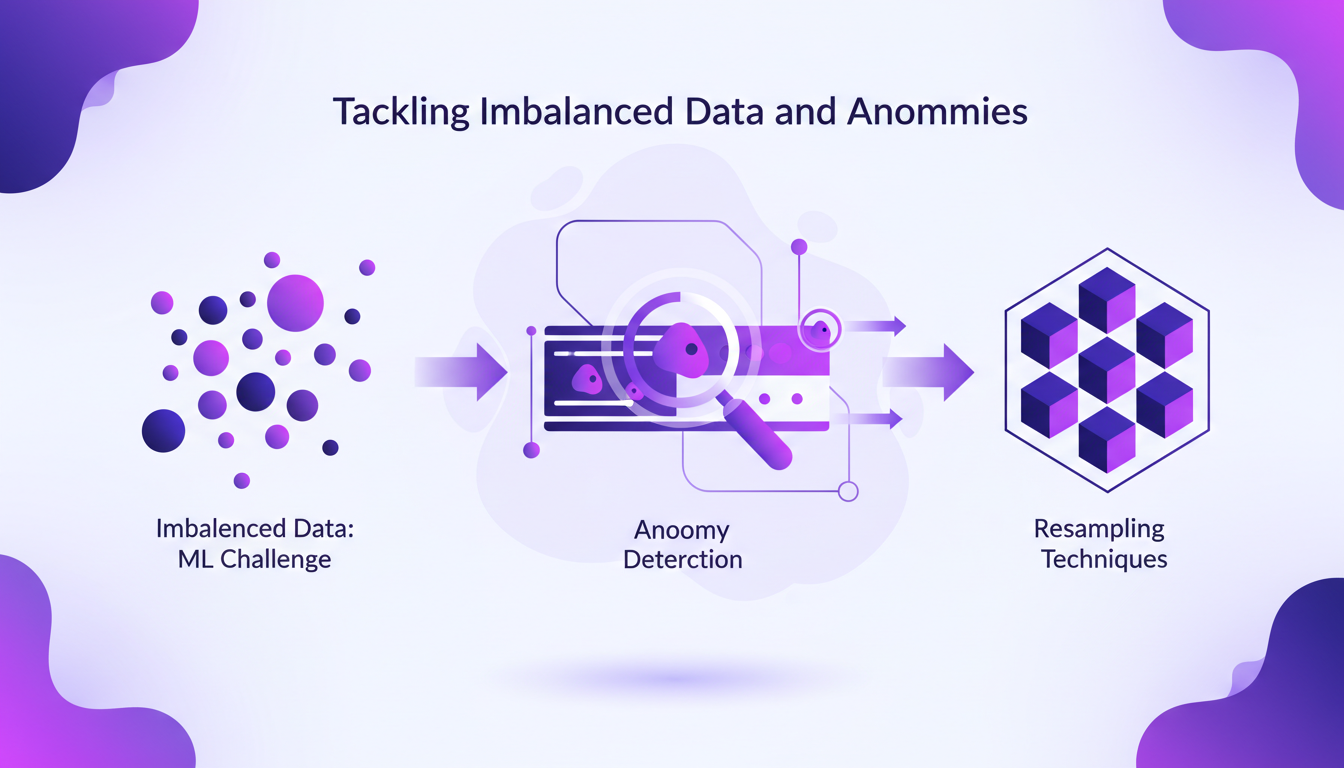
Prévenir les faux positifs est essentiel, sinon le modèle crie au loup pour un rien. Une approche calculée et mesurée est nécessaire, comme je l'ai souvent constaté dans mes projets.
Coût et Efficacité dans le Réglage par Renforcement
La question du coût est inévitable : 100 $ de l'heure pour l'API de renforcement, ça chiffre vite. Pour minimiser cela, j'ai adopté certaines stratégies d'efficacité. Comparer le réglage supervisé au réglage par renforcement est crucial pour comprendre où et comment économiser.
Parfois, il est plus judicieux d'utiliser des alternatives comme TRL ou Unsloth aux API d'OpenAI, même si cela implique quelques compromis en termes de support et de limitations techniques. Mais le gain en coût peut être substantiel.
Explorer les Alternatives Open-Source
Les alternatives open-source apportent souvent un souffle d'air frais. Comparées à l'API d'OpenAI, elles permettent une meilleure intégration dans des flux de travail existants. Mais attention, le support est moins présent, et les défis techniques plus nombreux.
En somme, il s'agit de trouver le bon équilibre entre coût, performance et support technique. Intégrer ces solutions dans vos workflows nécessite un ajustement, mais les bénéfices peuvent être significatifs.
- Le RLVR structure les sorties des LLMs.
- Formatage et validation des données sont cruciaux.
- Rééchantillonnage pour gérer les anomalies rares.
- Coût élevé du réglage par renforcement, d'où l'intérêt des solutions open-source.
Alors, j'ai plongé dans l'ajustement des LLMs avec RLVR, et voici ce que j'ai remarqué. D'abord, jongler entre coûts, efficacité et performance, c'est tout un art. On parle de 100 dollars par heure pour l'API de fine-tuning, donc mieux vaut optimiser son jeu de données dès le départ (et oui, la détection d'anomalies, c'est crucial !). Ensuite, avoir une cinquantaine d'exemples de validation après resampling, ça m'a vraiment sauvé la mise. Et puis, ne sous-estimez pas le bon choix d'outils, que ce soit OpenAI ou des alternatives open source.
En regardant vers l'avenir, RLVR pourrait vraiment changer la donne pour ceux qui sont prêts à explorer et affiner. Mais attention aux données déséquilibrées qui peuvent jeter une clé dans le processus.
Prêt à plonger dans le RLVR pour vos LLMs ? Je vous conseille de commencer à expérimenter avec l'API RFT d'OpenAI. Et si vous voulez vraiment comprendre les rouages, je vous invite à visionner la vidéo complète ici : https://www.youtube.com/watch?v=k-94oCJ_WJo. C'est la troisième vidéo d'une série sur le renforcement de l'apprentissage, et je vous assure, c'est plein de pépites concrètes.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Introduction pratique à l'apprentissage renforcé
Je me souviens de ma première rencontre avec le renforcement de l'apprentissage. C'était comme débloquer un nouveau niveau dans un jeu, où les algorithmes apprennent par essai et erreur, tout comme nous. Contrairement à l'apprentissage supervisé, le RL ne s'appuie pas sur des jeux de données étiquetés. Il apprend des conséquences de ses actions. D'abord, on compare le RL à l'apprentissage supervisé, puis on plonge dans ses applications réelles, notamment dans les jeux. Je vous guiderai à travers les méthodes basées sur la valeur, comme le Q-learning, et les méthodes basées sur la politique, en montrant comment ces approches transforment des modèles de langage massif. En fin de compte, vous verrez comment trois manières clés d'utiliser le RL pour affiner les grands modèles de langage offrent des résultats impressionnants.
Apprentissage Renforcé pour LLMs: Nouveaux Agents IA
Je me souviens encore de la première fois où j'ai intégré l'apprentissage renforcé dans la formation des modèles de langage de grande taille (LLMs). C'était en 2022, et avec le développement de ChatGPT encore frais en mémoire, j'ai compris que c'était un véritable game changer pour les agents IA. Mais attention, il y a des compromis à prendre en compte. L'apprentissage renforcé révolutionne la façon dont nous formons les LLMs, offrant de nouvelles méthodes pour améliorer les agents IA. Dans cet article, je vous emmène avec moi dans mon aventure avec l'AR dans les LLMs, partageant des aperçus pratiques et les leçons apprises. Je vais parler de l'apprentissage renforcé avec feedback humain (RLHF), feedback IA (RLIF), et récompenses vérifiables (RLVR). Préparez-vous à découvrir comment ces approches transforment notre manière de concevoir et d'entraîner les agents IA.
Vision Agentique : Boostez l'IA avec Python
Je me souviens de la première fois où j'ai découvert la Vision Agentique. C'était comme une révélation, en réalisant comment le cadre Penser, Agir, Observer pouvait révolutionner mes projets IA. J'ai intégré cette approche dans mes flux de travail, en particulier pour la souscription d'assurances, et les gains de performance ont été impressionnants. Agentic Vision n'est pas juste un autre mot à la mode en IA. C'est un cadre pratique qui peut vraiment améliorer vos modèles IA, surtout lorsqu'il est associé à Python. Que vous soyez dans l'assurance ou un autre domaine, comprendre cela peut vous faire gagner du temps et augmenter votre efficacité. Dans cette vidéo, je vais vous montrer comment j'ai appliqué la Vision Agentique avec Python, et les améliorations de performance que j'ai observées, notamment dans Google AI Studio.
Lancement d'Ollama : Défi sur Mac
Je me souviens de la première fois où j'ai lancé Ollama sur mon Mac. Comme ouvrir une boîte à outils flambant neuve, remplie de gadgets étincelants que je mourais d'envie de tester. Mais la vraie question, c'est comment ces modèles tiennent la route. Dans cet article, on va plonger dans les fonctionnalités d'Ollama Launch, mettre à l'épreuve le modèle GLM 4.7 flash, et voir comment Claude Code se compare. On va aussi s'attaquer aux défis d'exécuter ces modèles localement sur un Mac et discuter des améliorations possibles. Si vous avez déjà essayé de faire tourner un modèle de 30 milliards de paramètres avec une longueur de contexte de 64K, vous savez de quoi je parle. Alors, prêt à relever le défi ?
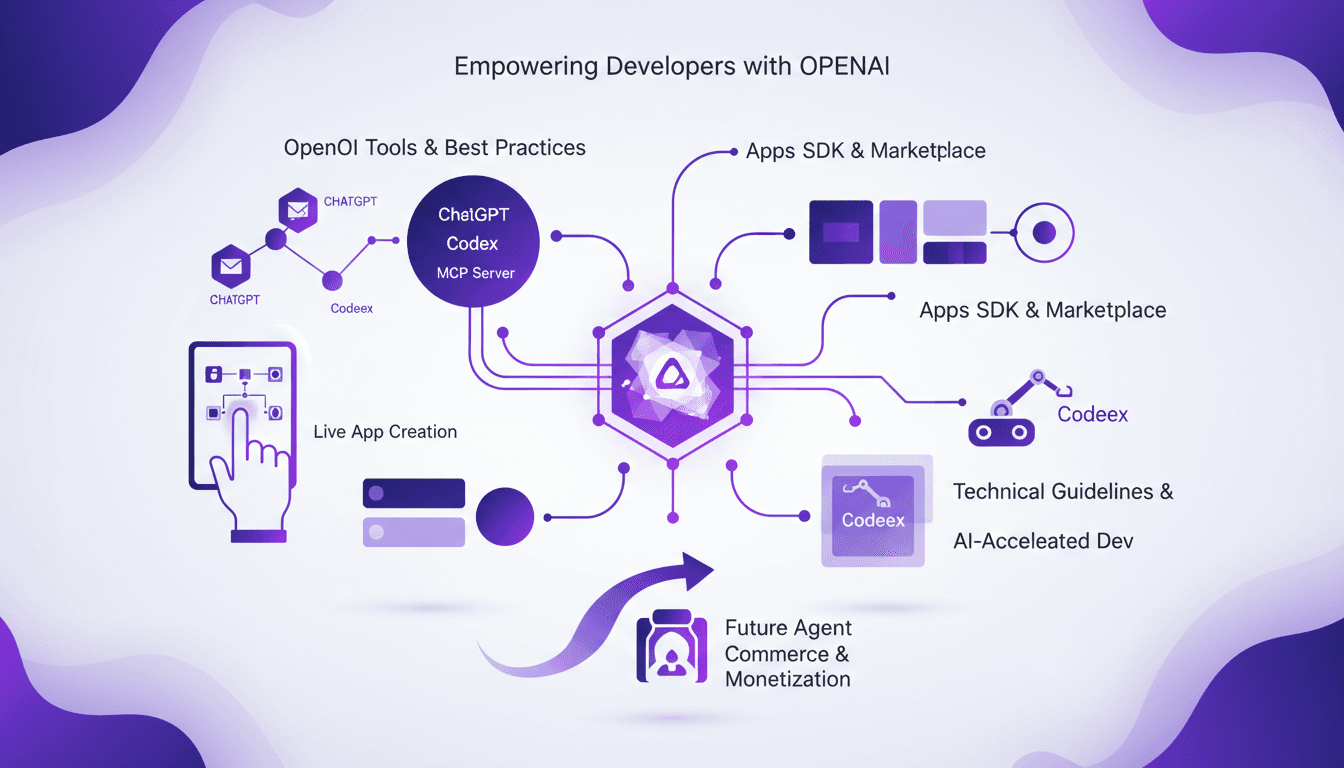
Construire des Apps avec ChatGPT: Guide Pratique
Je suis plongé jusqu'au cou dans l'écosystème OpenAI, et construire des applications dans ChatGPT, c'est comme préparer un espresso dynamique—rapide, efficace et tellement gratifiant. Avec Codeex et MCP, je simplifie tout le processus. Ces outils d'OpenAI sont des game changers pour les développeurs voulant intégrer l'IA dans leurs apps. Après des heures sur le terrain, je partage aujourd'hui mon workflow qui rend la création d'apps non seulement faisable, mais aussi efficace. De l'utilisation de l'OpenAI SDK à la démonstration en direct de la création d'apps, nous allons tout aborder. Je vous garantis que, dans deux minutes, Codeex vous donnera déjà une base de départ.