Former un LLM de A à Z : Guide Pratique
Je me souviens de la première fois où j'ai décidé de former un LLM à partir de zéro. C'était comme escalader une montagne sans carte. Mais une fois que vous comprenez les rouages, c'est comme orchestrer une symphonie. Dans ce guide, je vous emmène dans mon aventure pour construire un LLM localement, inspiré par le Nano GPT d'Andre Karpathy. On va plonger dans le choix du tokenizer, l'architecture des modèles Transformers, les paramètres d'entraînement, et bien plus encore. Je partage les erreurs que j'ai faites, les solutions que j'ai trouvées, et comment j'ai optimisé pour l'efficacité. C'est un guide pratique pour ceux qui veulent vraiment comprendre chaque étape du processus sans perdre de temps sur des détails inutiles.
Je me souviens de la première fois où j'ai décidé de former un LLM de A à Z, en local. C'était un peu comme escalader une montagne sans carte – intimidant et excitant à la fois. Mais une fois que vous commencez à dompter la bête, c'est un véritable plaisir, comme orchestrer une symphonie. Dans ce guide, je vais vous raconter comment j'ai abordé cette tâche titanesque, inspiré par le Nano GPT d'Andre Karpathy. Je vais vous parler du choix du tokenizer, une étape cruciale que j'ai sous-estimée au début, de l'architecture des modèles Transformers, et comment j'ai ajusté les paramètres d'entraînement. Mais attention, il y a des pièges – je me suis fait avoir plus d'une fois, surtout avec la qualité des données et les fonctions de perte. On va aussi explorer les techniques d'inférence et l'évaluation, sans oublier les défis particuliers des modèles audio et multimodaux. Si vous êtes prêt à retrousser vos manches et plonger dans les détails techniques, ce guide est fait pour vous.
Choisir le bon tokeniseur : poser les bases
Quand on parle de l'entraînement de modèles de langage (LLM), le choix du tokeniseur est crucial. Je me suis souvent fait avoir en sous-estimant son importance. D'abord, il y a ce qu'on appelle la tokenisation au niveau des caractères. C'est simple, vraiment. On a 65 tokens possibles, ce qui rend les calculs plus digestes pour le modèle. Mais attention, cela peut vite devenir un casse-tête pour comprendre les corrélations entre tokens. Les bi-grammes peuvent aider à mieux structurer les données, mais là encore, il faut bien orchestrer.
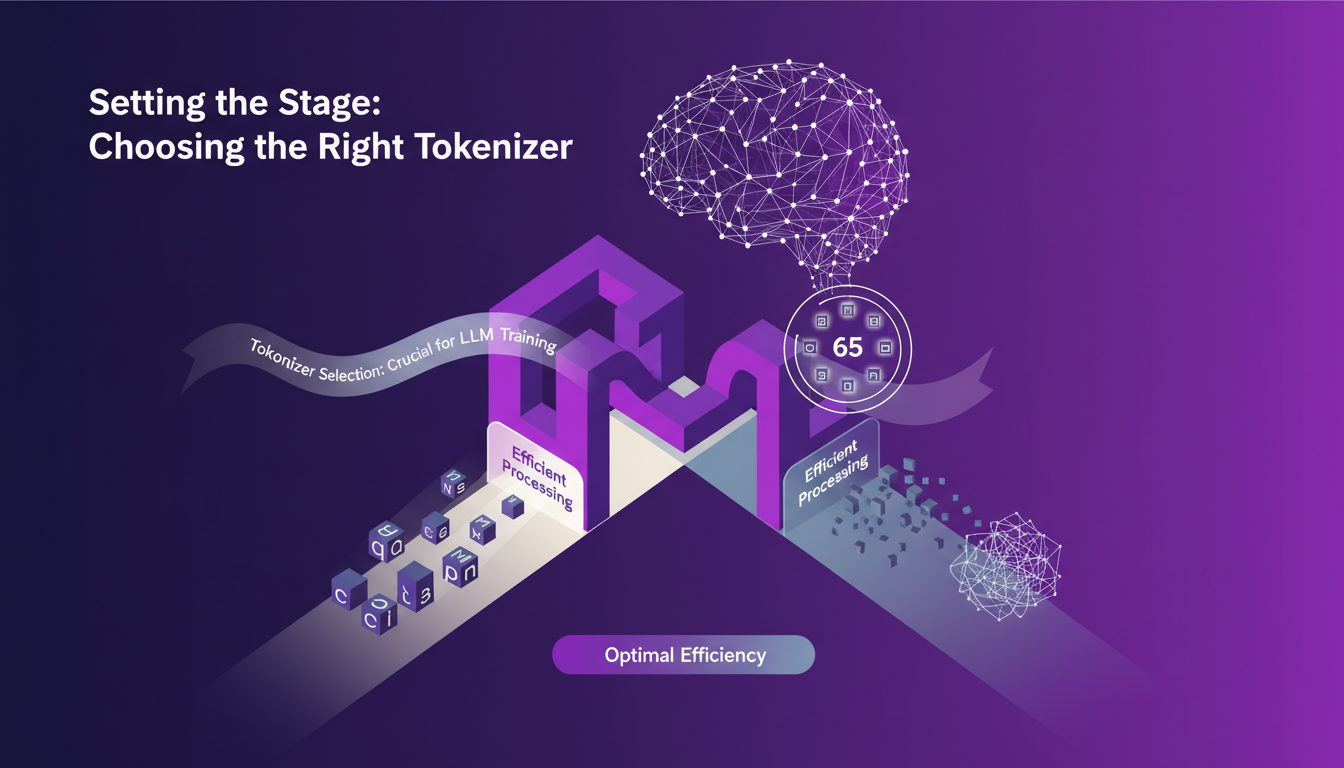
Dans mon agence, j'ai d'abord opté pour un tokeniseur complet avec un grand nombre de tokens. Mauvaise idée. Le manque de convergence était flagrant. Il faut savoir que la simplicité de la tokenisation au niveau des caractères peut être un atout, surtout quand on débute ou qu'on a des limitations en termes de données. Retenez bien : trop de complexité peut entraîner des problèmes de performance.
Décoder l'architecture du modèle Transformer
Les Transformers sont fascinants mais complexes. D'abord, il y a l'attention multi-têtes. Cela permet au modèle de se concentrer sur différentes parties des données en même temps. Ensuite, les connexions résiduelles permettent d'éviter la perte d'information à chaque couche.
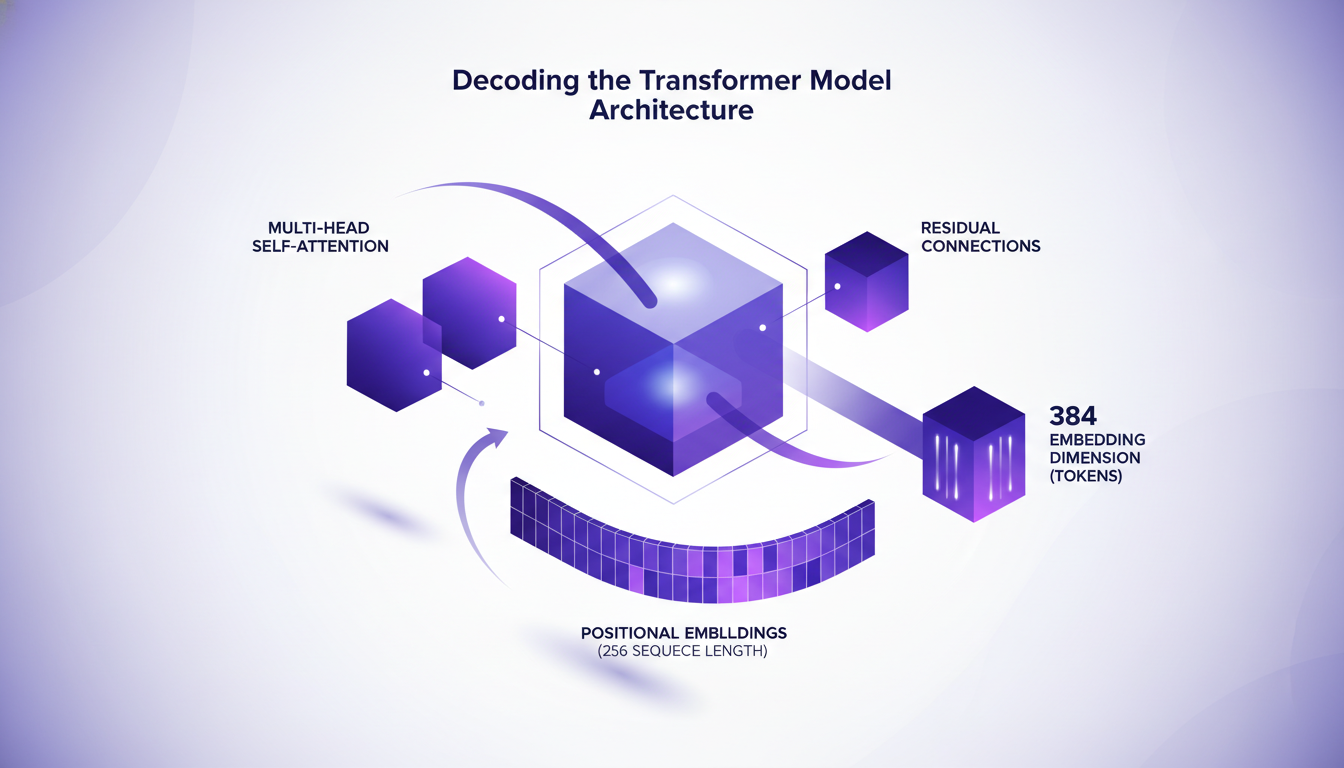
Ensuite, il y a les embeddings positionnels. Avec une longueur de séquence de 256, le modèle "sait" où chaque token se situe. Pour ma part, j'ai choisi une dimension d'embedding de 384 pour les tokens. Pourquoi ? Parce que c'est un bon compromis entre complexité et performance. Cependant, n'oubliez pas que plus la dimension est grande, plus le coût de calcul augmente.
Optimiser les paramètres d'entraînement : ce qui fonctionne
Pour l'entraînement, la boucle est cruciale. Mon approche : ajuster les taux d'apprentissage de manière dynamique. Le cross-entropy loss est souvent utilisé mais attention aux dérives. La divergence de Kullback-Leibler (KL) est un bon complément pour évaluer la différence entre les distributions prédite et réelle.
Il y a des moments clés où le modèle commence à comprendre le contexte. Ça se voit quand il produit des sorties plus cohérentes. Mais gare aux plannings de taux d'apprentissage mal configurés ; ils peuvent faire dérailler tout l'entraînement.
Techniques d'inférence : donner du sens aux sorties
En inférence, je joue souvent avec l'échantillonnage de température. Cela permet de varier la "créativité" des sorties. Trop bas, et le texte est monotone ; trop haut, et on obtient du charabia. Pour évaluer les performances, je m'appuie sur des métriques pratiques plutôt que théoriques.
Lorsqu'on parle de vitesse d'inférence, il faut trouver le juste équilibre avec la précision. Trop se concentrer sur l'un peut nuire à l'autre. Et attention aux erreurs courantes : par exemple, oublier de normaliser les sorties peut fausser les résultats.
Surmonter les défis des modèles multimodaux et audio
Intégrer de l'audio dans les LLM présente des défis uniques. La qualité des données est primordiale. J'ai souvent dû réévaluer mes jeux de données pour m'assurer qu'ils soient suffisamment riches et variés.
Par exemple, lors de l'intégration de données audio et textuelles, les modèles peuvent se perdre si les données ne sont pas bien alignées. Pour l'avenir, je vois des directions intéressantes, mais certaines questions restent sans réponse, notamment sur la manière de tokeniser efficacement la voix et la musique simultanément.
- Choisir le bon tokeniseur est crucial pour éviter des problèmes de convergence.
- Multi-têtes, connexions résiduelles, et embeddings positionnels sont les piliers du Transformer.
- Optimisez vos taux d'apprentissage pour un entraînement efficace et stable.
- Équilibrez précision et vitesse lors de l'inférence.
- La qualité des données est essentielle dans les modèles multimodaux.
J'ai lancé mon projet d'entraînement d'un LLM à partir de zéro et j'ai découvert que c'était plus qu'un simple défi technique. Chaque étape, du choix du tokenizer aux défis multimodaux, m'a appris quelque chose de nouveau. Voici les clés concrètes :
- Sélection du tokenizer : J'ai opté pour une tokenisation au niveau des caractères avec 65 tokens possibles. C'est flexible, mais attention à l'explosion des séquences.
- Architecture du modèle : J'ai choisi 256 comme longueur de séquence avec des embeddings de 384 dimensions. C'est un standard qui fonctionne bien, mais ça prend de la mémoire.
- Paramètres d'entraînement : Ne négligez pas l'optimisation, ça peut être un game changer. Mais trop d'itérations peuvent ralentir le processus.
L'avenir de l'entraînement LLM est prometteur. On peut toujours affiner et tester de nouvelles approches. Prêts à démarrer votre propre aventure LLM ? Partagez vos expériences et poursuivons la conversation. Pour plus de détails, regardez la vidéo originale d'Angelos Perivolaropoulos : Training an LLM from Scratch, Locally. C'est plein de pépites pour ceux qui construisent comme nous.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Développer le Contexte comme un Code: Ma Méthode
Je me souviens du moment où j'ai entendu pour la première fois 'le contexte est le nouveau code'. Ça a été une révélation. Tout s'est éclairé. J'ai compris que le contexte n'était pas juste un décor, mais une partie vivante de notre cycle de développement, tout comme le code lui-même. Dans un paysage technologique qui évolue rapidement, comprendre et utiliser le contexte peut vraiment tout changer. Ce n'est plus seulement une question d'écrire du code efficace, mais d'orchestrer le bon contexte autour de lui. Voici comment je m'y prends pour relever ce défi au quotidien, en intégrant le contexte dans chaque étape de mon flux de travail, du développement à l'optimisation. On va parler de sécurité, de tests, et de comment distribuer ce contexte, parce que, croyez-moi, j'ai appris certaines leçons à la dure. Préparez-vous à voir le contexte sous un nouvel angle.
Récursion en IA: Révolutionner les Modèles
J'ai passé des heures à peaufiner des modèles d'IA, et franchement, la récursion est le game changer qu'on attendait. Finies les courses à plus de paramètres, place à l'intelligence. Quand les modèles traditionnels butent sur des limites, la récursion offre une perspective nouvelle. On va explorer comment elle pourrait redéfinir l'efficacité et les capacités de l'IA. On parlera de modèles de raisonnement hiérarchique, de modèles récursifs miniatures, d'apprentissage d'équilibre profond et des défis de l'optimisation. Si vous avez déjà été frustré par les murs de la scalabilité, vous allez adorer ce nouveau paradigme.
Sandbox E2B : Testez votre SDK Agent
Je me suis lancé tête baissée dans le test de notre SDK agent cloud dans le sandbox E2B, et croyez-moi, ce fut un vrai tour de montagnes russes. De la configuration initiale au déploiement, j'ai rencontré des obstacles de sécurité et des rebondissements inattendus qui m'ont tenu en haleine. Dans le monde des environnements cloud, la sécurité et l'efficacité sont primordiales. Que vous adaptiez un SDK ou gériez des clés API, les défis sont bien réels. Voici mon parcours à travers le sandbox E2B pour affronter ces problèmes. Je me suis retrouvé face à des préoccupations de sécurité avec les clés API et des problèmes de déploiement sur Render dus aux protocoles de sécurité. Ne vous laissez pas surprendre par les pièges du sandboxing – suivez mon voyage et découvrez comment contourner ces obstacles.
Claude Co-work : Guide du Praticien
Je me souviens encore de la première fois où j'ai configuré Claude Co-work. C'était comme ouvrir une boîte à outils pleine de possibilités infinies. Mais soyons honnêtes, ce n'était pas un long fleuve tranquille. Après m'être embrouillé plusieurs fois, j'ai finalement orchestré la configuration, les fonctionnalités et la personnalisation de Claude Co-work pour en faire un véritable atout dans mes projets. Que vous soyez novice ou que vous ayez déjà un peu de bouteille, comprendre comment tirer le meilleur parti de cet assistant AI est crucial. On y va, je vous montre comment faire de Claude Co-work un allié redoutable.
Configurer Codex en quelques clics pour gagner du temps
Je me souviens de la première fois où j'ai configuré Codex. C'était comme débloquer un nouveau niveau de productivité. En quelques clics, j'avais intégré mes projets et outils de manière fluide. Je vais vous montrer comment je l'ai fait, et comment vous pouvez le faire aussi. Avec Codex, orchestrer votre flux de travail devient un jeu d'enfant, que ce soit pour transférer des projets, intégrer des systèmes ou se préparer à des réunions. Le secret, c'est une configuration efficace. J'ai connecté mes systèmes à Codex, intégré Google Calendar, Gmail, et Slack, et j'ai vu une transformation immédiate dans la gestion de mon temps. Je vais vous guider à travers ces étapes pour que vous puissiez maximiser votre efficacité avec Codex.