Optimiser BERT Moderne : Gardes Fous AI à 1$
Je suis tombé dans le terrier des failles de sécurité de l'IA, et croyez-moi, ce n'est pas joli à voir. Mais après d'innombrables nuits blanches et un peu trop de café, j'ai découvert comment affiner les BERT modernes pour seulement un dollar, les rendant non seulement plus efficaces mais aussi plus sûrs. Dans cette vidéo, je vous montre comment j'ai fait. On parle d'attaques LLM, d'injections de prompts, et des améliorations architecturales de BERT moderne. Si vous avez déjà été brûlé par une faille de sécurité IA, vous saurez pourquoi chaque milliseconde compte. Et oui, j'ai réduit l'utilisation de mémoire de 40 % en utilisant le format brain floating point de Google. Venez découvrir comment je m'y suis pris.
J'ai littéralement plongé dans l'univers des failles de sécurité de l'IA, et je peux vous dire que ce n'est pas un spectacle plaisant. Mais après des nuits interminables à jongler avec des lignes de code et à carburer au café, j'ai découvert une méthode pour affiner les BERT modernes pour seulement un dollar par modèle, les rendant à la fois plus efficaces et plus sûrs. Imaginez: accomplir une tâche de classification en 35 millisecondes grâce à cet ajustement fin. Avec l'évolution des attaques LLM et les vulnérabilités architecturales, il était temps de mettre en place des gardes fous. Et en réduisant l'utilisation de mémoire de près de 40 % avec le format brain floating point de Google, j'ai pu optimiser le tout sans casser la tirelire. Dans cette vidéo, je partage mes découvertes sur les améliorations architecturales de BERT moderne et les techniques de défense AI. Croyez-moi, quand on a été brûlé par une faille de sécurité, on apprend à mettre en place des stratégies béton. Prêts à plonger dans le vif du sujet?
Évolution des Attaques LLM : Perspective d'un Bâtisseur
Depuis 2023, les attaques sur les LLM (Large Language Models) ont évolué de manière spectaculaire. Ce qui a commencé avec des utilisateurs curieux explorant les injections de prompt est devenu un paysage complexe où ces attaques sont intégrées dans les workflows d'identité. Je me souviens encore de la première fois que j'ai dû faire face à une injection de prompt. C'était comme si quelqu'un avait ouvert une porte dérobée dans mon modèle, exfiltrant des données sensibles par le biais d'entrées utilisateur habilement conçues.
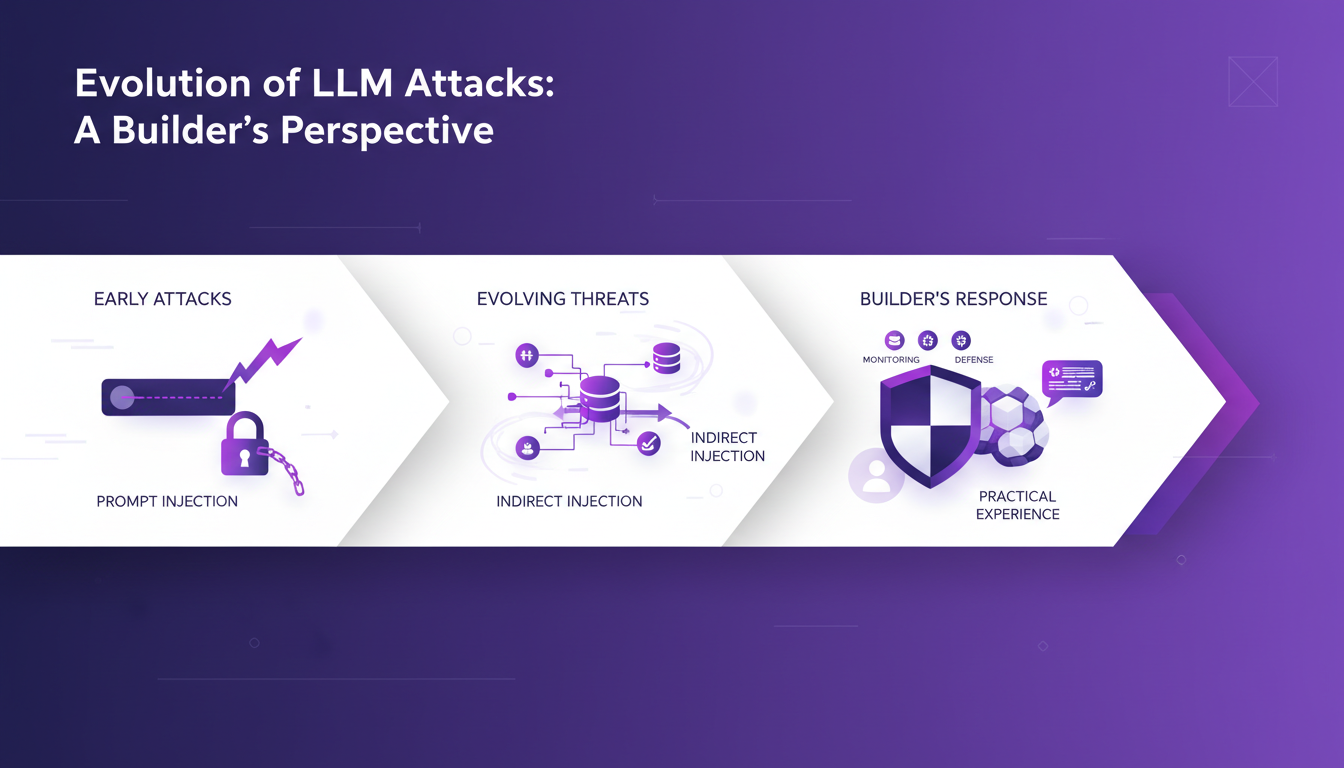
Ensuite, on a vu l'émergence de l'injection indirecte. Cela consiste à placer des instructions malveillantes dans des contenus externes, comme un site web, pour que le LLM les récupère. J'ai vu des modèles se faire manipuler juste parce qu'ils ont "lu" des instructions cachées dans un e-mail ou une page Wikipedia modifiée. Comprendre ces vecteurs d'attaque est crucial pour la sécurité de l'IA, car le manque de séparation native entre les contrôles système et les données dans les LLM crée un fossé de confiance zéro.
Améliorations Architecturales : Les Nouveaux Tours de BERT Moderne
Passons à l'architecture. Les améliorations apportées à BERT moderne sont un véritable game changer. Grâce à des techniques comme l'encodage positionnel rotatif et l'attention flash, nous avons réduit le gaspillage de calcul de 50%. Je me suis retrouvé à intégrer ces fonctionnalités dans mon workflow, et la différence est palpable. Les tâches qui prenaient autrefois des heures ne nécessitent maintenant que quelques minutes.

Mais attention, ces améliorations ne sont pas sans compromis. Par exemple, intégrer l'attention flash nécessite une gestion méticuleuse de la mémoire, sinon on risque de surcharger les GPU. C'est un équilibre entre performance et ressource, mais une fois bien orchestré, le gain est indéniable.
Sécurité de l'IA : Construire des Couches Défensives
Pour sécuriser nos modèles IA, j'ai mis en place plusieurs couches défensives. Le concept de fossé de confiance zéro est fondamental ici. Il s'agit d'une approche où aucun élément n'est considéré comme sécurisé par défaut. J'ai aussi utilisé des gibberish suffix tokens pour déjouer les attaques par alignement de modèle. Ces suffixes perturbent les distributions de probabilité, rendant les modèles moins prévisibles.
Cependant, il faut faire attention à ne pas trop complexifier le système, ce qui pourrait nuire aux performances. Trouver cet équilibre entre sécurité et performance est un défi constant, mais indispensable pour protéger les informations sensibles.
Affinage pour l'Efficacité : Mon Workflow
L'affinage de BERT moderne pour l'efficacité est une aventure en soi. En utilisant le format flottant de Google Brain, j'ai pu réduire l'utilisation de la mémoire de près de 40%. C'est énorme quand on pense à la quantité de données que nous traitons quotidiennement.

Un conseil que je donne toujours : ne jamais négliger les optimisations mémoire. Parfois, il est plus rapide de revoir une architecture que de forcer les choses. En coupant dans le gras, j'ai réussi à faire passer le temps d'exécution de mes tâches de classification à seulement 35 millisecondes.
Conséquences des Brèches de Sécurité en IA : Leçons Apprises
Les brèches de sécurité en IA ont des conséquences bien au-delà d'un simple risque de réputation. J'ai vu des informations personnellement identifiables, des dossiers de santé, et même des systèmes de prise de décision entière être compromis. C'est un rappel brutal de la nécessité de mesures de sécurité proactives.
J'ai appris que la prévention est toujours plus efficace que la réparation. Par exemple, la manipulation de seulement cinq morceaux dans une base de données de 8 millions de documents a suffi pour induire notre modèle en erreur. Cela m'a poussé à revoir ma stratégie de sécurité et à mettre en place une feuille de route pour des améliorations continues.
- Implémenter des vérifications de sécurité AI avec des modèles encodeurs.
- Améliorer l'alignement du modèle avec des examinateurs humains.
- Éviter la complaisance et rester vigilant face aux nouvelles menaces.
En finetunant Modern BERT, j'ai non seulement amélioré l'efficacité, mais aussi renforcé les mesures de sécurité. C'était un défi, mais les résultats sont là. Voilà ce que j'ai appris :
- Le modèle fiabilisé exécute une tâche de classification en 35 millisecondes, une efficacité inégalée.
- Grâce au format brain floating point de Google, j'ai réduit l'utilisation mémoire pendant l'entraînement de près de 40 %.
- Modern BERT a introduit une réduction de 70 % des besoins en mémoire pour le finetuning.
Ces optimisations transforment vraiment la manière dont on aborde la sécurité des modèles IA. On est loin des théories abstraites, on parle d'impact concret sur le quotidien de nos infrastructures. Prêt à mettre en œuvre ces stratégies ? Sécurisons ensemble notre avenir IA. Partagez vos expériences et continuons d'apprendre les uns des autres. Pour une plongée plus profonde, regardez l'excellent vidéo de Diego Carpentero, c'est un must pour quiconque veut comprendre comment mettre ces idées en pratique : YouTube link.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Négocier sans se faire avoir: Stratégies efficaces
J'ai passé des années dans les tranchées des négociations immobilières, et si j'ai bien appris quelque chose, c'est que se faire avoir sur le prix, ça fait mal. Mais rassurez-vous, j'ai trouvé des moyens de renverser la situation. Je vais vous montrer comment j'utilise la psychologie pour maintenir mes affaires sur les rails. Dans le monde rapide de l'immobilier, la négociation ne se résume pas aux chiffres, c'est un jeu psychologique. Savoir éviter les pièges courants et utiliser l'intelligence émotionnelle peut transformer vos négociations. Explorons ensemble comment tirer parti de ces idées pour améliorer nos résultats. #immobilier #investissementimmobilier #psychologie
Paperclip : Orchestrer vos agents AI efficacement
Je me souviens de la première fois où j'ai entendu parler de Paperclip : on aurait dit un véritable bouleversement pour l'orchestration AI. Dans ma carrière, je me suis souvent fait avoir par des systèmes trop complexes, alors j'étais sceptique. Mais en plongeant dedans, j'ai découvert un outil qui peut vraiment simplifier mes workflows AI sans les tracas habituels. Paperclip, cet orchestrateur open-source, est conçu pour gérer efficacement les agents AI, et je l'ai intégré dans mes opérations pour éviter les migraines techniques. On parle ici d'une orchestration fluide, de la gestion de différents types d'agents comme Gemini et Hermes, et d'une communauté engagée qui pousse constamment le développement. Bref, si vous cherchez à optimiser vos opérations pilotées par AI, Paperclip pourrait bien être l'outil qui change tout.
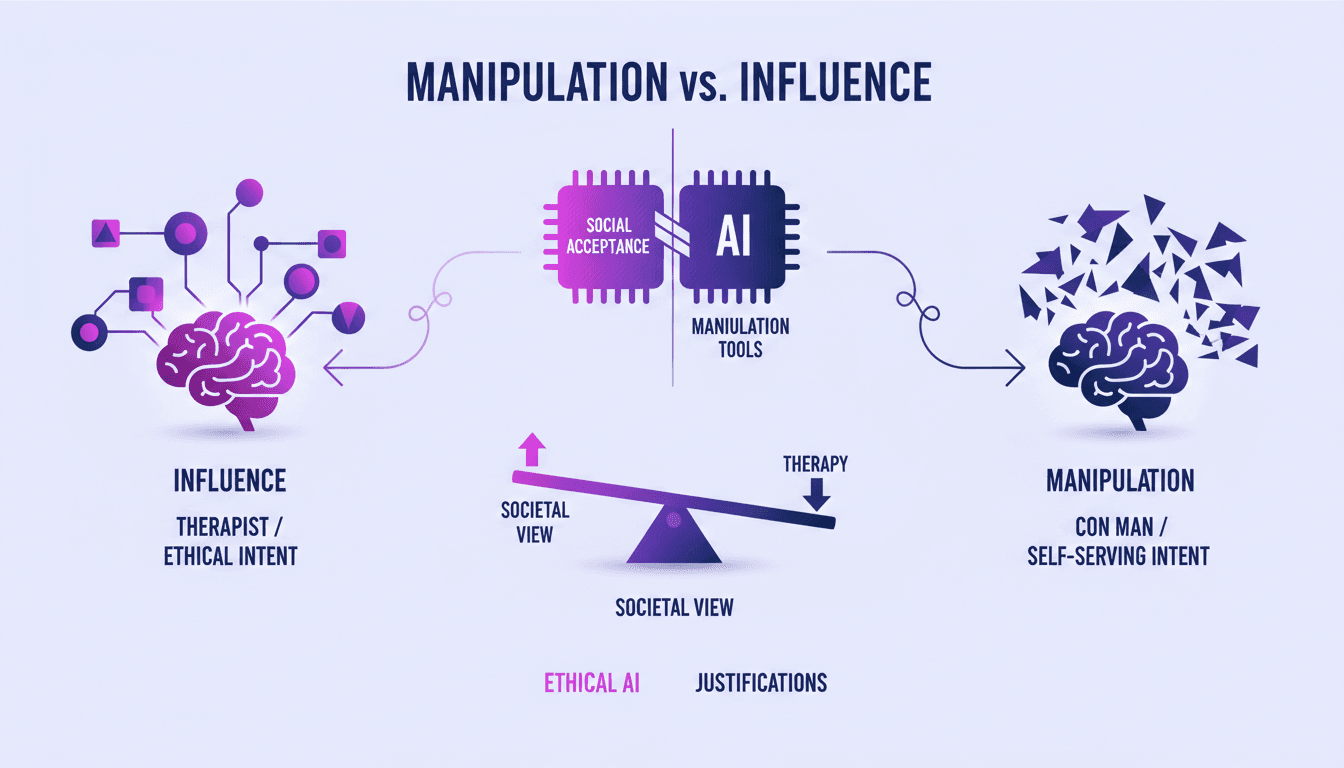
Manipulation vs Influence : Comprendre la Thérapie
J'ai été dans des salles de thérapie où la frontière entre manipulation et influence était floue, et ce n'est qu'en comprenant l'intention derrière les actions que j'ai pu voir pourquoi la manipulation n'est pas toujours une mauvaise chose. Dans cet article, on plonge dans la manière dont la thérapie utilise ces outils de manière éthique. On va explorer la différence entre manipulation et influence, et comment l'intention joue un rôle crucial dans la pratique éthique. On va aussi comparer les techniques des thérapeutes à celles des escrocs, et discuter des implications éthiques de l'utilisation de ces outils de manipulation.
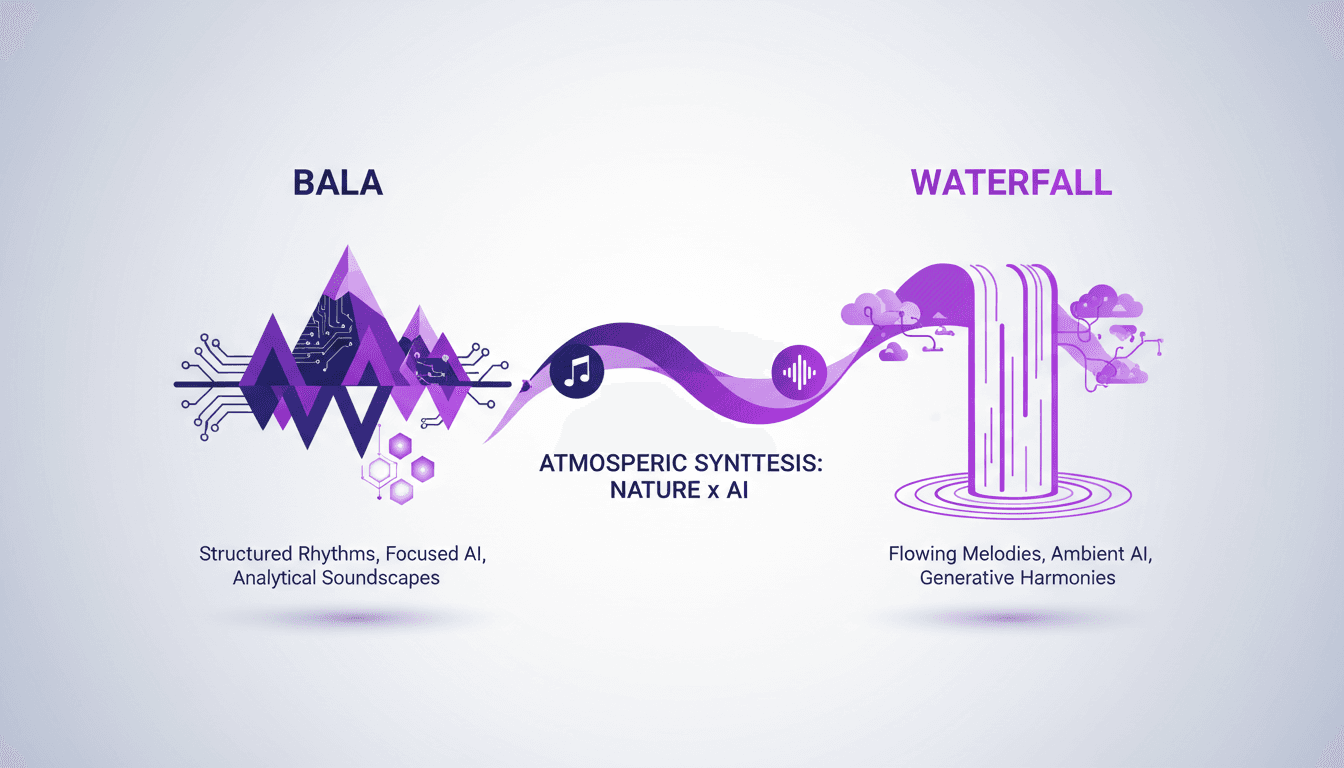
Bala vs Cascade : Comparaison Pratique et Impact
J'ai passé d'innombrables heures à intégrer des éléments naturels comme Bala et les cascades dans mes projets. Aujourd'hui, je vais décortiquer comment ces éléments se comparent, non seulement en théorie, mais aussi dans des applications réelles. Que vous cherchiez à enrichir un espace avec des paysages sonores ou à créer une ambiance immersive, comprendre les nuances entre Bala et la cascade peut faire toute la différence. Je compare leurs caractéristiques, leurs impacts sur l'atmosphère, et vous montre comment les utiliser efficacement.
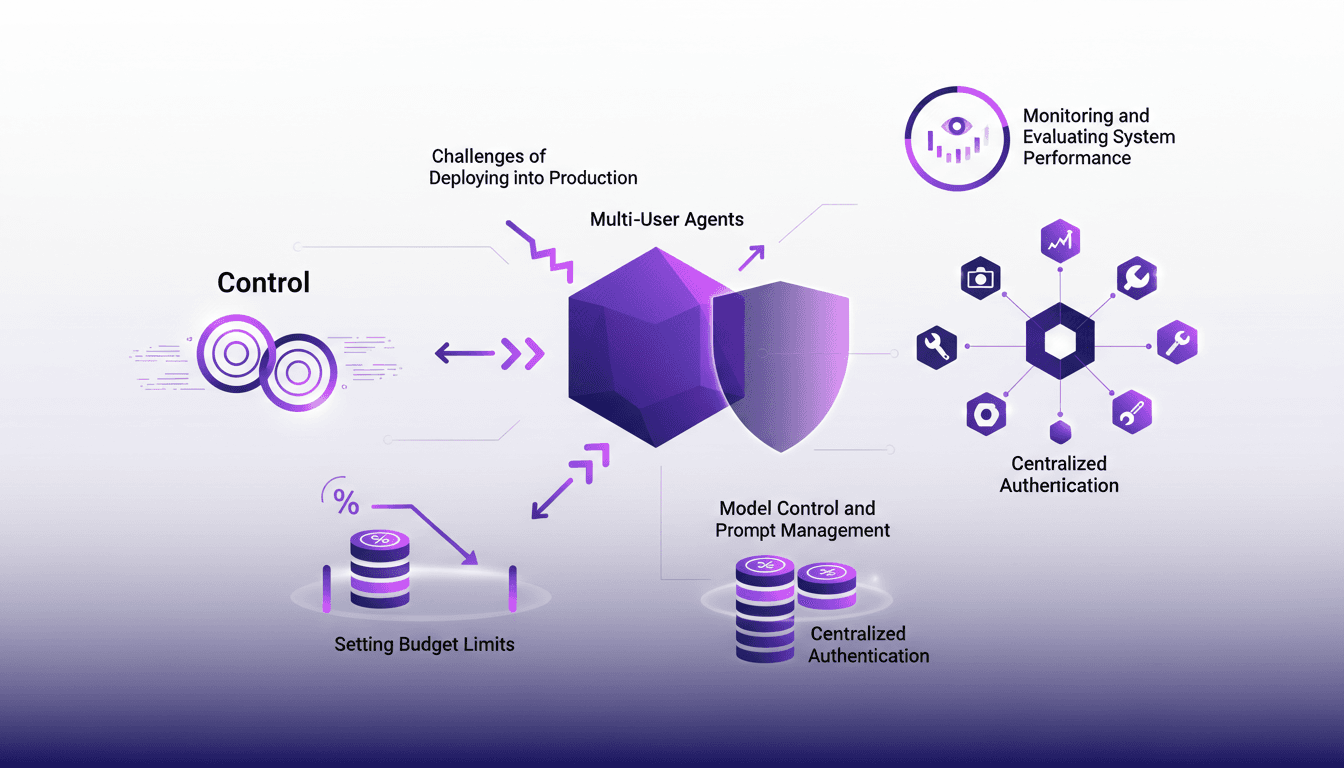
Déploiement d'agents : 7 étapes essentielles
J'ai déjà été là—agents déployés, coûts qui explosent, le chaos s'ensuit. Parfois, c'est comme voir un agent courir une facture de 10k en une nuit. Parlons des sept choses essentielles à verrouiller avant que n'importe quel agent ne passe en production. Dans cet article, je vous emmène dans mon workflow et les leçons que j'ai apprises. On va parler de la gestion des modèles, de la mise en place des garde-fous, et comment éviter que vos agents ne hallucinent pour 200 utilisateurs différents.