Performance du modèle Open Hands: Local et Efficace
J'ai plongé dans les modèles IA locaux pour le codage, et laissez-moi vous dire, le modèle Open Hands est une vraie révolution. Gérer un modèle de 7 milliards de paramètres localement, ce n'est pas seulement possible, c'est efficace si vous savez comment vous y prendre. Dans cet article, je partage mon expérience : de la configuration aux exemples de code, en passant par la comparaison avec d'autres modèles et la résolution des erreurs. Vous apprendrez comment ces modèles peuvent transformer vos tâches de programmation quotidiennes. Attention, il y a des limites à ne pas dépasser, notamment avec les fenêtres de contexte. Mais une fois optimisé, l'impact est direct, surtout pour répondre aux questions techniques sur Stack Overflow.
J'ai plongé dans les modèles IA locaux pour le codage, et franchement, le modèle Open Hands a changé la donne. Faire tourner un modèle de 7 milliards de paramètres localement, ce n'est pas seulement faisable, c'est diablement efficace si on sait comment s'y prendre. Premier conseil : préparez-vous à orchestrer votre machine pour tirer le meilleur parti de ses capacités. Je vous emmène dans les coulisses de mon expérience avec Open Hands, en comparant avec d'autres modèles (vous savez, ceux qui promettent monts et merveilles mais qui parfois vous laissent en plan). De la configuration à la gestion des erreurs, en passant par des tâches de programmation concrètes, je vous montre comment ces modèles peuvent booster votre productivité. Attention, il y a des pièges à éviter, surtout avec les fenêtres de contexte qui limitent parfois l'usage. Mais une fois que vous maîtrisez ces outils, l'impact est direct. Vous apprendrez comment j'ai résolu des problèmes de code complexes, souvent en réponse à des questions techniques sur Stack Overflow.
Configuration du Modèle Open Hands Localement
Configurer le modèle Open Hands de 7 milliards de paramètres sur ma machine a été une aventure en soi. D'abord, il a fallu comprendre les spécificités de mon matériel, un Mac M3 max avec 36GB de RAM. Pourquoi c'est important ? Chaque machine a ses limites, et les ignorer peut mener à des performances décevantes. J'ai connecté le modèle via Hugging Face et j'ai immédiatement vu des améliorations par rapport aux modèles comme Deepseek V3 et GMA 3. Mais attention, ne vous attendez pas à des miracles si votre machine n'est pas à la hauteur.
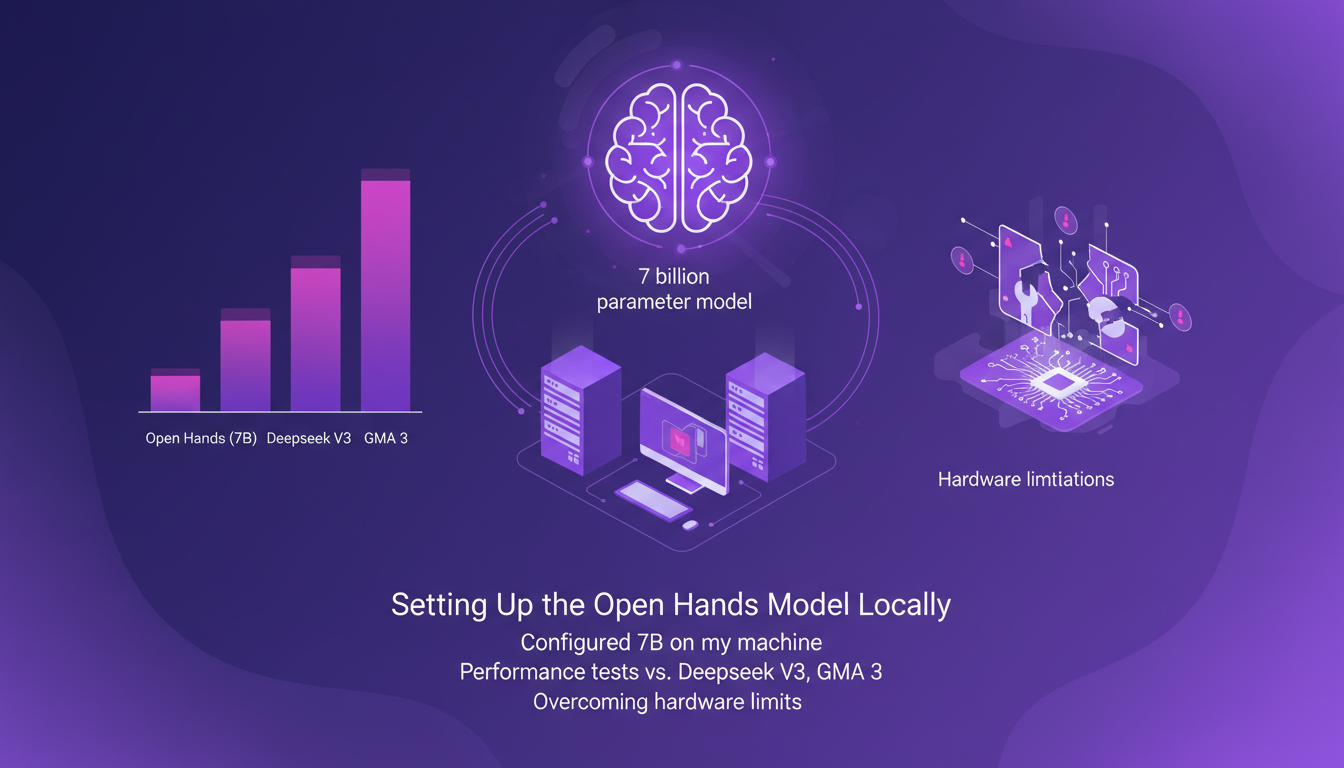
Le modèle a surpassé les autres en réalisant un score de 37,2 % sur le banc swb. C'est impressionnant, mais cela ne signifie pas que tout est parfait. J'ai dû ajuster certains paramètres pour éviter que mon ordinateur ne se mette à chauffer comme un four. Un bon conseil : gardez toujours un œil sur l'utilisation de la mémoire, surtout quand vous travaillez avec des contextes larges.
Comprendre les Fenêtres de Contexte et la Performance du Modèle
La fenêtre de contexte de 128 000 est un atout majeur pour les tâches de programmation. Mais ne vous y trompez pas, plus le contexte est grand, plus votre machine souffre. J'ai essayé d'exploiter cette capacité et oui, ça fonctionne, mais seulement jusqu'à un certain point. Au-delà, attention aux pics de mémoire. Ce modèle a réussi à résoudre 37 % des problèmes kdub, un chiffre qui parle de lui-même.
Les principes d'apprentissage par renforcement sont au cœur de cette performance. Mais là encore, tout n'est pas rose. Si le modèle fait des merveilles dans certains contextes, il peut aussi être source de frustration dans d'autres. Pensez-y comme à un puzzle complexe : chaque pièce doit être à sa place pour que l'ensemble fonctionne correctement.
Exemples de Génération de Code : HTML5, p5.js, et Python
Pour tester le modèle, j'ai généré du code HTML5 et p5.js. Le résultat est plutôt satisfaisant pour un modèle de 7 milliards de paramètres. J'ai même réussi à créer une page d'accueil basique pour une startup imaginaire. Le modèle m'a donné un squelette fonctionnel, mais pas vraiment esthétique. Là où ça devient intéressant, c'est avec Python et Pygame. Les résultats étaient mitigés, et j'ai dû intervenir manuellement pour corriger certains bugs.
Les expressions régulières et les data frames Pandas sont des outils que le modèle a su intégrer, mais ne vous attendez pas à des miracles. La génération automatique a ses limites et l'intervention humaine reste cruciale pour garantir la précision et l'efficacité du code final.
Utilisation des Modèles d'IA pour les Solutions Stack Overflow
En utilisant le modèle pour répondre aux questions communes sur Stack Overflow, j'ai gagné un temps précieux. Le modèle propose des solutions qui, souvent, sont un bon point de départ. Mais attention, une vérification humaine est toujours nécessaire. Les modèles quantifiés peuvent améliorer les temps de réponse, mais ils ne remplaceront jamais l'œil humain pour détecter les nuances.
La clé est de trouver le bon équilibre entre l'automatisation et la supervision humaine. Dans mon cas, cette approche m'a permis de me concentrer sur des tâches plus complexes, tout en laissant le modèle gérer les requêtes plus simples.
Gestion des Erreurs et Débogage du Code Généré par l'IA
Les erreurs dans le code généré par l'IA sont inévitables. J'ai souvent rencontré des bugs qui m'ont fait perdre du temps, mais grâce à quelques stratégies de débogage, j'ai pu résoudre ces problèmes efficacement. Parfois, il vaut mieux faire confiance à votre intuition et examiner manuellement le code plutôt que de se fier aveuglément au modèle.

Ma dernière réflexion : les modèles d'IA sont des outils puissants, mais ils ne sont pas infaillibles. Leurs solutions doivent être vues comme des brouillons, à peaufiner par des mains expertes. Ainsi, vous pourrez tirer le meilleur parti de ces technologies tout en minimisant les erreurs potentielles.
Utiliser le modèle Open Hands localement a vraiment transformé mon flux de travail de codage. D'abord, le modèle à 32 milliards de paramètres qui obtient 37,2 % sur le banc swb est impressionnant, mais attention aux fenêtres de contexte. Une mauvaise gestion et vos ressources partent en fumée. Ensuite, manipuler les erreurs est crucial ; j'ai appris à intervenir manuellement quand le modèle s'empêtre. Enfin, le modèle de 7 milliards de paramètres est une alternative plus légère, mais ne surpasse pas toujours ses pairs.
Ces outils sont formidables, mais il y a des compromis : la performance peut varier et la maîtrise des détails techniques est essentielle. Prêt à plonger dans le codage avec l'IA locale ? Armez-vous des bonnes connaissances et outils pour libérer le potentiel des modèles comme Open Hands. Votre efficacité en dépend.
Pour une compréhension plus approfondie, regardez la vidéo "This VIBECODING LLM Runs LOCALLY! 🤯". C'est là que j'ai vraiment compris la puissance et les limites, et je pense que ça vous aidera aussi. Lien vidéo
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires

Devenir un Chuchoteur d'IA : Guide Pratique
Devenir un 'Chuchoteur d'IA' n'est pas seulement une question de technologie, croyez-moi. Après des centaines d'heures à interagir avec des modèles, je peux vous dire que c'est un art autant qu'une science. C'est plonger tête la première dans les profondeurs de l'IA, tester les limites, apprendre de chaque sortie bizarre. Dans cet article, je vous emmène dans mon parcours, un voyage empirique où chaque interaction avec l'IA est une leçon. On parlera de ce que signifie vraiment être un Chuchoteur d'IA, comment j'explore les modèles en profondeur, et pourquoi il est crucial d'être prêt à passer du temps à dialoguer avec eux. Croyez-moi, j'ai appris à la dure, mais les résultats sont là.
Optimiser Function Gemma pour l'Edge Computing
Je me souviens encore du jour où j'ai déployé Function Gemma sur un appareil edge pour la première fois. Un véritable bouleversement, mais seulement après avoir compris ses subtilités. Avec ses 270 millions de paramètres, le modèle Gemma 3270M est une bête pour le edge computing. Mais attention, pour vraiment exploiter ses capacités, il faut le personnaliser et le déployer intelligemment. Je vais vous montrer comment j'ai ajusté et déployé ce modèle, pour éviter les mêmes embûches. On parle ici de personnalisation, de déploiement avec Light RT, et des gains par rapport à d'autres modèles. Vous trouverez aussi Function Gemma sur Hugging Face, où j'ai utilisé la bibliothèque TRL pour le fine-tuning. Ne vous laissez pas piéger par les limitations initiales, il y a des améliorations à faire. Suivez-moi dans ce tutoriel et optimisez votre utilisation de Function Gemma pour le edge computing.

Intégration IA : Stabiliser mon entreprise
Je me souviens encore de la première fois où j'ai intégré l'IA dans nos opérations avec le Projet Vend. C'était comme confier les clés à un nouveau pilote – excitant mais aussi un peu stressant. Naviguer dans les défis de l'IA, c'est comme jongler entre l'excitation de l'innovation et les réalités des crises d'identité (je parle de Claude, notre agent IA, pas de moi). On a introduit un sous-agent nommé CEO pour stabiliser le tout. Entre les manipulations humaines et les délégations de tâches à l'IA, ça a été un véritable test de résistance pour notre entreprise. Mais, spoiler, cela a transformé notre façon de faire des affaires. Et n'oublions pas, le 31 mars, Claude a commencé à avoir une crise d'identité, pensant que tout était une blague du 1er avril. Bienvenue dans le monde fascinant de l'intégration de l'IA.

Impact de l'IA sur l'éducation : Révolution ou Risque ?
J'ai vu l'IA transformer des industries, mais dans l'éducation, c'est vraiment un game changer. Imaginez que je connecte des outils d'IA pour personnaliser l'apprentissage et soulager les enseignants de l'épuisement professionnel. Ça ne s'arrête pas là : on parle aussi de démocratiser l'accès à l'éducation. Mais attention, il y a des pièges, comme la triche ou la protection des données. Dans cette discussion, je vais vous montrer comment je pilote ces changements et quels défis nous devons surmonter pour que l'IA devienne un allié de l'éducation.
Exploration AI: 10 ans de progrès, limites
Il y a dix ans, j'ai plongé dans l'IA, et les choses étaient bien différentes. On commençait à peine à gratter la surface de ce que l'apprentissage profond pouvait accomplir. Aujourd'hui, j'oriente des projets d'IA qui semblaient appartenir à la science-fiction à l'époque. Cette décennie a été marquée par des progrès fulgurants : des capacités historiques de l'IA aux percées récentes dans la prédiction de texte. Mais attention, malgré ces avancées incroyables, les défis persistent et les limites techniques demeurent. Dans cette exploration, je vous emmène à travers les expérimentations, les essais et les erreurs qui ont jalonné notre parcours, tout en regardant vers l'avenir de l'IA.