Jetson Spark: Exploiter sa puissance en local
J'ai plongé les mains dans le cambouis avec Jetson Spark, et croyez-moi, exécuter des modèles de langage de grande taille localement change la donne. Je vais vous montrer comment j'ai configuré mon environnement, les embûches que j'ai rencontrées, et l'impact réel sur le terrain. Avec ses 128 Go de mémoire unifiée, le Jetson Spark permet de manipuler des modèles de 200 milliards de paramètres directement sur site. Mais attention, sans une bonne gestion de la quantification et de la bande passante mémoire, vous risquez de vous brûler les ailes. En comparant le développement AI local avec les solutions cloud, je partage mes conclusions sur l'efficacité et le débit des modèles. Si vous êtes curieux de savoir comment le Jetson Spark se mesure aux solutions cloud, cet article est pour vous.
Quand j'ai commencé à expérimenter avec Jetson Spark, je ne pensais pas que ça pourrait changer à ce point ma façon de travailler avec des modèles de langage de grande taille. Vous voyez, avoir 128 Go de mémoire unifiée à disposition pour manipuler des modèles de 200 milliards de paramètres localement, c'est presque surréaliste. Mais avant de foncer tête baissée, j'ai appris à mes dépens qu'il fallait maîtriser la quantification et la bande passante mémoire. C'est là que Jetson Spark montre ses dents. Je vais vous expliquer comment j'ai configuré mon setup, les erreurs à éviter, et surtout, comment ça se compare aux solutions cloud. Je parlerai aussi de l'importance du temps au premier token pour l'expérience utilisateur. Si vous êtes dans le développement AI, vous savez que chaque microseconde compte. On va aussi discuter des cas d'usage réels et pourquoi, parfois, rester local peut être plus avantageux que d'aller dans le cloud. Alors, prêt pour un tour d'horizon pratique?
Explorer les capacités du Jetson Spark
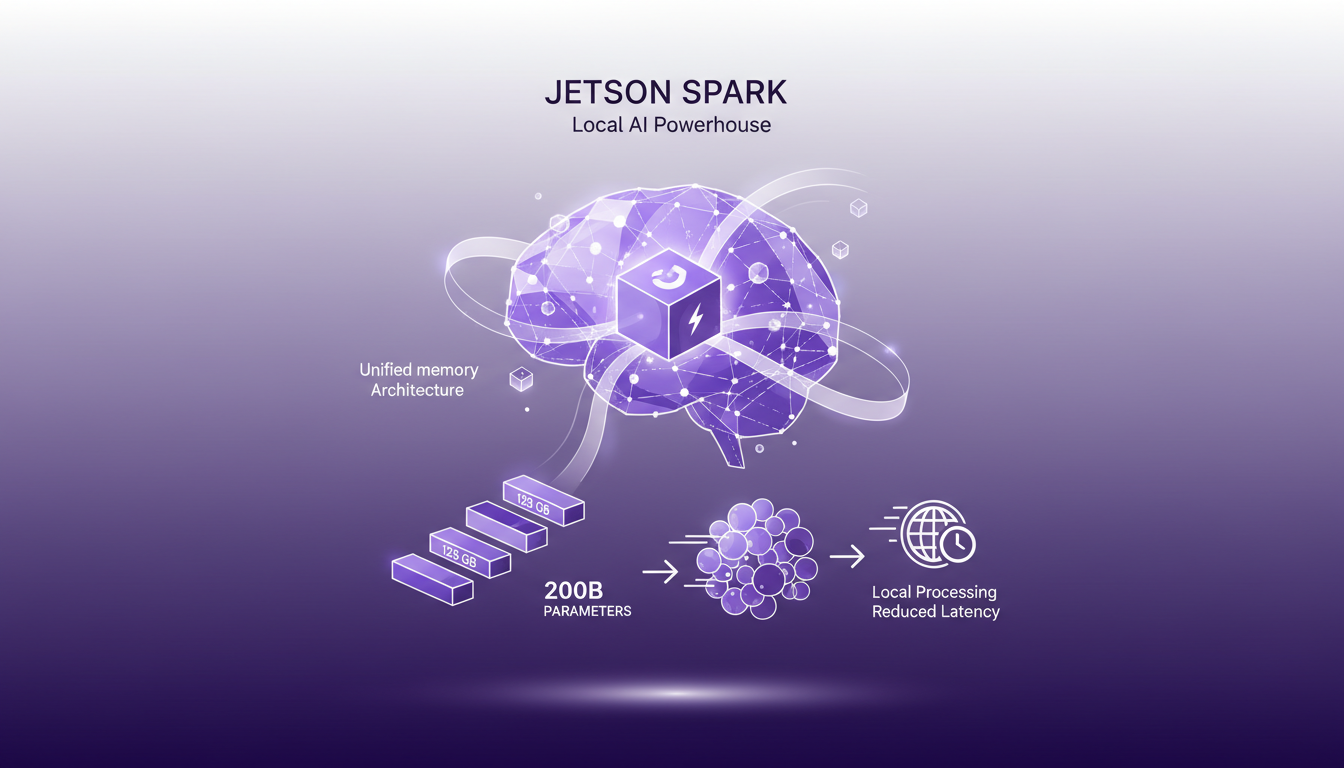
Le Jetson Spark, avec son architecture mémoire unifiée de 128 GB, est un véritable atout pour le développement d'IA en local. Vous pouvez gérer des modèles allant jusqu'à 200 milliards de paramètres sur cette configuration. C'est comme jongler avec des chiffres astronomiques sur un système qui tient sous votre bureau. En local, la réduction de la latence améliore considérablement l'expérience utilisateur. Premièrement, je me connecte à l'architecture mémoire pour tirer parti de cette puissance. Ensuite, je dois comprendre les compromis entre la capacité mémoire et la bande passante mémoire. Parfois, plus de mémoire ne signifie pas nécessairement de meilleures performances.
"Avec Jetson Spark, je gère des modèles de 200 milliards de paramètres sans transpirer."
Points clés :
- Architecture mémoire unifiée de 128 GB
- Gestion de modèles jusqu'à 200 milliards de paramètres
- Réduction de la latence grâce au traitement local
Formats de quantification : Impact sur la performance
Le format de quantification NVFB4 est crucial pour maintenir le débit sans sacrifier la qualité. J'ai observé jusqu'à 14 milliards de tokens par seconde grâce à NVFB4, ce qui est impressionnant. Quantifier, c'est réduire la taille du modèle, mais attention aux compromis en termes de précision. Pour implémenter NVFB4, je dois comprendre les besoins spécifiques de mon modèle. Cela revient à habiller sur mesure un mannequin de haute couture : chaque modèle a ses propres particularités.
Points clés :
- NVFB4 maintient le débit même avec des modèles plus grands
- Jusqu'à 14 milliards de tokens par seconde
- Comprendre les compromis en termes de précision
Temps jusqu'au premier jeton : Pourquoi est-ce important
L'expérience utilisateur dépend du temps jusqu'au premier jeton. Plus c'est rapide, mieux c'est. Le Jetson Spark excelle ici, avec un délai minimal dans la génération de jetons. Un exemple concret : j'ai réduit de moitié le temps de réponse en optimisant les paramètres. Cependant, méfiez-vous de la taille des modèles ; les modèles plus grands peuvent ralentir la réponse initiale.
Points clés :
- Temps jusqu'au premier jeton crucial pour l'expérience utilisateur
- Jetson Spark offre une réactivité exceptionnelle
- Optimisation des paramètres réduit le temps de réponse
Comparaison pratique : Débit et efficacité des modèles
En comparant les tailles de modèles, j'ai trouvé un équilibre pour le débit et l'efficacité. 1,5 milliard de tokens par seconde est réalisable avec la bonne configuration. L'équilibre entre le débit et la consommation d'énergie est essentiel pour l'efficacité. Parfois, des modèles plus petits offrent de meilleures performances dans le monde réel en raison de leur vitesse.
"Parfois, un modèle plus petit et rapide vaut mieux qu'un grand et lent."
Points clés :
- 1,5 milliard de tokens par seconde réalisable
- Équilibre entre débit et consommation d'énergie
- Modèles plus petits peuvent être plus performants
Développement IA local vs solutions cloud
Exécuter des modèles localement sur le Jetson Spark réduit la dépendance aux services cloud, réduisant ainsi les coûts. Le développement local offre plus de contrôle et de confidentialité des données. Cependant, les solutions cloud ont encore l'avantage en termes de scalabilité. Évaluez les besoins de votre projet : local pour la rapidité et le contrôle, cloud pour l'échelle.
Points clés :
- Réduction des coûts en utilisant Jetson Spark localement
- Plus de contrôle et de confidentialité des données
- Solutions cloud encore meilleures pour la scalabilité
Pour en savoir plus sur les défis de l'orchestration de l'IA, consultez Construire des agents IA chez Hex et Optimisation des modèles d'IA générative avec quantification.
Premièrement, le Jetson Spark se distingue par ses 128 Go de mémoire unifiée, ce qui est un véritable atout pour le développement de l'IA locale. On gère jusqu'à 200 milliards de paramètres de modèles sur cette machine, ce qui est impressionnant pour travailler en local. Mais attention, il y a des compromis à prendre en compte. Par exemple, le temps au premier token joue un rôle crucial dans l'expérience utilisateur, alors il faut bien optimiser. Ensuite, avec un débit de 1,5 milliard de tokens par seconde pour un modèle d'instruction à 1,5 milliard, on peut dire que l'efficacité est au rendez-vous. Mais ne vous laissez pas aveugler, la quantification peut impacter la performance du modèle, donc testez bien vos besoins spécifiques. En regardant vers l'avenir, je suis convaincu que le développement d'IA locale comme celui-ci va bouleverser notre manière de gérer les projets, en alliant efficacité et coût réduit. Je vous encourage à explorer ces capacités et à tester le Jetson Spark pour voir comment il peut s'intégrer dans vos workflows existants. Pour une compréhension plus approfondie, je vous recommande vivement de regarder la vidéo originale sur YouTube.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
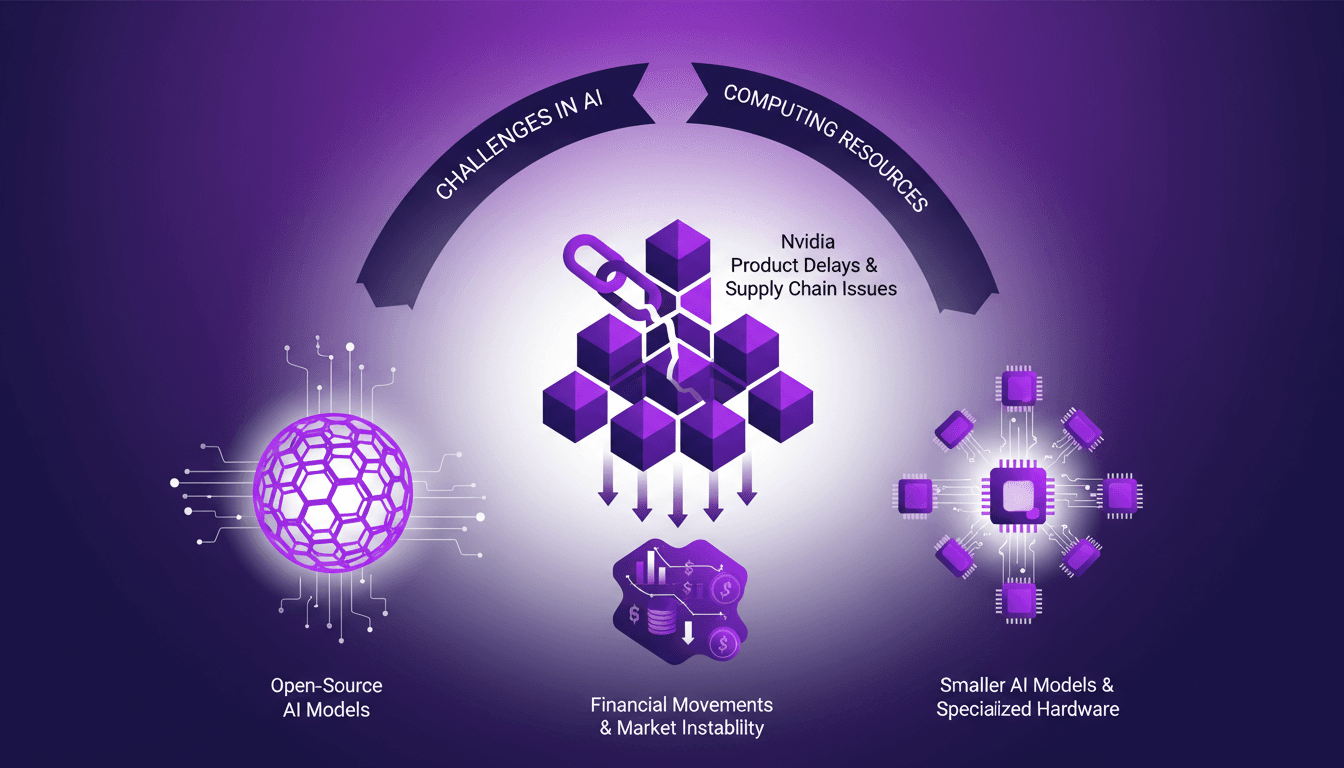
Défis Ressources IA: Nvidia, Open Source
Je me souviens de la première fois où j'ai heurté un mur avec les ressources de calcul pour l'IA. C'était comme essayer de courir un marathon sur un tapis roulant bloqué en mode marche. Dans ce paysage de l'IA en pleine évolution, nous faisons face à des défis bien réels, des retards de Nvidia à l'attrait croissant des modèles open-source. Le marché est en pleine ébullition, avec des annonces financières comme celles de Mistral qui ajoutent une couche de complexité supplémentaire. On doit naviguer à travers les pénuries de ressources, l'émergence de modèles d'IA plus petits, et les problèmes de chaîne d'approvisionnement qui affectent les délais de livraison des composants. Plongeons dans ces dynamiques avec un regard de praticien, en se concentrant sur les solutions pratiques et les compromis.
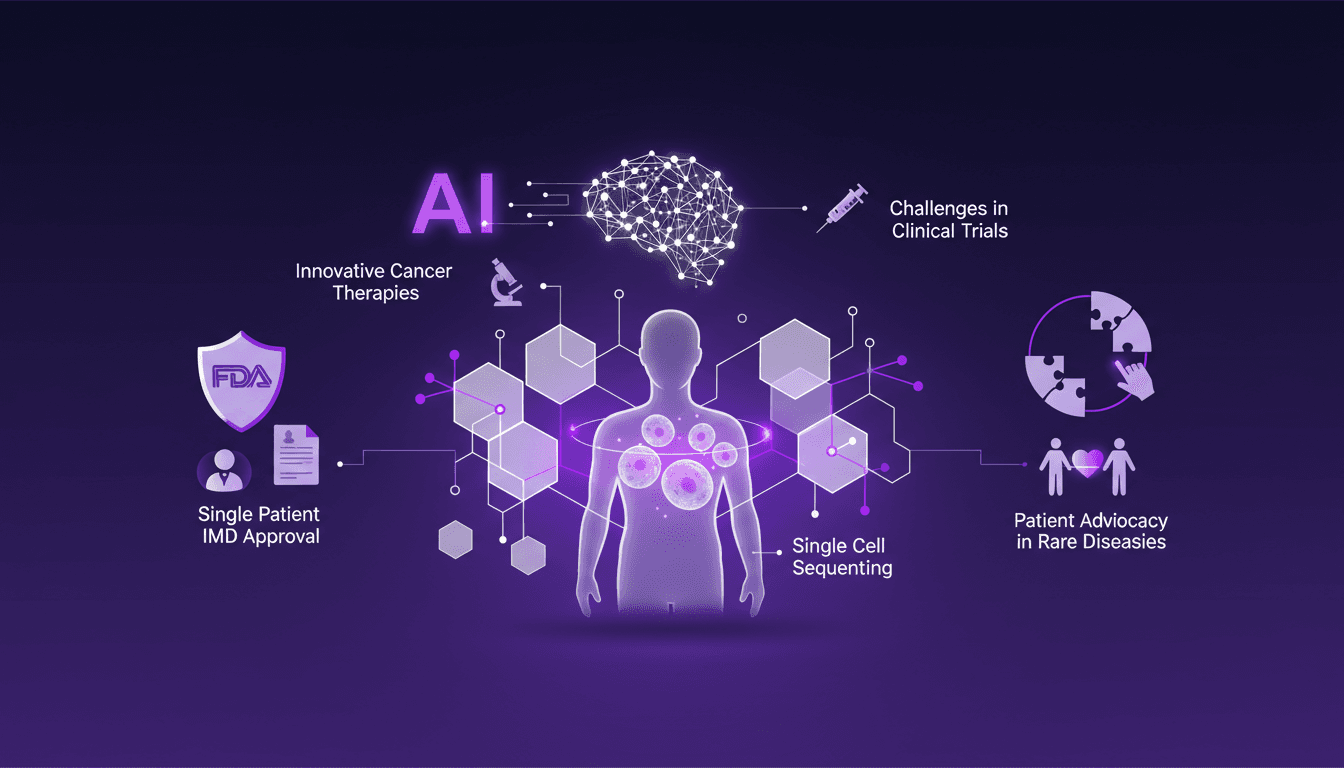
Traitement du Cancer: AI et Séquençage Cellulaire
Je me souviens du jour où Sid Severy a partagé son parcours avec nous. Ce n'était pas seulement une lutte contre le cancer; c'était une réécriture des règles avec l'IA et la technologie médicale de pointe. Imaginez utiliser l'IA et le séquençage cellulaire pour révolutionner un plan de traitement. Dans cette conférence, je vais plonger dans l'histoire de Sid, un microcosme de comment l'IA redéfinit le traitement du cancer. On parle de vaccins personnalisés à ARNm et de naviguer dans le processus d'approbation de l'IMD pour patient unique de la FDA. Accrochez-vous, c'est là où la technologie rencontre la médecine de front.

Exploration d'idées avec Codex: Efficacité Maximale
Je me souviens encore de la première fois où j'ai intégré Codex dans notre flux de travail chez Braintrust. C'était comme actionner un interrupteur sur notre processus d'innovation. Les idées, qui flottaient auparavant, se transformaient en prototypes concrets que nous pouvions tester et itérer en temps réel. Dans cet article, je vais vous montrer comment Codex a révolutionné notre manière de gérer les retours clients et d'innover. On parle d'une exploration d'idées ultra-efficace, de feedback en temps réel et d'une boucle de rétroaction raccourcie. Avec Codex, nous engageons nos clients de manière active et générons des retours de haute qualité.
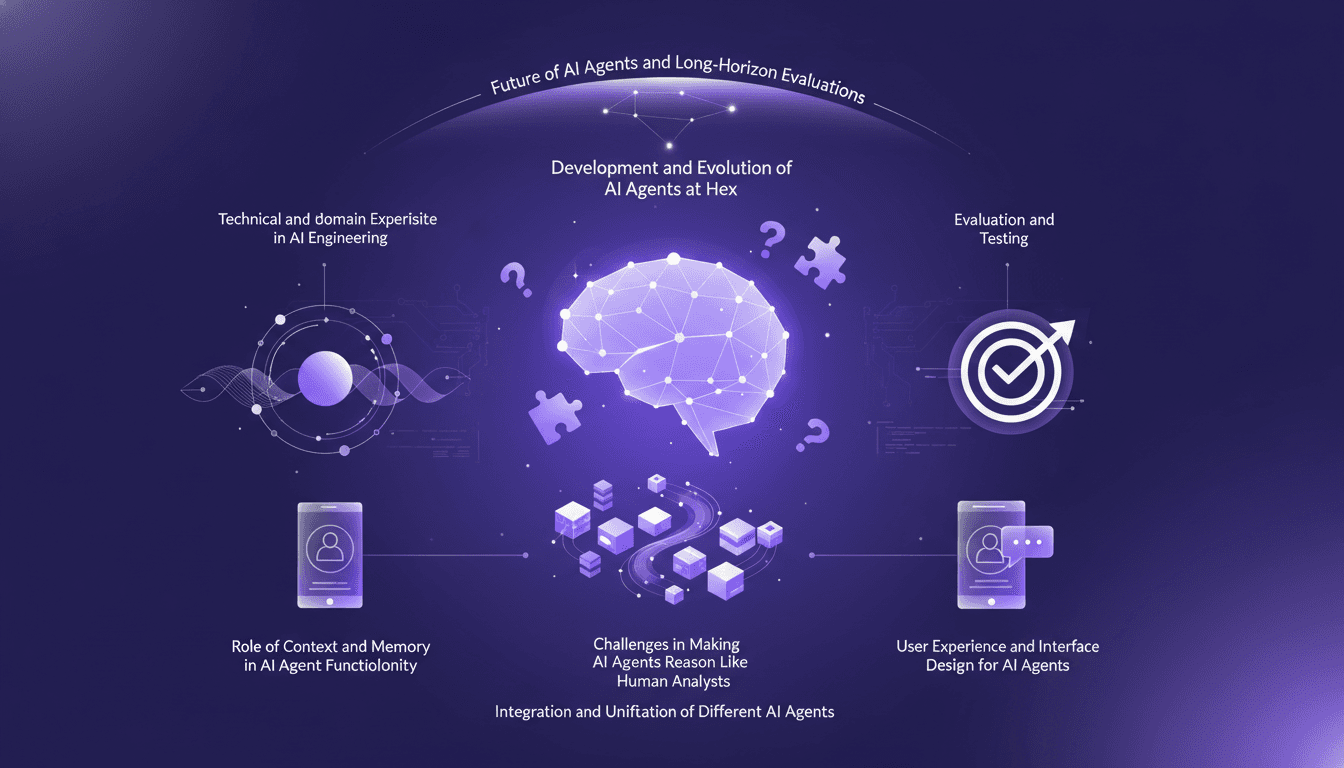
Développement d'agents IA chez Hex : Workflow
Chez Hex, j'ai passé d'innombrables heures à peaufiner nos agents IA pour qu'ils pensent comme des analystes de données humains. C'est un véritable parcours du combattant, mais chaque défi nous rapproche de notre objectif : créer des agents capables de raisonner avec précision. D'abord, je connecte les différents systèmes, puis je les teste (et me fais parfois avoir). L'intégration et l'évaluation des performances sont cruciales pour éviter les pièges comme le dépassement de contexte ou des interfaces utilisateur mal pensées. La clé, c'est l'expérience utilisateur et la mémoire contextuelle. Notre but ? Qu'à 90 jours, les agents atteignent 100% de précision. On est encore loin, mais chaque pas compte. Suivez-moi dans cette aventure où technique et pratique se rencontrent.
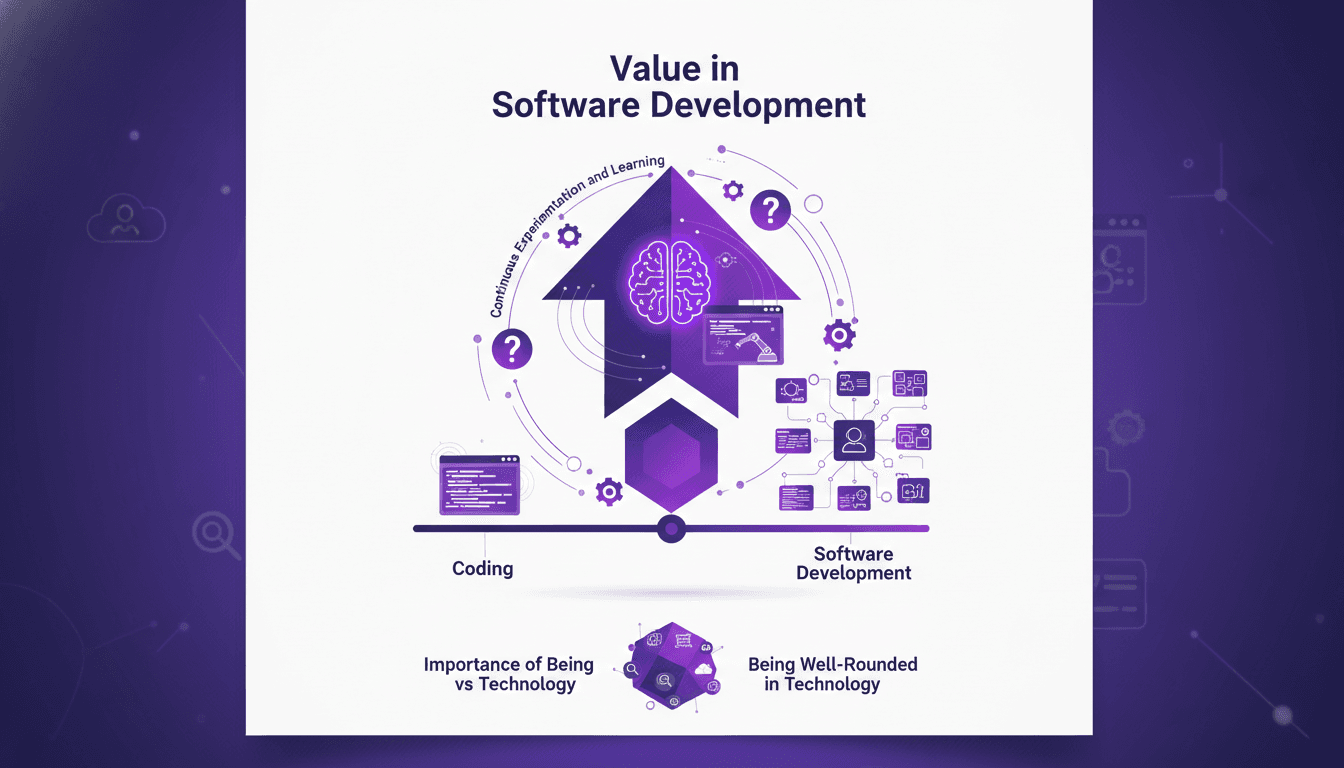
Développement logiciel : coder vite, mais à quel prix ?
Il m'est arrivé de coder à toute allure, mais au fil du temps j'ai compris que le vrai coût ne se résume pas à la vitesse de frappe. Le développement logiciel, c'est une autre paire de manches. On peut coder 55 fois plus vite, mais si on ne fait pas attention, on se retrouve vite avec des coûts qui s'envolent. Parlons du pourquoi coder est bon marché, mais le développement logiciel coûteux. On va creuser l'importance d'être polyvalent, le rôle des jeunes ingénieurs et de l'IA, et pourquoi l'expérimentation continue est essentielle. C'est dans la compréhension de la valeur au-delà des simples lignes de code que se situe la réussite des projets.