Gemma 4 : Modèles ouverts et accessibles
Je me suis plongé dans Gemma 4, le dernier bijou des modèles ouverts de Google DeepMind, et c'est comme découvrir un nouveau monde de possibilités. Avec ses modèles de 26B et 31B, on parle d'une performance qui peut changer la donne (surtout avec sa licence Apache 2.0 qui rend tout ça super accessible). Je vais vous expliquer comment j'ai exploité son architecture et pourquoi ça compte pour nous, les bâtisseurs. On va parler de l'architecture d'Oure, des capacités multimodales, de l'optimisation de la mémoire avec le PLE, et même de la puissance de traitement audio. Ne manquez pas comment ces modèles peuvent être déployés et accessibles pour tout le monde.
Je me suis plongé dans Gemma 4, le dernier modèle ouvert de Google DeepMind, et c'est comme pénétrer dans un nouveau monde de possibilités. Imaginez un modèle de 26 milliards de paramètres qui se classe parmi les six premiers modèles open source de l'arène LM. Ou optez pour le géant de 31B avec ses options hébergées dans le cloud – ce truc est sérieux. Mais ce qui m'a vraiment accroché, c'est sa licence Apache 2.0 qui rend ces modèles incroyablement accessibles pour les développeurs comme nous. L'architecture d'Oure permet une sélection experte, et ses capacités multimodales gèrent des résolutions variables comme si c'était du gâteau. N'oublions pas l'optimisation de la mémoire avec le Per Layer Embedding (PLE), qui est un must pour éviter de plonger dans les abysses de la consommation de ressources. Et pour couronner le tout, il y a des capacités de traitement audio et de traduction qui m'ont laissé bouche bée. Je vais vous montrer comment tirer parti de ces technologies pour nos projets quotidiens, sans vous perdre dans des détails inutiles.
Comprendre l'Architecture de Gemma 4
En tant que praticien, je vais vous parler de l'architecture de Gemma 4, qui a vraiment fait parler d'elle. On a deux modèles principaux : 26B et 31B. Pour commencer, le modèle 26B se classe parmi les six meilleurs de tous les modèles open-source. Ça, c'est un fait. Mais ce qui m'a vraiment surpris, c'est la manière dont le modèle 31B offre des options hébergées dans le cloud pour gérer des modèles plus volumineux. C'est là que j'ai vu une vraie différence dans la performance. J'ai trouvé que le modèle Mixture of Experts était essentiel pour optimiser la performance, surtout quand on parle des 3,9 milliards de paramètres actifs nécessaires pour le 26B. Ça peut paraître énorme, mais c'est là que se trouve la magie : activer seulement ce dont on a besoin.
Cette architecture change la donne en termes de réduction des coûts, surtout quand on compare avec des modèles plus anciens. Mais attention, cette flexibilité a un prix : il faut bien gérer les paramètres actifs pour ne pas exploser les coûts de calcul.
"Le modèle 26B utilise 3,8 milliards de paramètres actifs lors de l'inférence, ce qui offre une performance proche du modèle 31B dense à un coût d'inférence significativement plus bas."
Accessibilité pour les Développeurs avec Apache 2.0
Passons à un autre sujet crucial : l'accessibilité des modèles grâce à la licence Apache 2.0. Je dois dire que cette licence a vraiment facilité la personnalisation et le déploiement des modèles. L'open-source est un terrain fertile pour l'innovation collaborative, et je l'ai vu de mes propres yeux. Mais il faut faire attention aux compromis : ce que vous gagnez en flexibilité, vous le perdez parfois en support et mises à jour régulières. Et parfois, il est plus rapide d'intégrer un modèle existant que de construire quelque chose de zéro.
- Licence Apache 2.0 pour plus de flexibilité
- Collaboration facilitée via l'open-source
- Mise en garde : compromis sur le support
Capacités Multimodales et Résolutions Variables
Gemma 4 est également impressionnant dans sa gestion des multimodalités avec des résolutions variables. J'ai orchestré des tâches multimodales en utilisant Grouped Query Attention. Cela permet de traiter différents types de données avec une flexibilité que je qualifierais de révolutionnaire. Cependant, attention à ne pas abuser des fonctionnalités multimodales, car elles peuvent augmenter la complexité de manière exponentielle. L'efficacité du processus vient vraiment de la compréhension du workflow et de l'orchestration précise des tâches.
J'ai remarqué qu'une bonne gestion des résolutions et des budgets de tokens peut vraiment optimiser la performance pour différentes tâches. La flexibilité est là, mais il faut savoir la maîtriser.
- Traitement multimodal avec attention groupée
- Ne pas abuser des fonctionnalités multimodales
- Optimisation des résolutions et budgets de tokens
Optimisation de la Mémoire avec Per Layer Embedding
L'une des innovations que j'ai trouvées particulièrement utiles est l'optimisation de la mémoire grâce à Per Layer Embedding (PLE). J'ai intégré le PLE dans mon workflow pour améliorer l'efficacité du modèle, et les économies de mémoire sont substantielles. Mais attention, il peut y avoir des problèmes de compatibilité, surtout dans les déploiements à grande échelle. L'équilibre entre l'utilisation de la mémoire et la performance est crucial.
- PLE pour une optimisation significative de la mémoire
- Attention aux problèmes de compatibilité
- Importance de l'équilibre mémoire-performance
Traitement Audio et Traduction
Enfin, parlons des capacités impressionnantes de Gemma 4 en matière de traitement audio. Avec un conformer de 35 millions de paramètres, le modèle excelle dans ce domaine. J'ai utilisé le MEL Spectrogram pour une traduction audio précise. Les capacités audio sont robustes, mais nécessitent un réglage minutieux pour obtenir une précision de traduction optimale. Les options de déploiement varient, et il est essentiel de choisir en fonction de vos besoins spécifiques.

- Conformer de 35M pour le traitement audio
- Utilisation du spectrogramme MEL pour la traduction
- Options de déploiement variées selon les besoins
Gemma 4, c'est vraiment un moteur puissant pour nous, les bâtisseurs. Je me suis plongé dedans et j'ai vu comment son architecture et ses modèles, notamment le 26B qui se classe parmi les six meilleurs modèles open-source, peuvent transformer nos flux de travail. Voici ce que j'ai retenu :
- Le modèle 31B est idéal pour les options hébergées sur le cloud, parfait pour des projets à grande échelle.
- Avec ses 35 millions de paramètres, le conformer audio est une vraie bête pour le traitement audio.
- Grâce à la licence Apache 2.0, on a une accessibilité sans égale pour les développeurs. La prochaine étape ? Plonger dans Gemma 4 et voir comment elle peut concrètement améliorer vos projets. Attention aux limites sur l'accessibilité et les ressources nécessaires pour exploiter au mieux ces modèles. Pour en savoir plus, je vous recommande de regarder la vidéo complète 'Open Models at Google DeepMind' par Cassidy Hardin pour vraiment saisir l'essence de Gemma 4.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Agents Intelligents: Révolution en Médecine Personnalisée
J'ai vu de mes propres yeux comment les agents intelligents transforment la médecine personnalisée. On ne parle plus de théorie, mais de pratiques concrètes dans les cliniques, et les coûts chutent à une vitesse incroyable. Nous sommes à un point de bascule où la technologie et la médecine convergent. Du séquençage génomique à la livraison d'ARNm, le paysage évolue rapidement. Je vais te montrer comment cela reconfigure les soins de santé. Avec la loi de Moore, les coûts du séquençage génomique dégringolent, et les médicaments génétiques N-of-1 deviennent plus abordables que jamais. Les startups jouent un rôle clé dans cet écosystème, et même la FDA s'ouvre à des procédures personnalisées. En tant que praticien, je t'emmène dans les coulisses de ce qui se passe vraiment.
Évoluer le serveur MCP de GitHub: Leçons clés
Je me souviens de la première fois où j'ai dû faire évoluer le serveur MCP de GitHub. Une véritable épreuve, mais au fil des essais et erreurs, j'ai appris ce qui fonctionne, ce qui ne fonctionne pas, et où réside la vraie valeur. Dans cet article, je vous emmène à travers le parcours de mise à l'échelle du serveur MCP de GitHub, en mettant en lumière les défis, les optimisations, et les améliorations de sécurité qui ont vraiment fait la différence. On parlera des contributions publiques, des surcharges de contexte, de l'implémentation d'OAuth, et de l'utilisation de Redis pour mettre en place un serveur sans état. Si vous avez déjà jonglé avec plus de 100 outils mais que vous voulez réduire ça de 49%, lisez la suite. C'est un partage direct de terrain, pas une théorie abstraite.

Acheter une voiture de rêve: le vrai coût
J'ai acheté ma voiture de rêve à 200 000 $, mais ce n'était pas le tour de victoire que j'attendais. Je vous raconte comment cette obsession matérielle m'a conduit à découvrir un but plus profond. Vous pensez qu'un achat comme celui-ci va tout changer, mais la vraie aventure commence après. Je partage l'histoire de la construction et de la vente de mon entreprise, et comment j'ai trouvé un sens réel en aidant les autres à poursuivre leurs rêves. C'est une expérience qui m'a appris que le bonheur ne vient pas des possessions matérielles, mais de ce que nous aimons vraiment faire.
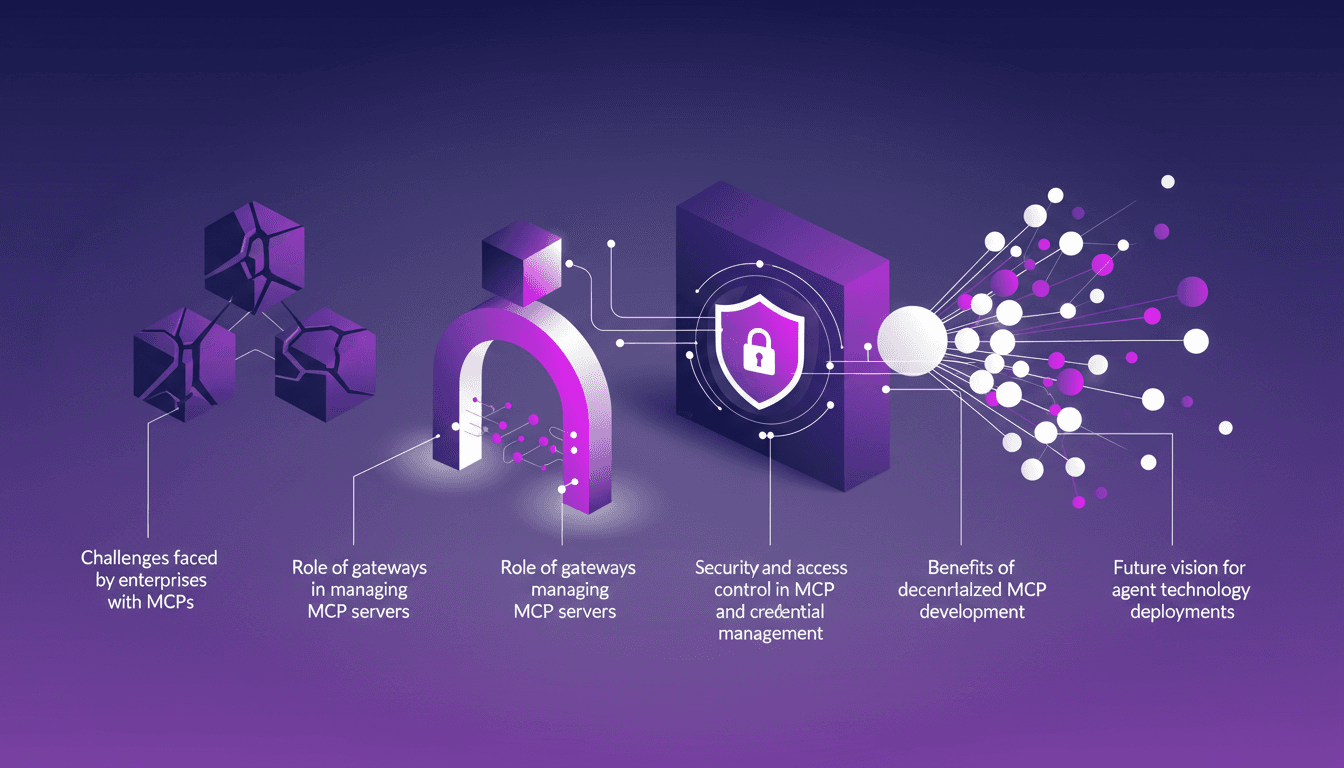
Défis des MCP en entreprise : Solutions pratiques
Je me souviens de la première fois où j'ai dû faire évoluer les serveurs MCP pour un client d'entreprise. C'était le chaos total — mais une fois que j'ai trouvé la bonne orchestration, tout s'est mis en place. Les entreprises font face à des défis uniques avec les MCP, de la scalabilité à la sécurité. Dans cet article, on va décortiquer comment aborder ces défis à l'aide de passerelles et d'autres stratégies. On parlera aussi de la sécurité et du contrôle d'accès, de l'importance de l'observabilité et de la gestion des identifiants, sans oublier la vision future pour le déploiement des technologies d'agents.

Services IA natifs : Révolution dans l'industrie
Depuis des années, je suis immergé dans le monde de l'IA, observant les outils se transformer en véritables services natifs IA. Ce n'est pas juste une tendance, c'est une révolution en marche. Avec l'avancée fulgurante des modèles d'IA, on assiste à un glissement des outils logiciels traditionnels vers des services entièrement repensés par l'IA. On parle ici de remplacer des secteurs entiers d'externalisation par des produits IA, et c'est un changement majeur. Des industries comme l'assurance et la comptabilité ressentent déjà l'impact. Je vais vous expliquer comment tout cela se déroule et pourquoi c'est un véritable game changer. Vous verrez, ce n'est pas juste du bruit médiatique, c'est concret.