Structure de Table AI: Construire Efficacement
Je suis dans les tranchées de l'IA, construisant des agents qui ne se contentent pas de traiter des données, mais qui créent leurs propres structures. Parlons de comment ces agents AI construisent leurs propres tableaux de données et pourquoi c'est un véritable game changer. Dans le monde de l'IA, créer des tableaux de données dynamiques est crucial. C'est pas juste stocker des données, c'est les rendre exploitables. Comment je fais? Je connecte mes agents à des processus Map Reduce, je crée de nouvelles colonnes pour analyser le sentiment utilisateur, et j'utilise Python pour la visualisation des données. Attention cependant, si tu oublies de bien structurer tes appels de classification, tu vas te retrouver avec un sacré bazar.
J'ai passé des heures dans les tranchées de l'IA, à construire des agents qui vont au-delà de la simple gestion des données. Ils créent leurs propres structures. Et c'est ce qui change tout. On parle souvent de stockage de données, mais moi, je veux les rendre exploitables. Comment ? Premièrement, je connecte mes agents à des processus Map Reduce, une étape clé pour optimiser l'efficacité. Ensuite, ces agents peuvent créer de nouvelles colonnes pour analyser le sentiment utilisateur - positif, négatif, ou neutre. Python joue ici un rôle majeur pour la visualisation des données. Mais attention, si tu négliges de structurer correctement tes appels de classification, tu risques de te retrouver avec un chaos de données difficile à gérer. C'est comme ça que je pilote mes agents, et crois-moi, l'impact sur le business est direct. Donc, si tu es prêt à orchestrer de manière plus efficace, plongeons ensemble dans les structures de tables AI.
Comprendre la Structure des Tables dans les Agents IA
Quand je construis des agents IA, la structure des tables devient vite un pilier fondamental. Pourquoi ? Parce qu'une table bien conçue permet une efficacité redoutable de l'IA. Chaque ligne représente une réponse, et chaque colonne, une question ou une caractéristique. Je personnalise souvent ces colonnes pour répondre aux besoins spécifiques de l'IA.

Les tables de données dynamiques jouent un rôle crucial dans le traitement par l'IA. Elles s'ajustent en fonction des nouvelles données, ce qui est un atout majeur. Cependant, il y a des compromis à faire entre les tables statiques et dynamiques. Les tables dynamiques gagnent en flexibilité, mais attention au coût en termes de performance quand elles deviennent trop complexes. J'ai appris à mes dépens que ça peut ralentir l'ensemble du système.
Créer de Nouvelles Colonnes pour le Sentiment Utilisateur
Ajouter des colonnes pour l'analyse de sentiment est une étape que je fais souvent. D'abord, je définis les catégories de valeurs : positif, négatif, neutre. Cela permet à l'IA de prendre de meilleures décisions en comprenant le sentiment de l'utilisateur.
Mais, attention aux pièges ! Les biais de données et les mauvaises interprétations peuvent fausser les résultats. Parfois, il faut équilibrer le niveau de détail avec la rapidité de traitement des données. J'ai eu des surprises en découvrant des biais cachés dans les données.
Visualisation des Données avec Python : Des Tables aux Graphiques
Python est mon outil de prédilection pour la visualisation des données. Transformer des données tabulaires en informations exploitables est essentiel. Les bibliothèques Python offrent des outils puissants pour cela.

Cependant, il y a des erreurs à éviter. Une mauvaise visualisation peut tromper. J'ai appris à utiliser les bibliothèques comme matplotlib et seaborn pour éviter ces pièges et améliorer la prise de décision grâce à des données visuelles claires.
Exploiter les Sous-Agents pour la Classification
Les sous-agents sont une arme secrète pour améliorer les tâches de classification. Ils sont intégrés dans le flux de travail principal de l'IA et ajoutent de la valeur en classifiant efficacement les données.
Mais attention, il ne faut pas compliquer leur intégration. J'ai vu des projets échouer à cause de sous-agents trop complexes. Trouver l'équilibre entre complexité et fonctionnalité est crucial.
Le Processus Map Reduce en IA : Un Guide Pratique
Démystifions le processus Map Reduce pour l'IA. C'est un outil puissant pour gérer des données à grande échelle. D'abord, on segmente les données, puis on les traite par lots avant de les réduire pour obtenir des résultats exploitables.
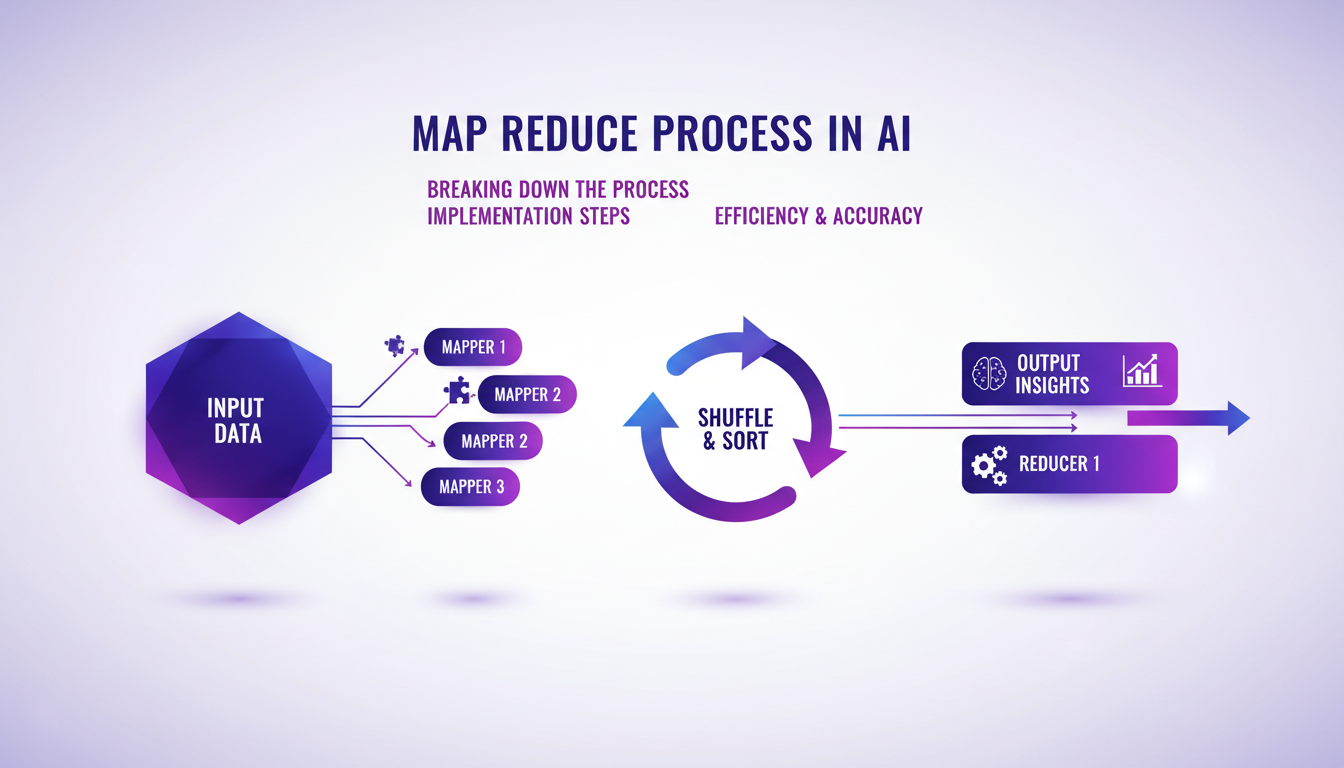
Le défi est de maintenir un équilibre entre efficacité et précision. J'ai rencontré des obstacles, mais les ai surmontés en ajustant les paramètres de traitement. Le Map Reduce est essentiel pour les projets de données volumineuses, réduisant le temps de traitement de manière significative.
Construire des agents IA capables de structurer leurs propres tables de données change vraiment la donne. Premièrement, j'utilise Python pour visualiser les données, ce qui me permet de voir rapidement les tendances et d'ajuster mes actions. Ensuite, je configure les agents pour qu'ils créent de nouvelles colonnes, ce qui optimise l'analyse des sentiments des utilisateurs — positif, négatif, neutre. Mais attention, il faut garder un œil sur la charge de traitement et la complexité des données, sinon on se perd.
• Structure automatique des tables : gain de temps impressionnant • Colonnes nouvelles : ajustement dynamique des données • Analyse des sentiments : catégorisation utile pour le feedback utilisateur
L'avenir ? Je dirais que ces pratiques vont transformer nos workflows d'IA, mais il faut rester vigilant aux limites de performance.
Prêt à optimiser vos workflows IA ? Regardez la vidéo complète pour plonger plus profondément dans ces pratiques. Je vous garantis que cela vaut le détour.
Lien vidéo : YouTube
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
Agents IA pour l'analyse : défis et solutions
Quand je dis que j’ai passé des heures à orchestrer des agents IA pour l'analyse de données, c'est du vécu. Les agents génériques, c'est bien joli dans les démos, mais dans la vraie vie, on doit jongler avec des architectures robustes, l'intégration du feedback utilisateur et bien plus encore. Prenez par exemple, le défi de lancer 500 agents pour un outil spécifique – c'est un casse-tête. En plus, un seul run d'analyse peut facilement prendre 30 minutes et, croyez-moi, ces minutes s'accumulent vite. Je vous partage mes solutions, mes erreurs, et ce qui fonctionne vraiment.
GPT 5.5 : Construire avec Codex, Éliminer Tiers
J'ai plongé tête première dans GPT 5.5, et quelle aventure ! De la construction d'un logiciel de podcast à l'élimination des fournisseurs tiers, cette version a changé la donne pour moi. Avec GPT 5.5, on ne parle pas simplement de mises à jour. On parle d'un tout nouveau niveau de confiance et de capacité. D'abord, j'ai intégré Codex pour développer une application de podcast et j'ai coupé les intermédiaires. Ensuite, les bugs ? GPT 5.5 les détecte comme un pro. Vous en avez marre des solutions tierces qui plombent votre productivité ? Cet outil pourrait bien être votre nouvelle arme secrète. Abordons ensemble les applications concrètes.
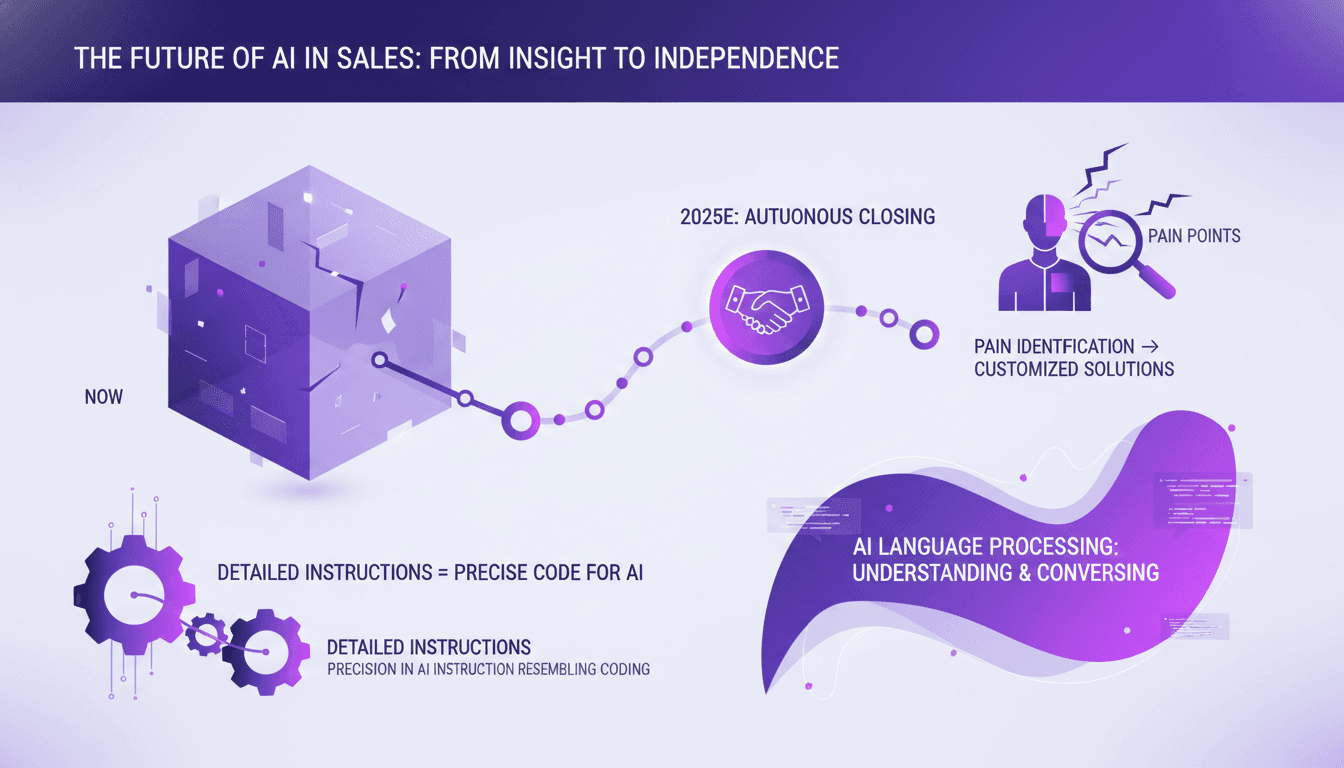
IA en Vente: Détruire les Mensonges avec Claude
J'ai passé des heures à essayer de faire en sorte que l'IA finalise des ventes pour moi, et croyez-moi, on n'y est pas encore. Mais j'ai découvert ce qu'elle peut faire maintenant et comment l'utiliser efficacement. Dans le monde de la vente, l'IA est l'outil brillant dont tout le monde parle. Pourtant, elle ne peut pas encore conclure un accord toute seule. Ce qu'elle peut faire, c'est transformer notre approche de la formation et de l'exécution des ventes, surtout pour identifier et répondre aux points de douleur des clients. Nous sommes peut-être à cinq ans d'une IA qui peut conclure une vente, mais en utilisant les bonnes instructions, elle peut déjà recommander 80 % des solutions basées sur l'identification des douleurs. Suivez-moi, et je vous explique comment orchestrer cela pour un impact direct.

Configurer GStack : Mon expérience avec Claude Code
J'ai plongé tête la première dans GStack avec Claude Code, et croyez-moi, la façon dont Garry Tan orchestre son workflow est impressionnante. De ses marathons de codage à l'utilisation stratégique des heures de bureau pour affiner les idées de startups, il y a beaucoup à décortiquer. GStack est un mastodonte de l'automatisation dans le développement logiciel, et Garry l'a amené à un niveau supérieur. Dans cet article, on plonge dans ses outils, ses méthodes, et les leçons qu'on peut en tirer. On va explorer comment il utilise GStack pour l'automatisation, ses sessions parallèles de code cloud, et comment il intègre l'IA dans son processus. Mais attention, il y a aussi des préoccupations de sécurité à ne pas négliger.
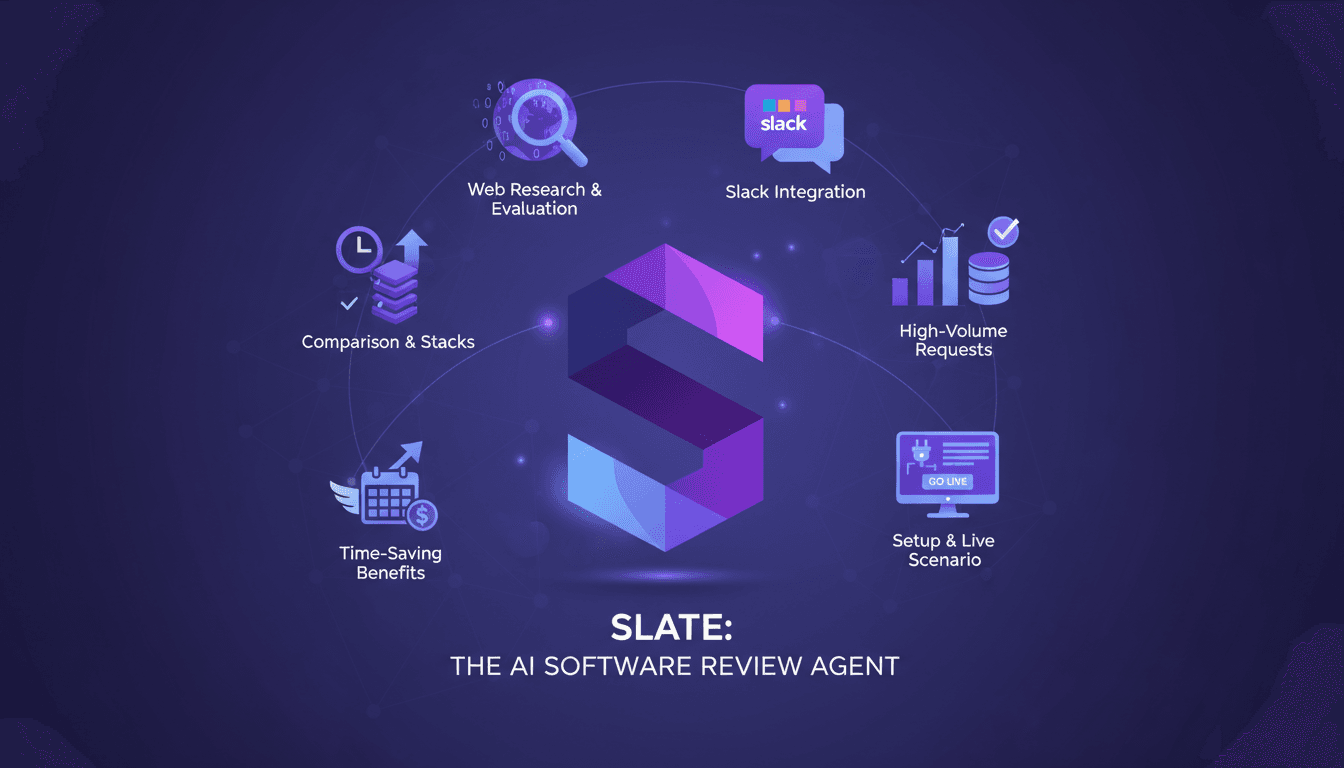
Slate : Agent de Revue Logicielle en Action
J'ai passé des années à jongler avec les demandes interminables de logiciels en tant que responsable des achats IT, essayant désespérément de satisfaire tout le monde. Puis, j'ai découvert Slate, un agent de revue logicielle, et ça a été un vrai tournant. Slate ne se contente pas de faire de la recherche web, il évalue les logiciels selon nos stacks approuvées. Et la cerise sur le gâteau ? Son intégration fluide avec Slack, ce qui en fait un outil puissant pour les équipes IT et d'approvisionnement. Dans cet article, je vous explique comment j'ai configuré Slate et comment il a révolutionné notre gestion des demandes, surtout lors des périodes de forte affluence. Économie de temps, réduction du stress : je vous partage mon expérience.