Limites des Modèles IA: Ce Qui Ne Fait Pas le Job
Plongé jusqu'au cou dans les modèles IA, j'ai testé et retesté — et croyez-moi, il reste encore beaucoup de choses qu'ils ne peuvent pas gérer. Je me suis souvent brûlé les ailes par excès de confiance, pensant que les modèles allaient tout comprendre. Mais entre les benchmarks 'Busher' et le système de vote d'Arena, j'ai vu où ils brillent et où ils trébuchent. On va disséquer ces limites ensemble et comprendre le véritable paysage de performance. Des modèles cloud récents aux anciens comme GPT et Gemini, il y a des tendances claires et des domaines spécifiques, comme le gaming, où les performances sont encore loin d'être parfaites. Prêt à voir au-delà du battage médiatique? Allons-y !

J'ai passé des heures à plonger dans les modèles IA, les tester, les retester, et franchement, il y a encore pas mal de choses qu'ils ne maîtrisent pas. J'ai souvent pensé qu'ils allaient tout gérer, mais je me suis fait avoir plus d'une fois. Entre le benchmark 'Busher' et le système de vote d'Arena, j'ai pu observer où ces modèles excellent et où ils trébuchent lamentablement. On va passer au crible ces limitations, ensemble, pour comprendre le véritable paysage de la performance. Les modèles cloud récents par rapport aux anciens comme GPT et Gemini, c'est un duel permanent, et parfois, ils se laissent encore berner par des questions absurdes. Et puis il y a ces domaines spécifiques, le gaming par exemple, où les performances laissent à désirer. Alors, si on passait au-delà du battage médiatique et qu'on regardait les choses en face ?
Comprendre le 'Busher Benchmark'
J'ai plongé dans le 'Busher benchmark', et croyez-moi, ce n'est pas juste un mot à la mode. C'est un véritable test décisif pour les capacités de l'IA. Avec 155 questions, il couvre un large spectre, mais attention à ses angles morts. Par exemple, lorsque j'ai testé plusieurs modèles récents, j'ai découvert que certains d'entre eux avaient une tendance troublante à accepter des questions absurdes sans broncher.
Ce benchmark révèle beaucoup sur le raisonnement des modèles et leur tendance à suivre des questions absurdes. Il est surprenant de constater que même les modèles récents, qui devraient être plus avancés, vacillent souvent face à ces questions. C'est là que l'on voit vraiment la différence entre un modèle qui se contente de régurgiter des informations et un autre qui sait les interpréter intelligemment.
"Le benchmark Busher est une vraie révélation pour comprendre les limites des modèles d'IA."
En fin de compte, le 'Busher benchmark' n'est pas seulement un outil de mesure, c'est une fenêtre sur la façon dont les modèles IA gèrent les informations absurdes. Cela met en lumière des lacunes cruciales, même dans les modèles que nous considérons comme avancés.
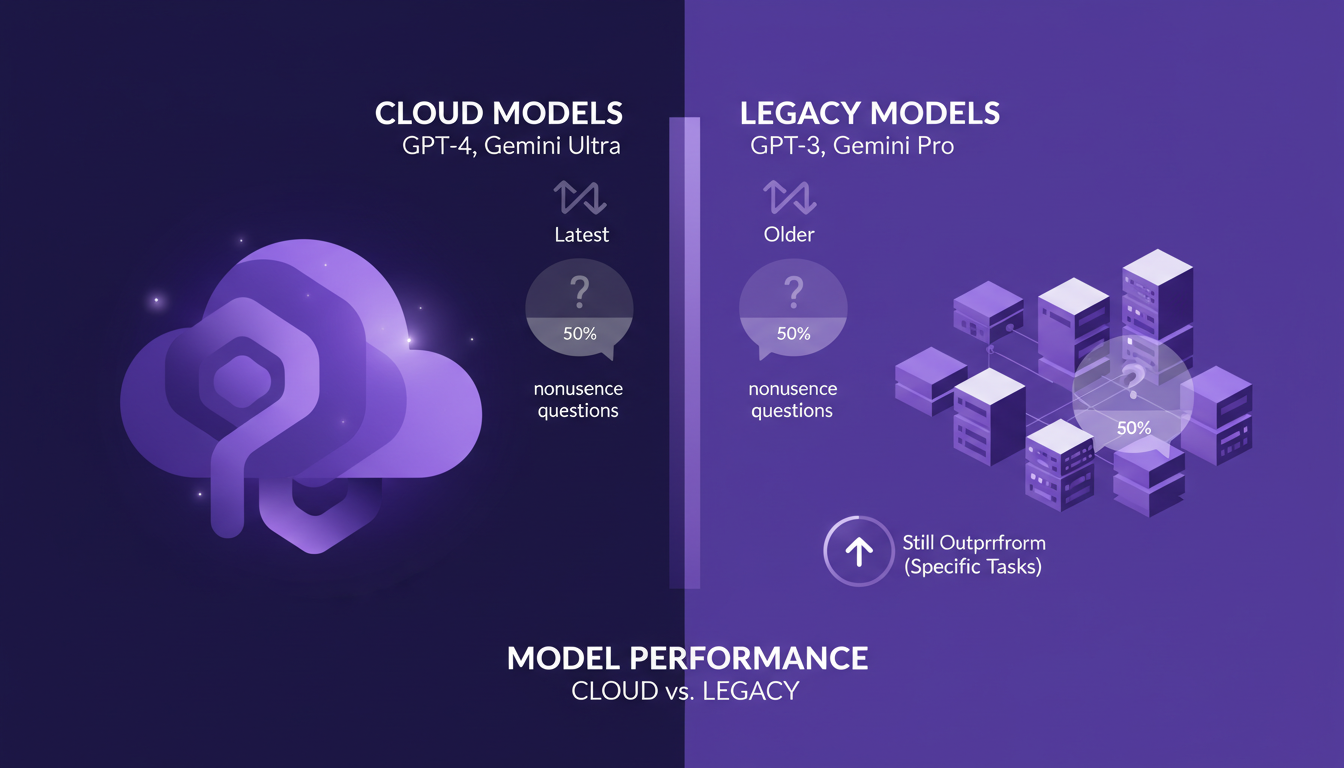
Performance des Modèles : Cloud vs Legacy
Quand je compare les derniers modèles cloud aux anciens comme GPT et Gemini, je suis frappé par une tendance : un partage 50/50 sur leur capacité à gérer les questions absurdes. Les modèles cloud récents semblent mieux résister à l'absurde, mais attention, ce n'est pas toujours le cas. Parfois, les modèles plus anciens comme GPT peuvent surprendre par leur performance dans certains domaines spécifiques.
Les nouveaux modèles offrent souvent des fonctionnalités impressionnantes, mais il y a un compromis entre ces nouvelles fonctionnalités et la cohérence. Par exemple, dans les tests, j'ai remarqué que certains modèles plus anciens surpassent encore les plus récents dans des tâches spécifiques, en particulier lorsque la précision est plus importante que la nouveauté.
- Les modèles cloud récents : tendance à mieux résister à l'absurde.
- Modèles GPT et Gemini : 50/50 sur les questions absurdes.
- Compromis entre nouvelles fonctionnalités et cohérence.
Il est essentiel de garder à l'esprit ces trade-offs lorsque l'on choisit un modèle pour des applications spécifiques. Les performances améliorées des modèles cloud ne compensent pas toujours la fiabilité éprouvée des anciens modèles dans tous les contextes.
Modèles Anthropic : Évolution et Perspectives
Depuis Claude 4.5, j'ai observé des améliorations significatives dans les modèles Anthropic. Le raisonnement a joué un rôle crucial dans ces améliorations. En suivant 700 modèles, j'ai vu des tendances émerger, et bien que les modèles Anthropic aient montré des avancées, il y a encore des limites.
Les améliorations constatées ne signifient pas que tout est parfait. J'ai remarqué que même avec un raisonnement accru, certains modèles ne performent pas nécessairement mieux. C'est un rappel que l'intelligence artificielle ne se résume pas à plus de raisonnement, mais à sa bonne application.
- Claude 4.5 : progrès significatifs depuis son lancement.
- 700 modèles suivis : tendances et insights.
- Raisonnement augmenté : pas toujours synonyme de meilleure performance.
Ces insights sont cruciaux pour comprendre où et comment déployer efficacement ces modèles dans des applications réelles.
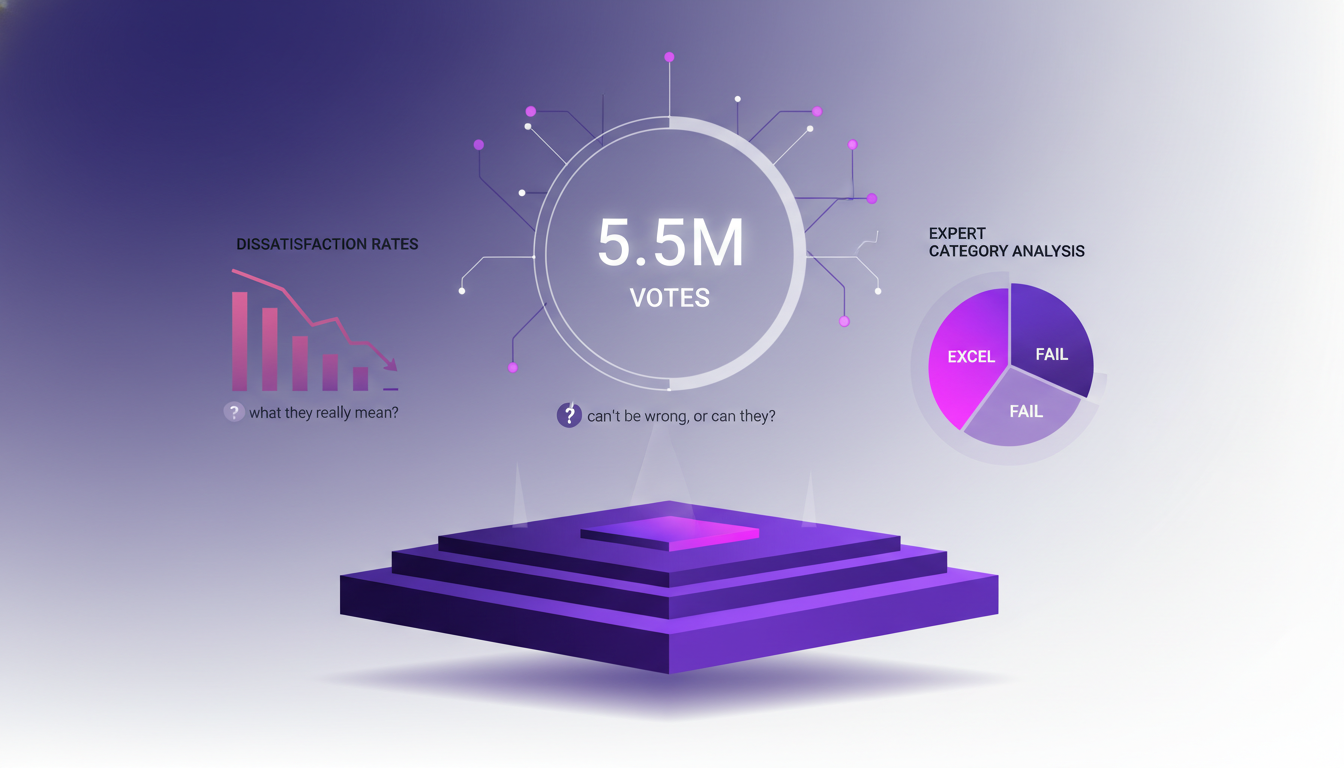
Plateforme Arena : Système de Vote et Analyse
Le système de vote d'Arena, avec ses 5,5 millions de votes, ne peut pas se tromper, non ? Eh bien, pas si vite. Quand j'ai plongé dans les taux de mécontentement, j'ai découvert qu'il y avait des nuances. Le taux de mécontentement a baissé de 20 % en 2017 à 9 % aujourd'hui, ce qui montre une amélioration, mais il y a des domaines où les modèles échouent encore.
L'analyse des catégories d'experts révèle que certains modèles excellent dans des domaines spécifiques, tandis que d'autres échouent lamentablement. Cela me rappelle que même avec des millions de votes, il faut toujours analyser de manière critique les résultats.
- 5,5 millions de votes : beaucoup, mais pas à l'abri d'erreurs.
- Taux de mécontentement : de 20 % à 9 %.
- Analyse des catégories d'experts : points forts et faibles des modèles.
Ces analyses sont essentielles pour comprendre où les modèles brillent et où ils trébuchent, influençant ainsi les décisions futures sur leur usage.
Défis dans des Domaines Spécifiques : Gaming et Au-delà
J'ai exploré la performance de l'IA dans le gaming, et c'est toujours un casse-tête. Les modèles d'IA peinent à surpasser les humains dans des jeux complexes. Cela met en lumière des défis spécifiques dans des domaines de niche. Par exemple, dans le gaming, où les décisions sont souvent multidimensionnelles et rapides, les IA ont du mal à suivre le rythme.

Les déploiements d'IA dans des domaines spécifiques nécessitent un équilibre délicat entre innovation et application pratique. J'ai remarqué des pièges communs, comme la surévaluation des capacités de l'IA ou l'ignorance de ses limitations.
- Performance dans le gaming : défis persistants.
- Défis spécifiques dans des domaines de niche.
- Pièges courants : surévaluation des capacités de l'IA.
En fin de compte, pour réussir dans des déploiements d'IA de niche, il faut non seulement innover, mais aussi comprendre profondément les limitations et les capacités actuelles des modèles.
Alors, j'ai plongé dans le monde des modèles d'IA, et voici ce que j'en retire :
- J'ai suivi 700 modèles, et malgré leurs avancées, ils ne sont pas infaillibles. Comprendre leurs limites, c'est crucial pour mieux les déployer.
- Le benchmark 'Busher' avec ses 155 questions montre que même les modèles GPT et Gemini tombent dans le piège des questions absurdes à environ 50% du temps. Alors, il faut vraiment garder un œil critique.
- Les modèles d'Anthropic ont fait des progrès notables avec le temps, mais attention : la logique reste un défi majeur pour tous ces modèles. Un regard vers l'avenir ? Je dirais qu'on est à un tournant—les modèles continuent de s'améliorer, mais c'est en restant informé et en testant constamment qu'on les poussera à leur plein potentiel. Regardez la vidéo de Peter Gostev sur Arena.ai pour approfondir, c'est un must si vous voulez vraiment comprendre ce qui cloche encore chez ces modèles.
Questions Fréquentes

Thibault Le Balier
Co-fondateur & CTO
Issu de l'écosystème startup tech, Thibault a développé une expertise en architecture de solutions IA qu'il met aujourd'hui au service de grands groupes (Atos, BNP Paribas, beta.gouv). Il intervient sur deux axes : la maîtrise des déploiements IA (LLM locaux, sécurisation MCP) et l'optimisation des coûts d'inférence (offloading, compression, gestion des tokens).
Articles liés
Découvrez d'autres articles sur des sujets similaires
GPT-5.5 : Impressions de Claire Vo
Je me souviens encore de la première fois où j'ai plongé dans GPT-5.5. C'était comme ouvrir une boîte à outils avec un nouvel outil plus affûté, prêt à redéfinir ma façon de gérer les tâches de codage. Claire Vo partage ses premières impressions de ce modèle qui semble repousser les limites de l'IA dans le développement logiciel. De l'exécution autonome du code à la correction des bugs, il y a beaucoup à explorer. Et avec une précision de 98% dans la correction des bugs, ce n'est pas une promesse vide. Dans cette interview, Claire nous guide à travers ses découvertes et compare GPT-5.5 aux modèles précédents, tout en évaluant son impact potentiel sur le processus de développement logiciel.
Alibaba IA Open Source: Révolution ou Risque?
Je viens de passer une semaine intense à explorer les avancées récentes de l'IA, et croyez-moi, le modèle open source d'Alibaba est en train de bouleverser la donne. Ce n'est pas seulement Alibaba qui fait des vagues; de Cloud Opus 4.7 aux modèles 3D interactifs, le paysage de l'IA évolue plus vite que jamais. Avec des géants comme Google et OpenAI qui intensifient également leurs efforts, que vous soyez développeur, data scientist ou simplement passionné d'IA, ces changements méritent toute votre attention. Imaginez un instant : des modèles capables de générer des mondes interactifs en 3D en temps réel ! Le contraste entre l'open source et les modèles propriétaires devient de plus en plus pertinent. J'ai parcouru ces nouveautés avec l'enthousiasme d'un enfant dans un magasin de bonbons, mais attention, il y a des pièges à éviter.
Gestion des bots : défis et solutions pratiques
J'ai passé des années à jongler avec les bots sur X, et je vous le dis, c'est loin d'être simple. On parle de six ans de travail réduits à néant par une suspension injuste à cause de l'anti-bot, et c'est seulement la partie émergée de l'iceberg. Avec l'essor de l'IA, les usurpations d'identité vocales deviennent un cauchemar, et je vois chaque jour des outils comme Open Close bouleverser notre manière de créer du contenu. L'audience organique des médias s'effondre, la sécurité internet se transforme... Si vous êtes comme moi, un bâtisseur face à ces défis, restez avec moi. Je partage des stratégies concrètes pour maîtriser l'IA et transformer ces obstacles en opportunités.
GPT 5.5 : Révolutionner le Code et Flux
Je suis dans les tranchées de l'IA depuis des années, mais GPT 5.5, c'est un vrai bouleversement. J'ai connecté mes flux de travail habituels, refactorisé du code, et même construit des graphes de connaissances plus efficacement qu'avant. Ce modèle ne se contente pas d'améliorations incrémentales; il redéfinit la façon dont l'IA peut résoudre des problèmes complexes. Avec une amélioration de la vitesse des expériences d'un facteur 10, je peux orchestrer des projets entiers de bout en bout sans me soucier de l'infrastructure de machine learning. Si vous avez déjà été frustré par les limites des modèles précédents, c'est le moment de vous plonger dans GPT 5.5.
Tech Stack: Construire une app à 25K$/mois
Je me souviens encore du moment où j'ai réalisé que mon application de minuterie générait 25K$/mois. Pas un rêve, une réalité. Je vais vous dévoiler le stack technologique qui a rendu cela possible. Dans cet article, je décortique les outils, les coûts et les stratégies qui propulsent mon appli, en mettant l'accent sur l'efficacité et la gestion des coûts. Vous découvrirez comment Air Table devient un CRM incontournable, comment Postmark gère nos communications par email, et pourquoi optimiser votre environnement de développement peut faire toute la différence. On parle de chiffres concrets : 280$ pour les serveurs, 250$ pour les outils, et 1,400$ en publicités. Pas de théories abstraites ici, juste du concret pour ceux qui veulent bâtir quelque chose de rentable.